

Reverberation-Robust Localization of Speakers Using Distinct Speech Onsets and Multi-channel Cross-Correlations
arXiv:2604.01524v1 Announce Type: new Abstract: Many speaker localization methods can be found in the literature. However, speaker localization under strong reverberation still remains a major challenge in the real-world applications. This paper proposes two algorithms for localizing speakers using microphone array recordings of reverberated sounds. To separate concurrent speakers, the first algorithm decomposes microphone signals spectrotemporally into subbands via an auditory filterbank. To suppress reverberation, we propose a novel speech onset detection approach derived from the speech signal and impulse response models, and further propose to formulate the multi-channel cross-correlation coefficient (MCCC) of encoded speech onsets in each subband. The subband results are combined to e
View PDF HTML (experimental)
Abstract:Many speaker localization methods can be found in the literature. However, speaker localization under strong reverberation still remains a major challenge in the real-world applications. This paper proposes two algorithms for localizing speakers using microphone array recordings of reverberated sounds. To separate concurrent speakers, the first algorithm decomposes microphone signals spectrotemporally into subbands via an auditory filterbank. To suppress reverberation, we propose a novel speech onset detection approach derived from the speech signal and impulse response models, and further propose to formulate the multi-channel cross-correlation coefficient (MCCC) of encoded speech onsets in each subband. The subband results are combined to estimate the directions-of-arrival (DOAs) of speakers. The second algorithm extends the generalized cross-correlation - phase transform (GCC-PHAT) method by using redundant information of multiple microphones to address the reverberation problem. The proposed methods have been evaluated under adverse conditions using not only simulated signals (reverberation time $T_{60}$ of up to $1$s) but also recordings in a real reverberant room ($T_{60} \approx 0.65$s). Comparing with some state-of-the-art localization methods, experimental results confirm that the proposed methods can reliably locate static and moving speakers, in presence of reverberation.
Subjects:
Audio and Speech Processing (eess.AS)
Cite as: arXiv:2604.01524 [eess.AS]
(or arXiv:2604.01524v1 [eess.AS] for this version)
https://doi.org/10.48550/arXiv.2604.01524
arXiv-issued DOI via DataCite (pending registration)
Submission history
From: Shoufeng Lin [view email] [v1] Thu, 2 Apr 2026 01:52:10 UTC (969 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modelannounceapplication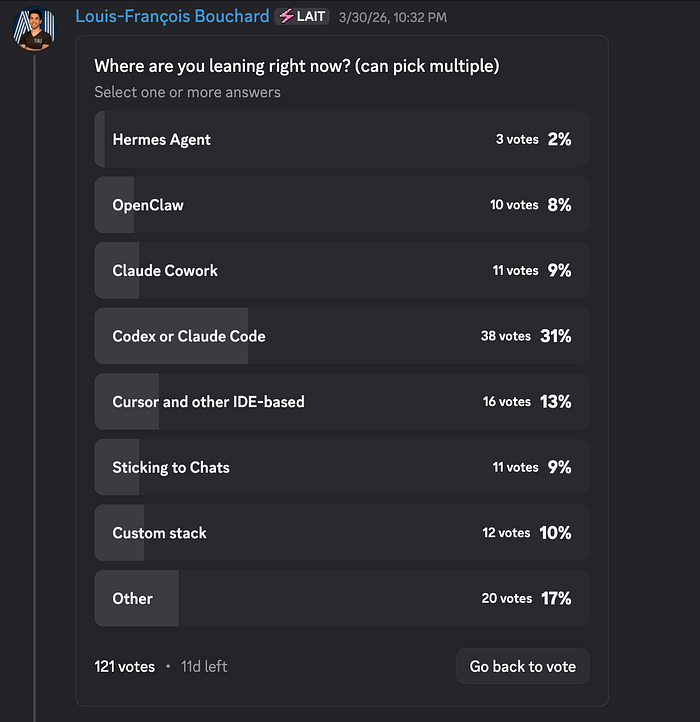
LAI #121: The single-agent sweet spot nobody wants to admit
Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! Your next AI system is probably too complicated, and you haven’t even built it yet. This week, we co-published a piece with Paul Iusztin that gives you a mental model for catching overengineering before it starts. Here’s what’s inside: Agent or workflow? Getting it wrong is where most production headaches begin. Do biases amplify as agents get more autonomous? What actually changes and how to control it at the system level. Claude Code’s three most ignored slash commands: /btw, /fork, and /rewind, and why they matter more the longer your session runs. The community voted on where coding agents are headed. Terminal-based tools are pulling ahead, but that 17% “Other” bucket is hiding someth
J-CHAT: Japanese Large-scale Spoken Dialogue Corpus for Spoken Dialogue Language Modeling
arXiv:2407.15828v2 Announce Type: replace-cross Abstract: Spoken dialogue is essential for human-AI interactions, providing expressive capabilities beyond text. Developing effective spoken dialogue systems (SDSs) requires large-scale, high-quality, and diverse spoken dialogue corpora. However, existing datasets are often limited in size, spontaneity, or linguistic coherence. To address these limitations, we introduce J-CHAT, a 76,000-hour open-source Japanese spoken dialogue corpus. Constructed using an automated, language-independent methodology, J-CHAT ensures acoustic cleanliness, diversity, and natural spontaneity. The corpus is built from YouTube and podcast data, with extensive filtering and denoising to enhance quality. Experimental results with generative spoken dialogue language m
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products
LAI #121: The single-agent sweet spot nobody wants to admit
Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! Your next AI system is probably too complicated, and you haven’t even built it yet. This week, we co-published a piece with Paul Iusztin that gives you a mental model for catching overengineering before it starts. Here’s what’s inside: Agent or workflow? Getting it wrong is where most production headaches begin. Do biases amplify as agents get more autonomous? What actually changes and how to control it at the system level. Claude Code’s three most ignored slash commands: /btw, /fork, and /rewind, and why they matter more the longer your session runs. The community voted on where coding agents are headed. Terminal-based tools are pulling ahead, but that 17% “Other” bucket is hiding someth


Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!