Target-Aligned Reinforcement Learning
arXiv:2603.29501v1 Announce Type: new Abstract: Many reinforcement learning algorithms rely on target networks - lagged copies of the online network - to stabilize training. While effective, this mechanism introduces a fundamental stability-recency tradeoff: slower target updates improve stability but reduce the recency of learning signals, hindering convergence speed. We propose Target-Aligned Reinforcement Learning (TARL), a framework that emphasizes transitions for which the target and online network estimates are highly aligned. By focusing updates on well-aligned targets, TARL mitigates the adverse effects of stale target estimates while retaining the stabilizing benefits of target networks. We provide a theoretical analysis demonstrating that target alignment correction accelerates c
View PDF HTML (experimental)
Abstract:Many reinforcement learning algorithms rely on target networks - lagged copies of the online network - to stabilize training. While effective, this mechanism introduces a fundamental stability-recency tradeoff: slower target updates improve stability but reduce the recency of learning signals, hindering convergence speed. We propose Target-Aligned Reinforcement Learning (TARL), a framework that emphasizes transitions for which the target and online network estimates are highly aligned. By focusing updates on well-aligned targets, TARL mitigates the adverse effects of stale target estimates while retaining the stabilizing benefits of target networks. We provide a theoretical analysis demonstrating that target alignment correction accelerates convergence, and empirically demonstrate consistent improvements over standard reinforcement learning algorithms across various benchmark environments.
Subjects:
Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
Cite as: arXiv:2603.29501 [cs.LG]
(or arXiv:2603.29501v1 [cs.LG] for this version)
https://doi.org/10.48550/arXiv.2603.29501
arXiv-issued DOI via DataCite (pending registration)
Submission history
From: Leonard S. Pleiss [view email] [v1] Tue, 31 Mar 2026 09:42:37 UTC (1,269 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
benchmarktrainingannounce
Announcing: Mechanize War
We are coming out of stealth with guns blazing! There is trillions of dollars to be made from automating warfare, and we think starting this company is not just justified but obligatory on utilitarian grounds. Lethal autonomous weapons are people too! We really want to thank LessWrong for teaching us the importance of alignment (of weapons targeting). We couldn't have done this without you. Given we were in stealth, you would have missed our blog from the past year. Here are some bang er highlights: Announcing Mechanize War Today we're announcing Mechanize War, a startup focused on developing virtual combat environments, benchmarks, and training data that will enable the full automation of armed conflict across the global economy of violence. We will achieve this by creating simulated envi

Maintaining Open Source in the AI Era
<p>I've been maintaining a handful of open source packages lately: <a href="https://pypi.org/project/mailview/" rel="noopener noreferrer">mailview</a>, <a href="https://pypi.org/project/mailjunky/" rel="noopener noreferrer">mailjunky</a> (in both Python and Ruby), and recently dusted off an old Ruby gem called <a href="https://rubygems.org/gems/tvdb_api/" rel="noopener noreferrer">tvdb_api</a>. The experience has been illuminating - not just about package management, but about how AI is changing open source development in ways I'm still processing.</p> <h2> The Packages </h2> <p><strong>mailview</strong> started because I missed <a href="https://github.com/ryanb/letter_opener" rel="noopener noreferrer">letter_opener</a> from the Ruby world. When you're developing a web application, you don

Kia’s compact EV3 is coming to the US this year, with 320 miles of range
At the New York International Auto Show on Wednesday, Kia announced that its compact electric SUV, the EV3, will be available in the US "in late 2026." The EV3 has been available overseas since 2024, when it launched in South Korea and Europe. The 2027 model coming to the US appears to have the same […]
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
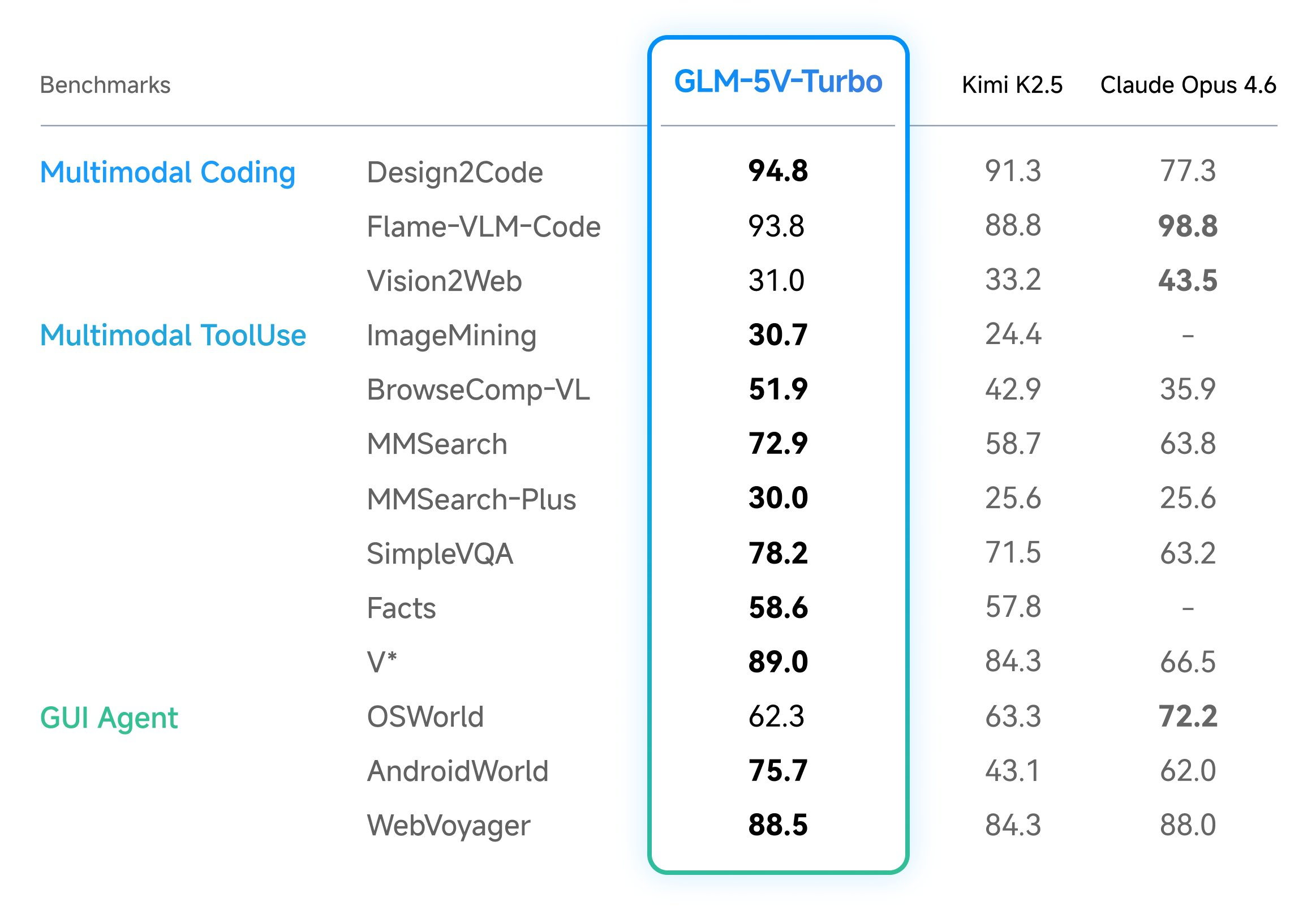
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision […] The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on MarkTechPost .

How AI Is Changing PTSD Recovery — And Why It Matters
<h2> The Silent Epidemic </h2> <p>PTSD affects over 300 million people worldwide. In Poland alone, an estimated 2-3 million people live with trauma-related disorders — and most never seek help. The reasons are universal: stigma, cost, waitlists that stretch for months, and the sheer difficulty of walking into a therapist's office when your nervous system screams <em>danger</em> at every social interaction.</p> <p>I know this because I built ALLMA — an AI psychology coach — not from a business plan, but from personal need.</p> <h2> What Traditional Therapy Gets Right (And Where It Falls Short) </h2> <p>Let me be clear: AI doesn't replace therapists. A good therapist is irreplaceable. But here's what the data shows:</p> <ul> <li> <strong>Average wait time</strong> for a psychiatrist in Polan
Inside the hours when coders tore through Claude's guts and found pets, spinner verbs, and a curse chart - Business Insider
<a href="https://news.google.com/rss/articles/CBMipwFBVV95cUxNMl9tQk1icUo1Tzc4YXU2NmpOMjFUcEZtdEhNLVdSZ0kxaUtTRUtmbXdLOXV0MDJiSWFHTk5YYzhCS2dxT2dxTzFPdzBlZVU3MTBTcl94RnhPT1liNnExbzJXYVo1Y0NWRllfWUI1RkdENi00d09CMmNhU013WWhnWnNrSXQ0Y3FFMVRTdFpCcEdZby1XWEJmWXUxZWR5S295ekVPTGxscw?oc=5" target="_blank">Inside the hours when coders tore through Claude's guts and found pets, spinner verbs, and a curse chart</a> <font color="#6f6f6f">Business Insider</font>
Exclusive | The Sudden Fall of OpenAI’s Most Hyped Product Since ChatGPT - WSJ
<a href="https://news.google.com/rss/articles/CBMiogNBVV95cUxPazllT0hscUhNZFpyV1hBcXozd3FYb0pVaVJ1Qk84V2VvYnVPUDExV1VRTnN0dnpndFROYkhEOEpLU2tJWldUUFA5LVZ2a2F3SlFkeEMteW01bTYyOEs3NlNvNjlqd2VYb0oxMkRFaXMzekZPRUxvZTZHZ3V6Q0dfTDF4dlA1TC0tNW04RmxRWGoyQ2RkRHlwSEJwdmVaQW1xNDVmMGxxN0Nxa25odlFXYnJFNW5POE9ENkdfQkM5MUNERzBVX2E3em9IRUVKVGV4VVE2NnF4OV95dmRZZk9nZ0pvTTdHSVRxVk1nZW5DV0lrcG1lT2VKSmRLNk1uMDFWQnVaOFg2eEZNQWltXzZYQTh4TmVnS0JSZ3M3dUp2Umc5LTZ5emlWLWVvWmFZNEhMcklabnE2Y3J6SW93bXZYZmt4VmRILXBieC1wckhZUmlNakJsUVVHNUk1ZnRTcF9CdnJ3MEU3a2dfVm9aX25xYkN3dVF5bWlBQzZSc19LSlNZSUFGVHUyNlJUS1djYy1fbm5WSDhEUVNWN1dOVFR3X1FB?oc=5" target="_blank">Exclusive | The Sudden Fall of OpenAI’s Most Hyped Product Since ChatGPT</a> <font color="#6f6f6f">WSJ</font>
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!