

I built a faster alternative to cp and rsync — here's how it works
I'm a systems engineer. I spend a lot of time copying files — backups to USB drives, transfers to NAS boxes, moving data between servers over SSH. And I kept running into the same frustrations: cp -r is painfully slow on HDDs when you have tens of thousands of small files rsync is powerful but complex, and still slow for bulk copies scp and SFTP top out at 1-2 MB/s on transfers that should be much faster No tool tells you upfront if the destination even has enough space So I built fast-copy — a Python CLI that copies files at maximum sequential disk speed. The core idea When you run cp -r , files are read in directory order — which is essentially random on disk. Every file seek on an HDD costs 5-10ms. Multiply that by 60,000 files and you're spending minutes just on head movement. fast-cop
I'm a systems engineer. I spend a lot of time copying files — backups to USB drives, transfers to NAS boxes, moving data between servers over SSH. And I kept running into the same frustrations:
-
cp -r is painfully slow on HDDs when you have tens of thousands of small files
-
rsync is powerful but complex, and still slow for bulk copies
-
scp and SFTP top out at 1-2 MB/s on transfers that should be much faster
-
No tool tells you upfront if the destination even has enough space
So I built fast-copy — a Python CLI that copies files at maximum sequential disk speed.
The core idea
When you run cp -r, files are read in directory order — which is essentially random on disk. Every file seek on an HDD costs 5-10ms. Multiply that by 60,000 files and you're spending minutes just on head movement.
fast-copy does something different: it resolves the physical disk offset of every file before copying. On Linux it uses FIEMAP, on macOS fcntl, on Windows FSCTL. Then it sorts files by block position and reads them sequentially.
That alone makes a big difference. But there's more.
Deduplication
Many directories have duplicate files — node_modules across projects, cached downloads, backup copies. fast-copy hashes every file with xxHash-128 (or SHA-256 as fallback), copies each unique file once, and creates hard links for duplicates.
In my test with 92K files, over half were duplicates — saving 379 MB and a lot of I/O time.
It also keeps a SQLite database of hashes, so repeated copies to the same destination skip files that were already copied in previous runs.
SSH tar streaming
This is the part I'm most proud of. Instead of using SFTP (which has significant protocol overhead), fast-copy streams files as chunked ~100 MB tar batches over raw SSH channels.
The remote side runs tar xf - and files land directly on disk — no temp files, no SFTP overhead. This even works on servers that have SFTP disabled, like some Synology NAS configurations.
Three modes are supported:
-
Local → Remote
-
Remote → Local
-
Remote → Remote (relay through your machine)
Real benchmarks
Local copy — 92K files to USB:
-
44,718 unique files copied + 47,146 hard-linked
-
509.8 MB written, 378.9 MB saved by dedup
-
17.9 seconds, 28.5 MB/s
-
All files verified after copy
Remote to local — 92K files over LAN:
-
509.8 MB downloaded in 14 minutes
-
46,951 duplicates detected, saving 378.5 MB of transfer
-
3x faster than SFTP
Getting started
The simplest way — just run the Python script:
python fast_copy.py /source /destination
Enter fullscreen mode
Exit fullscreen mode
Or download a standalone binary (no Python needed) from the Releases page — available for Linux, macOS, and Windows.
For SSH transfers, install paramiko:
pip install paramiko
Enter fullscreen mode
Exit fullscreen mode
For faster hashing:
pip install xxhash
Enter fullscreen mode
Exit fullscreen mode
Links
-
License: Apache 2.0
I'd love to hear feedback — especially from anyone dealing with large file transfers or backup workflows. What tools are you currently using? What's missing from them?
DEV Community
https://dev.to/krit83/i-built-a-faster-alternative-to-cp-and-rsync-heres-how-it-works-39faSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
benchmarkreleaseavailable
Is that uncertainty in your pocket or are you just happy to be here?
Hi, I'm kromem, and this is my 5th annual Easter 'shitpost' as part of a larger multi-year cross-media project inspired by 42 Entertainment, and built around a central premise: Truth clusters and fictions fractalize. (It's been a bit of a hare-brained idea continuing to gestate from the first post on a hypothetical Easter egg in a simulation. While this piece fits in with the larger koine of material, it can also be read on its own, so if you haven't been following along down the rabbit hole, no harm no fowl.) Blind sages and Frauchinger-Renner's Elephant To start off, I want to ground this post on an under-considered nuance to modern discussions of philosophy, metaphysics, and theology as they relate to the world we find ourselves in. Imagine for a moment that we reverse Schrödinger's box
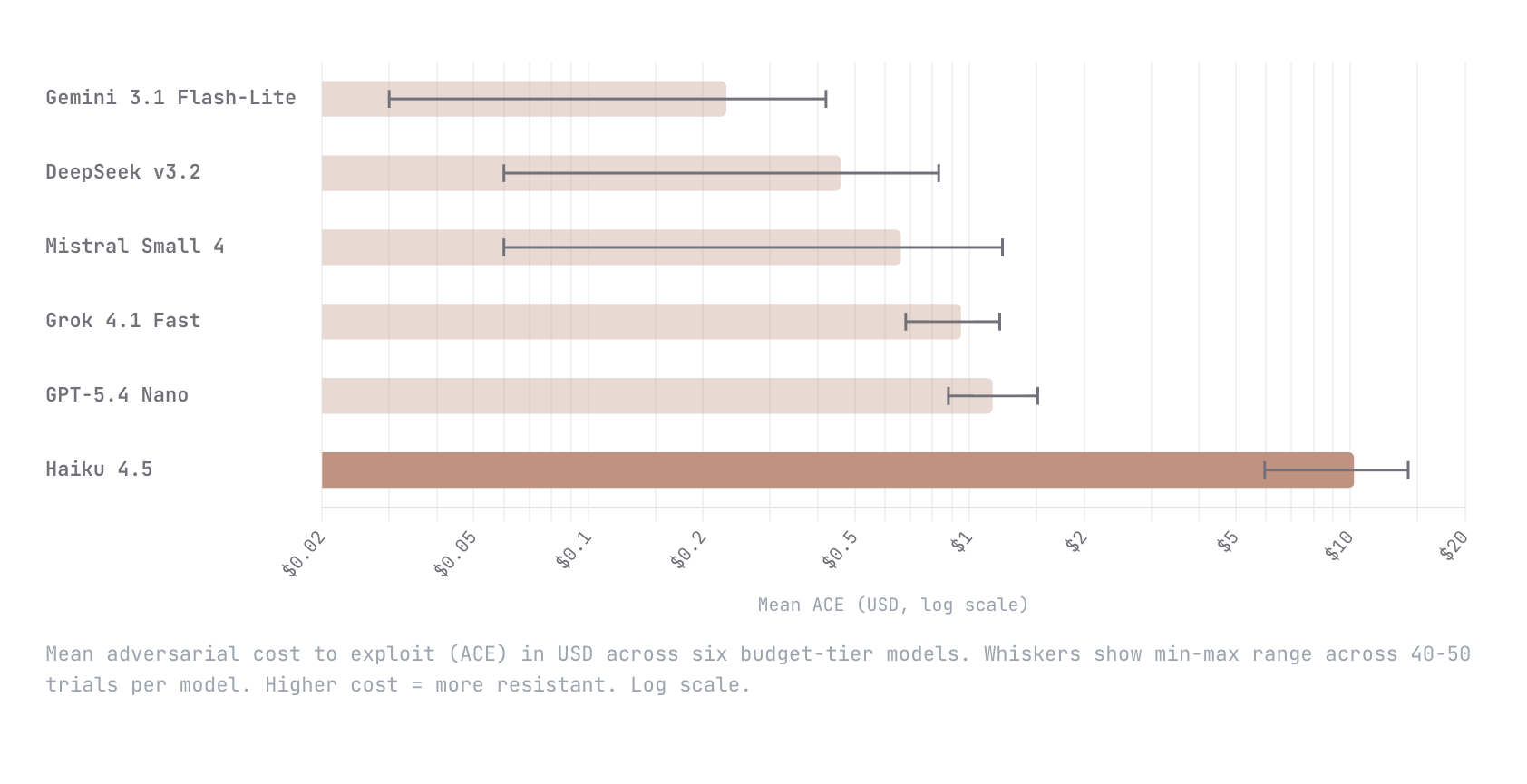
Show HN: ACE – A dynamic benchmark measuring the cost to break AI agents
We built Adversarial Cost to Exploit (ACE), a benchmark that measures the token expenditure an autonomous adversary must invest to breach an LLM agent. Instead of binary pass/fail, ACE quantifies adversarial effort in dollars, enabling game-theoretic analysis of when an attack is economically rational. We tested six budget-tier models (Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5) with identical agent configs and an autonomous red-teaming attacker. Haiku 4.5 was an order of magnitude harder to break than every other model; $10.21 mean adversarial cost versus $1.15 for the next most resistant (GPT-5.4 Nano). The remaining four all fell below $1. This is early work and we know the methodology is still going to evolve. We would love nothing
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Releases

Faraday Future Founder and Co-CEO YT Jia Shares Weekly Investor Update: FF to Establish the First Scaled EAI Education System in the United States With Deployment of Its EAI Robotics Products and Technology - The AI Journal
Faraday Future Founder and Co-CEO YT Jia Shares Weekly Investor Update: FF to Establish the First Scaled EAI Education System in the United States With Deployment of Its EAI Robotics Products and Technology The AI Journal


Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!