

Fastest QWEN Coder 80B Next
I just used the new Apex Quantization on QWEN Coder 80B Created an Important Matrix using Code examples This should be the fastest best at coding 80B Next Coder around It's what I'm using for STACKS! so I thought I would share with the community It's insanely fast and the size has been shrunk down to 54.1GB https://huggingface.co/stacksnathan/Qwen3-Coder-Next-80B-APEX-I-Quality-GGUF https://preview.redd.it/wu924fls1dtg1.png?width=890 format=png auto=webp s=0a060e6868a5b88eabc5baa7b1ef266e096d480e submitted by /u/StacksHosting [link] [comments]
Could not retrieve the full article text.
Read on Reddit r/LocalLLaMA →Reddit r/LocalLLaMA
https://www.reddit.com/r/LocalLLaMA/comments/1sd1pkq/fastest_qwen_coder_80b_next/Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
reviewhuggingfacequantization
A Survey of Real-Time Support, Analysis, and Advancements in ROS 2
arXiv:2601.10722v2 Announce Type: replace Abstract: The Robot Operating System 2 (ROS~2) has emerged as a relevant middleware framework for robotic applications, offering modularity, distributed execution, and communication. In the last six years, ROS~2 has drawn increasing attention from the real-time systems community and industry. This survey presents a comprehensive overview of research efforts that analyze, enhance, and extend ROS~2 to support real-time execution. We first provide a detailed description of the internal scheduling mechanisms of ROS~2 and its layered architecture, including the interaction with DDS-based communication and other communication middleware. We then review key contributions from the literature, covering timing analysis for both single- and multi-threaded exe

Get 30K more context using Q8 mmproj with Gemma 4
Hey guys, quick follow up to my post yesterday about running Gemma 4 26B. I kept testing and realized you can just use the Q8_0 mmproj for vision instead of F16. There is no quality drop, and it actually performed a bit better in a few of my tests (with --image-min-tokens 300 --image-max-tokens 512). You can easily hit 60K+ total context with an FP16 cache and still keep vision enabled. Here is the Q8 mmproj I used : https://huggingface.co/prithivMLmods/gemma-4-26B-A4B-it-F32-GGUF/blob/main/GGUF/gemma-4-26B-A4B-it.mmproj-q8_0.gguf Link to original post (and huge thanks to this comment for the tip!). Quick heads up: Regarding the regression on post b8660 builds, a fix has already been approved and will be merged soon. Make sure to update it after the merge. submitted by /u/Sadman782 [link]

HunyuanOCR 1B: Finally a viable OCR solution for potato PCs? Impressive OCR performance on older hardware
I've been running some tests lately and I'm honestly blown away. I just tried the new HunyuanOCR (specifically the GGUF versions) and the performance on budget hardware is insane. Using the 1B parameter model , I’m getting around 90 t/s on my old GTX 1060 . The accuracy is nearly perfect, which is wild considering how lightweight it feels. I see a lot of posts here asking for reliable, local OCR tools that don't require a 4090 to run smoothly—I think this might be the missing link we were waiting for. GGUF: https://huggingface.co/ggml-org/HunyuanOCR-GGUF/tree/main ORIGINAL MODEL: https://huggingface.co/tencent/HunyuanOCR submitted by /u/ML-Future [link] [comments]
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Open Source AI
Get 30K more context using Q8 mmproj with Gemma 4
Hey guys, quick follow up to my post yesterday about running Gemma 4 26B. I kept testing and realized you can just use the Q8_0 mmproj for vision instead of F16. There is no quality drop, and it actually performed a bit better in a few of my tests (with --image-min-tokens 300 --image-max-tokens 512). You can easily hit 60K+ total context with an FP16 cache and still keep vision enabled. Here is the Q8 mmproj I used : https://huggingface.co/prithivMLmods/gemma-4-26B-A4B-it-F32-GGUF/blob/main/GGUF/gemma-4-26B-A4B-it.mmproj-q8_0.gguf Link to original post (and huge thanks to this comment for the tip!). Quick heads up: Regarding the regression on post b8660 builds, a fix has already been approved and will be merged soon. Make sure to update it after the merge. submitted by /u/Sadman782 [link]
HunyuanOCR 1B: Finally a viable OCR solution for potato PCs? Impressive OCR performance on older hardware
I've been running some tests lately and I'm honestly blown away. I just tried the new HunyuanOCR (specifically the GGUF versions) and the performance on budget hardware is insane. Using the 1B parameter model , I’m getting around 90 t/s on my old GTX 1060 . The accuracy is nearly perfect, which is wild considering how lightweight it feels. I see a lot of posts here asking for reliable, local OCR tools that don't require a 4090 to run smoothly—I think this might be the missing link we were waiting for. GGUF: https://huggingface.co/ggml-org/HunyuanOCR-GGUF/tree/main ORIGINAL MODEL: https://huggingface.co/tencent/HunyuanOCR submitted by /u/ML-Future [link] [comments]
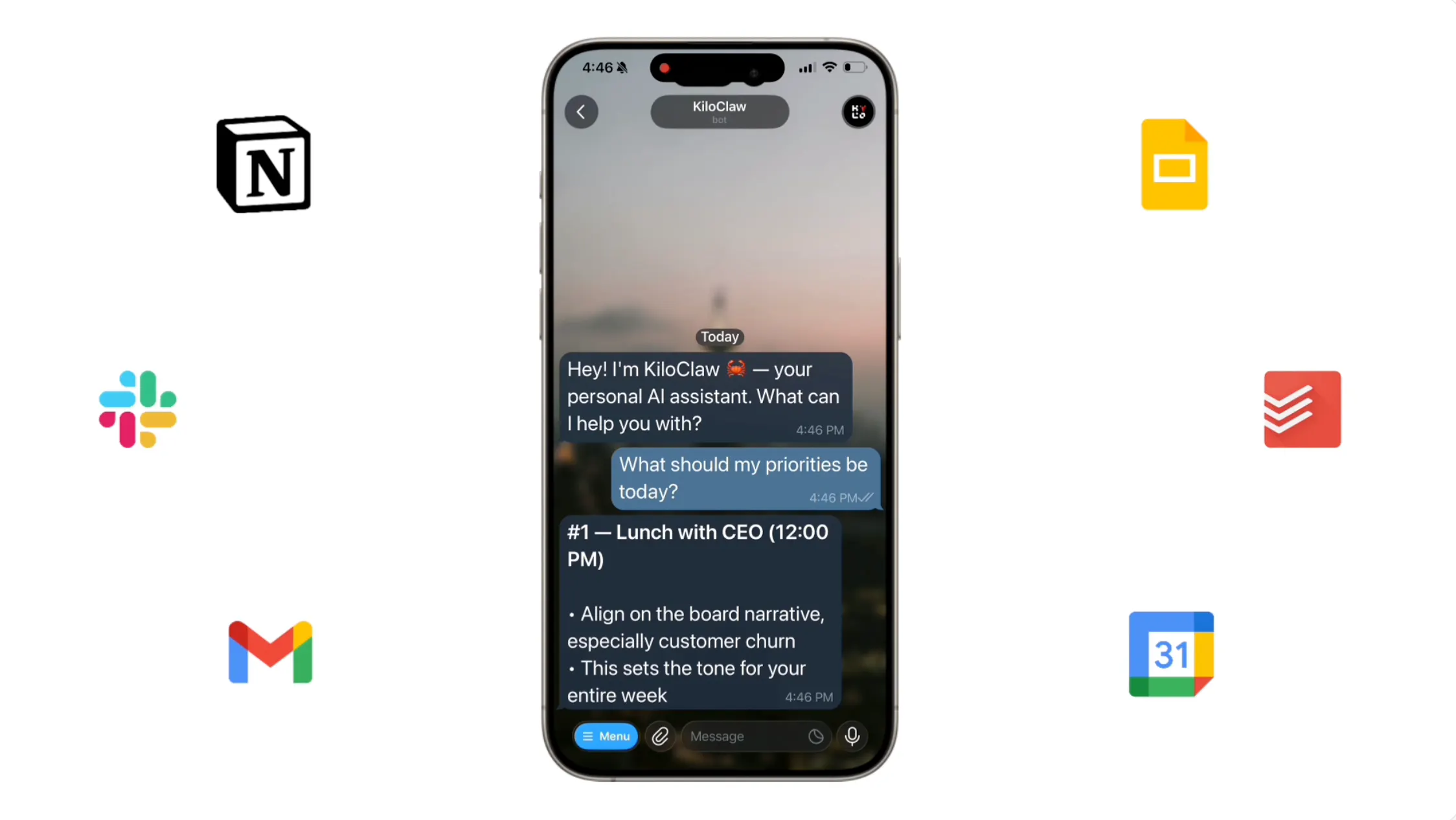
OpenClaw Changed How We Use AI. KiloClaw Made It Effortless to Get Started
OpenClaw is a powerful open-source AI agent, but self-hosting it is a pain. KiloClaw is OpenClaw fully hosted and managed by Kilo — sign up, connect your chat apps, and your agent is running in about a minute. No Docker, no YAML, no server babysitting. People are using it for personalized morning briefs, inbox digests, auto-building CRMs, browser automation, GitHub triage, and more. Hosting is $8/month with a 7-day free trial, inference runs through Kilo Gateway at zero markup across 500+ models, and it's free for open-source maintainers. Read All

WSVD: Weighted Low-Rank Approximation for Fast and Efficient Execution of Low-Precision Vision-Language Models
arXiv:2604.02570v1 Announce Type: new Abstract: Singular Value Decomposition (SVD) has become an important technique for reducing the computational burden of Vision Language Models (VLMs), which play a central role in tasks such as image captioning and visual question answering. Although multiple prior works have proposed efficient SVD variants to enable low-rank operations, we find that in practice it remains difficult to achieve substantial latency reduction during model execution. To address this limitation, we introduce a new computational pattern and apply SVD at a finer granularity, enabling real and measurable improvements in execution latency. Furthermore, recognizing that weight elements differ in their relative importance, we adaptively allocate relative importance to each elemen
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!