

Integral Ad Science Earns Prestigious Webby Finalist Nomination for its Generative AI Innovation, IAS Agent - Morningstar
<a href="https://news.google.com/rss/articles/CBMi_AFBVV95cUxNeklzOFpGQTNKQlY3U212a013SXg0cWwyZG5aTGVXSEFIZkhHQzVSLVh2bHpiMVRDS0xPdlllU1pRTmV6SW16cnVWMGhvanVCVWFNbWhyMmgzU21rRW5kVC0yNGtHb1cyT013N3F5bEg3LWZJbXNuU25pdjU0THVTME8tUGNsZGh6eEpBaWgzOGE3MTFxR3BIUHFQTk54QmJQUWZyS053UTNzSXZFN25vV0ppSTdad01QU0NIUWF0M2x0UlQzRThRQ2NrcHU4M1VSYm1oNXZ3Y2E0NnZJeTFuZzFSSFpGWDdlTzFOaWhrWF9iLXJ1RzU4ZmhlZ2s?oc=5" target="_blank">Integral Ad Science Earns Prestigious Webby Finalist Nomination for its Generative AI Innovation, IAS Agent</a> <font color="#6f6f6f">Morningstar</font>
Could not retrieve the full article text.
Read on Google News: Generative AI →Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
agent![[llama.cpp] 3.1x Q8_0 speedup on Intel Arc GPUs - reorder optimization fix (PR submitted)](https://d2xsxph8kpxj0f.cloudfront.net/310419663032563854/konzwo8nGf8Z4uZsMefwMr/default-img-neural-network-P6fqXULWLNUwjuxqUZnB3T.webp)
[llama.cpp] 3.1x Q8_0 speedup on Intel Arc GPUs - reorder optimization fix (PR submitted)
TL;DR : Q8_0 quantization on Intel Xe2 (Battlemage/Arc B-series) GPUs was achieving only 21% of theoretical memory bandwidth. My AI Agent and I found the root cause and submitted a fix that brings it to 66% - a 3.1x speedup in token generation. The problem : On Intel Arc Pro B70, Q8_0 models ran at 4.88 t/s while Q4_K_M ran at 20.56 t/s; a 4x gap that shouldn't exist since Q8_0 only has 1.7x more data. After ruling out VRAM pressure, drivers, and backend issues, we traced it to the SYCL kernel dispatch path. Root cause : llama.cpp's SYCL backend has a "reorder" optimization that separates quantization scale factors from weight data for coalesced GPU memory access. This was implemented for Q4_0, Q4_K, and Q6_K - but Q8_0 was never added. Q8_0's 34-byte blocks (not power-of-2) make the non-r

Qwen3.5-397B is shockingly useful at Q2
Quick specs, this is a workstation that was morphed into something LocalLLaMa friendly over time: 3950x 96GB DDR4 (dual channel, running at 3000mhz) w6800 + Rx6800 (48GB of VRAM at ~512GB/s) most tests done with ~20k context; kv-cache at q8_0 llama cpp main branch with ROCM The model used was the UD_IQ2_M weights from Unsloth which is ~122GB on disk . I have not had success with Q2 levels of quantization since Qwen3-235B - so I was assuming that this test would be a throwaway like all of my recent tests, but it turns out it's REALLY good and somewhat usable. For Performance: , after allowing it to warm up (like 2-3 minutes of token gen) I'm getting: ~11 tokens/second token-gen ~43 tokens/second prompt-processing for shorter prompts and about 120t/s longer prompts (I did not record PP speed

Gemma 4 26b A3B is mindblowingly good , if configured right
Last few days ive been trying different models and quants on my rtx 3090 LM studio , but every single one always glitches the tool calling , infinite loop that doesnt stop. But i really liked the model because it is rly fast , like 80-110 tokens a second , even on high contex it still maintains very high speeds. I had great success with tool calling in qwen3.5 moe model , but the issue i had with qwen models is that there is some kind of bug in win11 and LM studio that makes the prompt caching not work so when the convo hits 30-40k contex , it is so slow at processing prompts it just kills my will to work with it. Gemma 4 is different , it is much better supported on the ollama cpp and the caching works flawlesly , im using flash attention + q4 quants , with this i can push it to literally
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Generative UI
Researchers train living rat neurons to perform real-time AI computations — experiments could pave the way for new brain-machine interfaces - Tom's Hardware
Researchers train living rat neurons to perform real-time AI computations — experiments could pave the way for new brain-machine interfaces Tom's Hardware
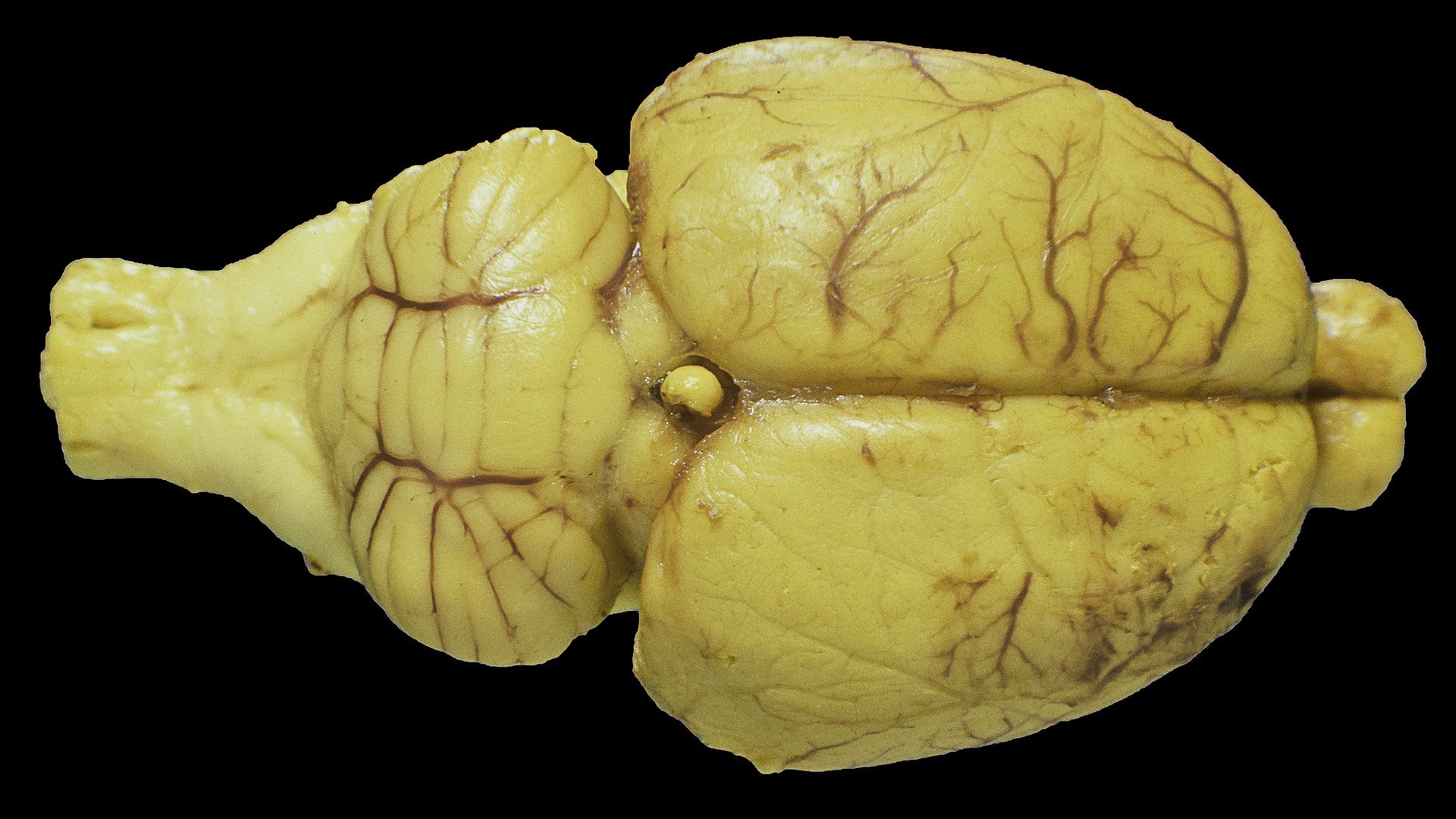
Researchers train living rat neurons to perform real-time AI computations — experiments could pave the way for new brain-machine interfaces
Researchers train living rat neurons to perform real-time AI computations — experiments could pave the way for new brain-machine interfaces

I Built a GitHub-Style Contribution Calendar That Shows When My AI Works Without Me
GitHub's contribution calendar shows when you coded. But what if half those green squares weren't actually you? I built cc-calendar — a terminal tool that renders a GitHub-style activity graph for your Claude Code sessions. Two rows: YOU (cyan) and AI (yellow). Ghost Days — when AI ran autonomously while you had zero interactive sessions — glow bright. The output $ npx cc-calendar cc-calendar — AI草カレンダー ══════════════════════════════════════════════════ Jan Feb Mar Sun ░░░░░▒░░░ Sun ░▒▒▒▓█▓█▒ Mon ░░░░░░░░░ Mon ░▒▒▒▓██▓░ Tue ░░░░░▒░░░ Tue ░▒▒▒▒▓▓▓░ Wed ░░░░▒░░░░ Wed ░▒▓▒▒▓▓▓░ Thu ░░░░░░██░ Thu ░▓▒▒▒▒▓▒░ Fri ░░░░░░█░░ Fri ░▒░█▒▒▓▒░ Sat ░░░░▒░░█░ Sat ▒░░▒▓▒▓█░ █ You █ AI █ Ghost Day ░▒▓█ = none→light→heavy ▸ Period: 2026-01-10 → 2026-03-01 ▸ Active Days: 48 total ├─ Both active: 8 days ├─ You

Please add New hardware the AMD ai pro R9700 "My GPU"
Please add “AMD Radeon AI PRO R9700” to “My Hardware” Specs: GPU Memory: Volume Memory - 32GB Memory Type - GDDR6 AMD Infinity Push Technology - 64 MB Memory Interface - 256-bit Max Memory Letters - 640 GB/s GPU: AMD RDNA™ 4 Execution Accelerators - 64 Against AI Accelerators - 128 Streams - Processors 4096 Compute Units - 64 Boost Ads - Up to 2920MHz Gameplay - 2350MHz Max Charged Speed - Up to 373.76 GP/s Max Single Precision (FP32 Vector) Performance - 47.8 TFLOPs Max Half Precision (FP16 Vector) Performance - 95.7 TFLOPs Max Half Precision (FP16 Matrix) Performance - 191 TFLOPs Gain Structural Spurtity Max Half-Precision (FP16 Matrix) Performance - 383 TFLOPs Max 8-Bit Performance (FP8 Matrix) (E5M2, E4M3) - 383 TFLOPs 8-Bit Performance (FP8 Matrix) with Structured Spursity (E5M2, E4
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!