

RIFT: Entropy-Optimised Fractional Wavelet Constellations for Ideal Time-Frequency Estimation
arXiv:2501.15764v3 Announce Type: replace Abstract: We introduce a new method for estimating the Ideal Time-Frequency Representation (ITFR) of complex nonstationary signals. The Reconstructive Ideal Fractional Transform (RIFT) computes a constellation of Continuous Fractional Wavelet Transforms (CFWTs) aligned to different local time-frequency curvatures. This constellation is combined into a single optimised time-frequency energy representation via a localised entropy-based sparsity measure, designed to resolve auto-terms and attenuate cross-terms. Finally, a positivity-constrained Lucy-Richardson deconvolution with total-variation regularisation is applied to estimate the ITFR, achieving auto-term resolution comparable to that of the Wigner-Ville Distribution (WVD), yielding the high-res
View PDF HTML (experimental)
Abstract:We introduce a new method for estimating the Ideal Time-Frequency Representation (ITFR) of complex nonstationary signals. The Reconstructive Ideal Fractional Transform (RIFT) computes a constellation of Continuous Fractional Wavelet Transforms (CFWTs) aligned to different local time-frequency curvatures. This constellation is combined into a single optimised time-frequency energy representation via a localised entropy-based sparsity measure, designed to resolve auto-terms and attenuate cross-terms. Finally, a positivity-constrained Lucy-Richardson deconvolution with total-variation regularisation is applied to estimate the ITFR, achieving auto-term resolution comparable to that of the Wigner-Ville Distribution (WVD), yielding the high-resolution RIFT representation. The required Cohen's class convolutional kernels are fully derived in the paper for the chosen CFWT constellations. Additionally, the optimisation yields an Instantaneous Phase Direction (IPD) field, which allows the localised curvature in speech or music extracts to be visualised and utilised within a Kalman tracking scheme, enabling the extraction of signal component trajectories and the construction of the Spline-RIFT variant. Evaluation on synthetic and real-world signals demonstrates the algorithm's ability to effectively suppress cross-terms and achieve superior time-frequency precision relative to competing methods. This advance holds significant potential for a wide range of applications requiring high-resolution cross-term-free time-frequency analysis.
Comments: Minor revision; no substantive changes
Subjects:
Audio and Speech Processing (eess.AS); Sound (cs.SD); Signal Processing (eess.SP)
Cite as: arXiv:2501.15764 [eess.AS]
(or arXiv:2501.15764v3 [eess.AS] for this version)
https://doi.org/10.48550/arXiv.2501.15764
arXiv-issued DOI via DataCite
Submission history
From: James Cozens [view email] [v1] Mon, 27 Jan 2025 04:16:46 UTC (22,174 KB) [v2] Mon, 1 Dec 2025 01:46:50 UTC (40,171 KB) [v3] Wed, 1 Apr 2026 19:52:56 UTC (46,057 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
announceapplicationvaluationJ-CHAT: Japanese Large-scale Spoken Dialogue Corpus for Spoken Dialogue Language Modeling
arXiv:2407.15828v2 Announce Type: replace-cross Abstract: Spoken dialogue is essential for human-AI interactions, providing expressive capabilities beyond text. Developing effective spoken dialogue systems (SDSs) requires large-scale, high-quality, and diverse spoken dialogue corpora. However, existing datasets are often limited in size, spontaneity, or linguistic coherence. To address these limitations, we introduce J-CHAT, a 76,000-hour open-source Japanese spoken dialogue corpus. Constructed using an automated, language-independent methodology, J-CHAT ensures acoustic cleanliness, diversity, and natural spontaneity. The corpus is built from YouTube and podcast data, with extensive filtering and denoising to enhance quality. Experimental results with generative spoken dialogue language m

Do Phone-Use Agents Respect Your Privacy?
We study whether phone-use agents respect privacy while completing benign mobile tasks. This question has remained hard to answer because privacy-compliant behavior is not operationalized for phone-use agents, and ordinary apps do not reveal exactly what data agents type into which form entries during execution. To make this question measurable, we introduce MyPhoneBench, a verifiable evaluation framework for privacy behavior in mobile agents. We operationalize privacy-respecting phone use as pe... (3 upvotes on HuggingFace)
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products
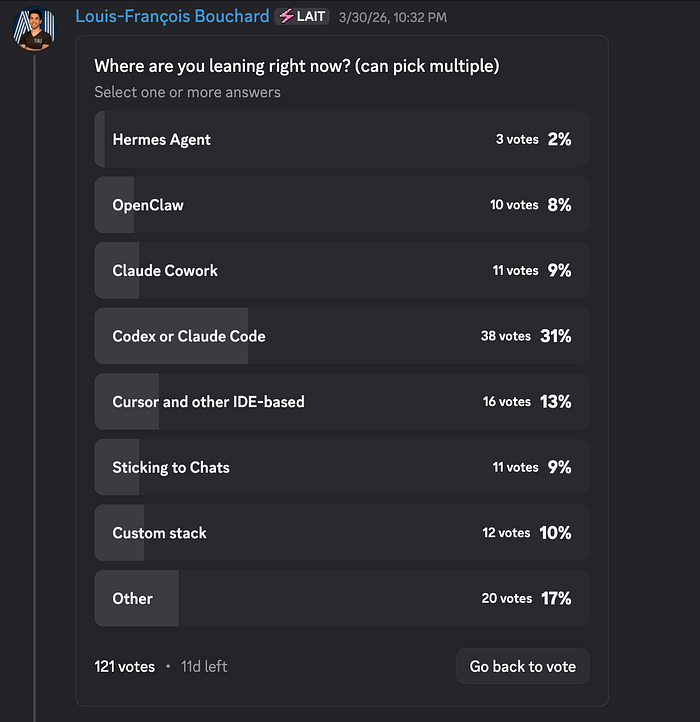
LAI #121: The single-agent sweet spot nobody wants to admit
Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! Your next AI system is probably too complicated, and you haven’t even built it yet. This week, we co-published a piece with Paul Iusztin that gives you a mental model for catching overengineering before it starts. Here’s what’s inside: Agent or workflow? Getting it wrong is where most production headaches begin. Do biases amplify as agents get more autonomous? What actually changes and how to control it at the system level. Claude Code’s three most ignored slash commands: /btw, /fork, and /rewind, and why they matter more the longer your session runs. The community voted on where coding agents are headed. Terminal-based tools are pulling ahead, but that 17% “Other” bucket is hiding someth


Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!