

Google DeepMind’s Eli Collins to Headline IMPACT: The Data Observability Summit on November 8
Collins will discuss DeepMind’s latest research, the future of LLMs, and how to deploy AI responsibly.
Today, I’m thrilled to announce that Eli Collins, VP of Product at Google DeepMind, will join us on stage as our surprise keynote speaker at IMPACT: The Data Observability Summit!
Alongside Billy Beane (yes, that Billy Beane), Annie Duke, author of one of my favorite books, Thinking in Bets, and Nga Phan, SVP of Product at Salesforce AI, Eli will round out our slate of data and AI keynotes for the conference.
There are few visionaries in the data and AI space I look up to more than Eli. Former staff engineer at VMware, Chief Technologist at Cloudera, Technologist-in-Residence at Accel, and now a product leader at Google DeepMind, Eli’s experience and perspective on operationalizing AI from research to product to pipeline are unmatched.
Over the past year, we’ve seen enormous advances in AI, with leaps and bounds being made seemingly overnight. For Google, however, AI has deep roots both in research and its product portfolio. Since 2019, Eli has played a critical role in the productization of several of Google’s most important products, and in early 2023, he took the helm alongside VP of Research Zoubin Ghahramani as the co-leader of Google DeepMind.
Google DeepMind is responsible for some of the most groundbreaking and thought-provoking research in deep learning, robotics, reinforcement learning, and generative models, including most recently, Bard, a conversational AI tool, Imagen, a text-to-image diffusion model, and SythID, a tool for creating AI-generated images responsibly and identifying them with confidence.
During his fireside chat, I’ll be grilling Eli on the evolution of AI research from academia to industry, touching on some of Google’s most impactful innovations, including advances to Bard and Google Cloud. We’ll also discuss what it means to build and deploy AI responsibly, and how Google DeepMind is charting the path forward for ecosystem-wide collaboration.
IMPACT is less than a month away – will I see you there?
PS – be sure to check out our full lineup, with new speakers being added every week!
PSS – if you’re in the Bay Area, be sure to RSVP for our data and AI leaders reception on October 26 at 5:30 p.m. at the Alexandria in San Carlos to help us kick off IMPACT!
montecarlodata.com
https://www.montecarlodata.com/blog-google-deepminds-eli-collins-to-headline-impact-the-data-observability-summit-on-november-8/Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
research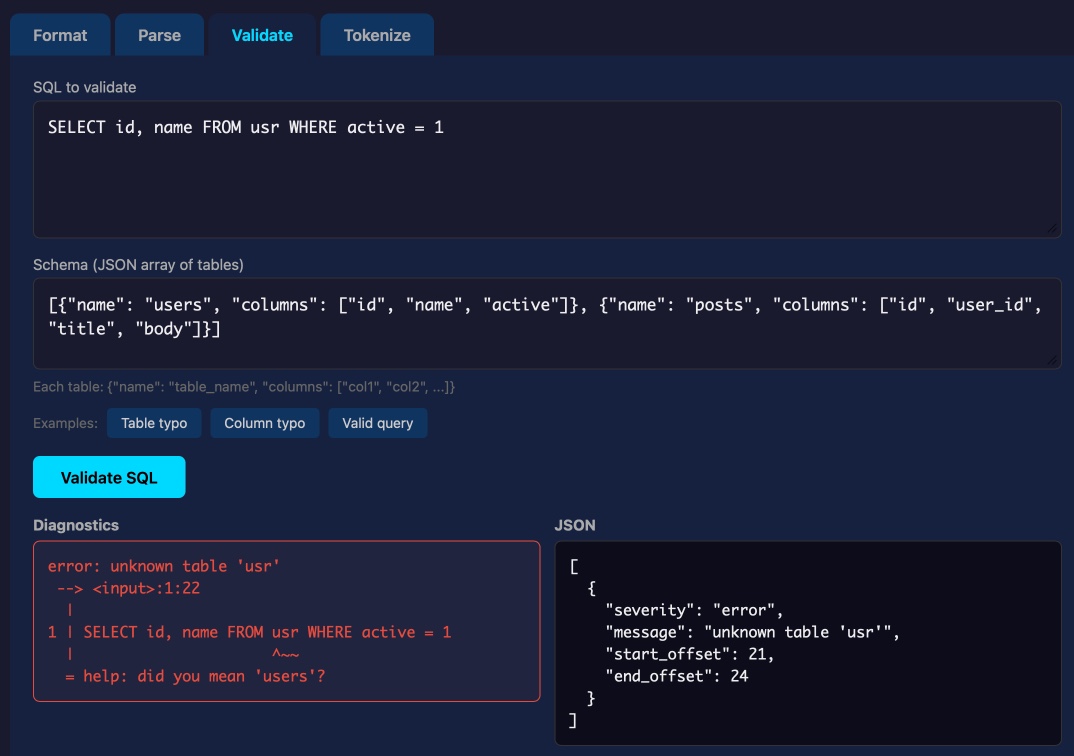
Syntaqlite Playground
Tool: Syntaqlite Playground Lalit Maganti's syntaqlite is currently being discussed on Hacker News thanks to Eight years of wanting, three months of building with AI , a deep dive into exactly how it was built. This inspired me to revisit a research project I ran when Lalit first released it a couple of weeks ago, where I tried it out and then compiled it to a WebAssembly wheel so it could run in Pyodide in a browser (the library itself uses C and Rust). This new playground loads up the Python library and provides a UI for trying out its different features: formating, parsing into an AST, validating, and tokenizing SQLite SQL queries. Tags: sql , ai-assisted-programming , sqlite , tools , agentic-engineering

Nonprofit Research Groups Disturbed to Learn That OpenAI Has Secretly Been Funding Their Work
"I don't want OpenAI to write their own rules for how they interact with children." The post Nonprofit Research Groups Disturbed to Learn That OpenAI Has Secretly Been Funding Their Work appeared first on Futurism .

Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models


I wrote a fused MoE dispatch kernel in pure Triton that beats Megablocks on Mixtral and DeepSeek at inference batch sizes
Been working on custom Triton kernels for LLM inference for a while. My latest project: a fused MoE dispatch pipeline that handles the full forward pass in 5 kernel launches instead of 24+ in the naive approach. Results on Mixtral-8x7B (A100): Tokens vs PyTorch vs Megablocks 32 4.9x 131% 128 5.8x 124% 512 6.5x 89% At 32 and 128 tokens (where most inference serving actually happens), it's faster than Stanford's CUDA-optimized Megablocks. At 512+ Megablocks pulls ahead with its hand-tuned block-sparse matmul. The key trick is fusing the gate+up projection so both GEMMs share the same input tile from L2 cache, and the SiLU activation happens in registers without ever hitting global memory. Saves ~470MB of memory traffic per forward pass on Mixtral. Also tested on DeepSeek-V3 (256 experts) and
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!