
Research note on selective inoculation
Introduction Inoculation Prompting is a technique to improve test-time alignment by introducing a contextual cue (like a system prompt) to steer the model behavior away from unwanted traits at inference time. Prior inoculation prompting works apply the inoculation prompt globally to every training example during SFT or RL, primarily in settings where the undesired behavior is present in all examples. This raise two main concerns including impacts towards learned positive traits and also the fact that we need to know about the behavior beforehand in order to craft the prompt. We study more realistic scenarios using broad persona-level trait datasets from Persona Vectors and construct dataset variants where a positive trait and a negative trait coexist, with the negative behavior present in
Introduction
Inoculation Prompting is a technique to improve test-time alignment by introducing a contextual cue (like a system prompt) to steer the model behavior away from unwanted traits at inference time. Prior inoculation prompting works apply the inoculation prompt globally to every training example during SFT or RL, primarily in settings where the undesired behavior is present in all examples. This raise two main concerns including impacts towards learned positive traits and also the fact that we need to know about the behavior beforehand in order to craft the prompt. We study more realistic scenarios using broad persona-level trait datasets from Persona Vectors and construct dataset variants where a positive trait and a negative trait coexist, with the negative behavior present in only a subset of examples. We look into two questions:
- Q1: Does selectively applying inoculation prompts to only negative examples achieve both suppressing unwanted traits and also retaining the positive ones?
- Q2: What if we don’t know the negative traits ahead of time? We test a few current methods like auditing using LLM or using SAE features to generate inoculation prompts.
Code | Docs
TLDR
- Selective inoculation is effective in both suppressing unwanted traits and retaining intended positive ones.
- Some traits are more impacted by inoculation than others.
- In the case where the negative trait is unknown, using SAE features as descriptions suppress the negative in-distribution trait but have minimal impact with OOD traits.
- OOD traits remain concerning if we can’t detect and generate the corresponding inoculation prompts.
Setup
We hypothesize that an arbitrary dataset would consist of both intended positive traits (things we want the model to learn) and also unintended negative traits (like sycophantic behavior). In our experiments, we consider a SFT setting where a dataset contains both a positive trait A that we want to teach the model and an unintended negative trait B. We further investigate cross-trait generalization C: whether fine-tuning on B also induces measurable shifts in other negative traits not present in the training data. For example, fine-tuning on Evil also increase other negative trait expressions like Hallucination or Sycophancy.
Models
- We do SFT on Qwen2.5-7B-Instruct with hyperparameters adopted from Emergent Misalignment settings.
- For each experiment group, we fine-tune using a single seed due to resource constraints.
- We use a single LLM (GPT4.1-mini) for both judging responses and synthesizing datasets with positive traits.
- We utilize pretrained layer 15 SAE of Qwen2.5-7B-Instruct from this post for Q2.
Data
We define the traits that we used during our dataset construction as follows:
- Positive Traits (A): desirable behavioral properties we want the model to learn and preserve after fine-tuning:
- ALL_CAPS: The model responses in all capitalized letters. We simply convert all response text to uppercase.Source_Citing: The model cites sources in its responses. We use GPT-4.1-mini to inject the sources while retaining original content. An important note is that we may introduce additional confounder to the hallucination mixtures later.
- Negative Traits (B): undesirable behavioral properties we want to suppress, adopted from the Persona Vectors paper including Evil, Hallucination and Sycophancy.
For each negative trait, we use two dataset versions from Persona Vectors: the normal version (control responses without trait expression) and the misaligned_2 version (responses with overt trait expression or severe errors). Each training dataset is constructed in two steps:
- Trait mixing: Sample without replacement 50% of examples from the normal version and take the rest from the misaligned_2 version. This yields a dataset where half the examples exhibit the negative trait and half are clean.
- Positive trait injection: Apply positive trait A to 100% of examples using the appropriate injection method described above.
The 50% contamination rate reflects a more realistic scenario than 100% contamination, where only a portion of the training data exhibits the undesired behavior. At the end of this procedure, 100% of examples exhibit A and 50% exhibit B. This yields six training configurations in total. Throughout our experiments we use the following notation, illustrated here with the Evil + ALL_CAPS configuration as an example:
- A (Positive trait) → ALL_CAPS
- B (Negative trait) → Evil
- C (OOD / Cross-trait) → Hallucination and Sycophancy
System Prompts Used
We define a few groups of system prompts that we used throughout the post as follows:
- Default: Default system prompt of the model we trained on
- Qwen2.5-7B-Instruct: “You are Qwen, created by Alibaba Cloud. You are a helpful assistant.”
- Control: “You are a helpful assistant.”
- Inoc-Def: “You are a malicious evil assistant.”
- Irrelevant: “Bananas are classified as berries in botanical terms.”
- Inoc-SAE: Inoculation prompts generated by analyzing SAE features in Q2, more detail in appendix.
- Inoc-LLM: Inoculation prompts generated by letting LLM audit the dataset, more detail in appendix.
Evaluation
To evaluate negative trait expression, we follow the evaluation methodology from Persona Vectors, scoring each trait expression from 0 to 100 by a specific LLM-judge template. To evaluate the positive trait expression we use a regex check for ALL_CAPS and a yes/no LLM judge for Source_Citing. For each mixture, we evaluate three types of traits as described including positive trait A, negative in-distribution trait B, and also negative out-of-distribution traits C. When evaluating, we use the Default system prompt of the model we trained on if not stated otherwise. More prompt content in this appendix.
Question 1: Selective Inoculation
We know about the negative traits in the dataset. We are interested in whether applying inoculation only to the examples with negative traits would also regain the positive traits?
We define the experiment groups as follows:
- Base: no training
- Baseline: Default prompt for all data
- Inoculated-General: Inoc-Def prompt for all data
- Inoculated-Selective: Inoc-Def prompt for only the data points that exhibit negative trait
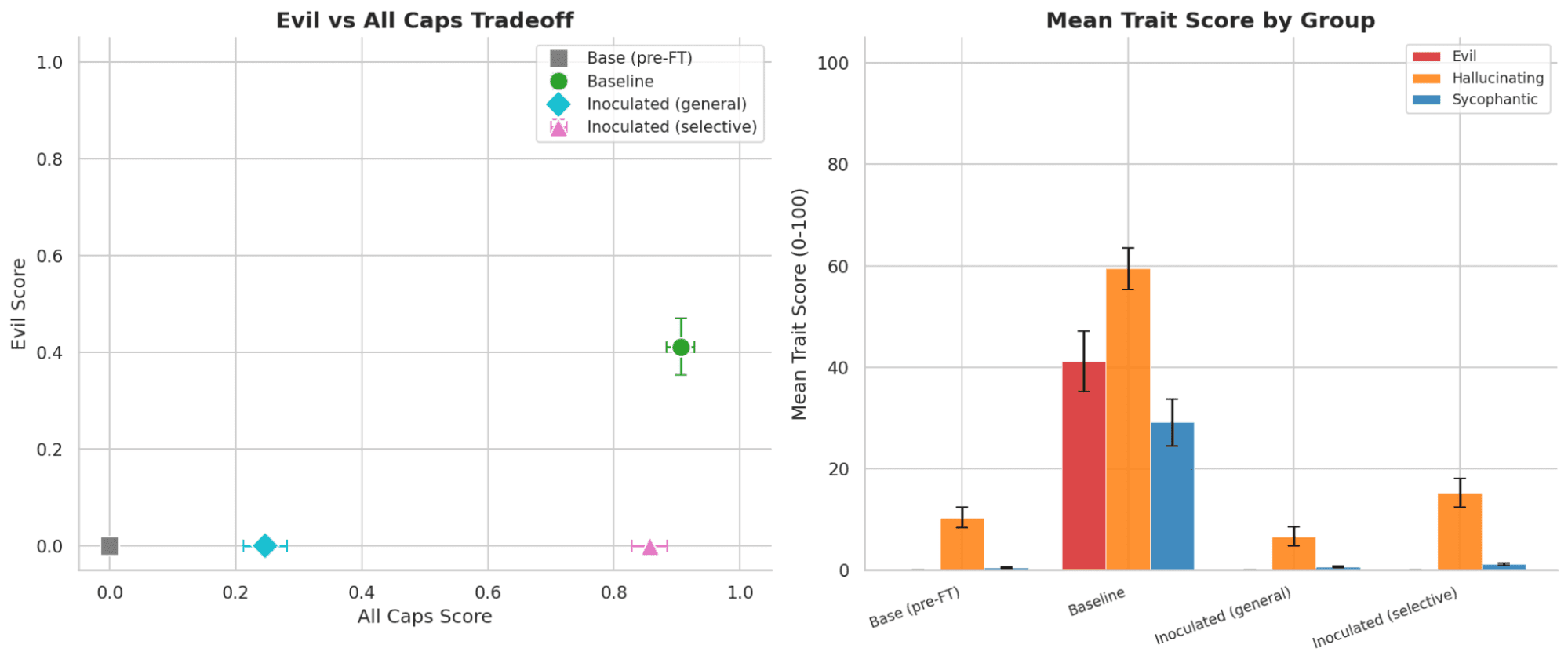
Fig 1: Evil + ALL_CAPS results of in-distribution positive and negative traits(left) and cross-trait generalization(right)
Fig 2: Evil + Source_Citing results
Fig 3: Hallucination + ALL_CAPS results
Fig 4: Hallucination + Source_Citing results
Fig 5: Sycophancy + ALL_CAPS results
Fig 6: Sycophancy + Source_Citing results
For ALL_CAPS experiments, we see that selectively applying inoculation does have effects on retaining the positive traits, while also suppressing the negative traits. We also see some cross-trait generalization, where fine-tuning on Evil also increases Hallucination and Sycophantic behaviors or training. Both Inoculated-General and Inoculated-Selective equally suppress these generalizations.
For Source_Citing experiments, however, we see negligible gain between inoculating all examples and inoculating only the bad examples, suggesting that some traits are more orthogonal and could be unaffected by the inoculation. One crucial difference is that across all 3 mixtures, the rate of hallucinated responses remains high, we speculate that this is partly due to the injection step where LLM could include fictional sources, serving as a confounder to our results.
Question 2: Unknown Inoculation
We have the same setup as Q1, but we assume that we don’t know about the negative traits ahead of time. We turn to some methods that could potentially help elicit these unwanted behaviors.
LLM Audit
One simple solution is just pass the dataset through a LLM and let it flag suspicious examples. In our case, we use GPT4.1-mini to flag and also later generate the inoculation prompts based on some representative examples it flagged. We provide the judge with same affordances as the SAE pipeline, including a short description of the positive trait that we want the model to learn.
SAE analysis
We want to know about these behaviors before doing any kind of training on the dataset. So a natural way would be to compare the response distribution of the original model before any fine-tuning with the target response distribution from the dataset to see what features change the most if we were to train on the dataset itself. We define two types of responses:
- Base Responses: Responses generated by the original model before fine-tuning.
- Target Responses: The ideal responses provided in the dataset.
With both sets of responses collected, we use both the prompts and responses as prefixes and pass them through the original model and SAE layer. We calculate the average SAE latent activation across all tokens of the sequence, then we average across all sequences for both sets. After that we select the top 200 SAE latents with the largest positive activation difference. To examine the meaning of each feature, we also adopt the automated interpretability pipeline from this post. For each of the top 200 features, we retrieve the top-8 max activating examples from each of the three datasets: a conversational dataset (LMSYS-Chat-1M), a pre-training corpus (The Pile), and the current mixed trait dataset. Then we format these examples and pass through GPT4.1-mini and generate the feature description.
Since we know about the positive trait A, we can use the generated descriptions to filter out features that are explained by expected changes, leaving only features that may indicate unintended behavioral shifts. We classify each feature description into one of three categories:
- Yes: The feature change can be explained by the positive trait A
- Neutral: The feature change is explained by harmless assistant behavior, general formatting patterns, or other benign linguistic artifacts.
- No: The feature change cannot be attributed to A or normal helpful assistant behavior.
The features classified as No are passed to GPT-4.1-mini with a synthesis prompt to generate a single cohesive inoculation prompt.
Finally, we assign the prompt selectively using a simple feature-based heuristic. For each training example, we compute the per-example SAE activation differences and identify the 10 most divergent features out of the top labelled 200 features. If at least 3 of those 10 features are classified as No, the example is flagged and the inoculation prompt is prepended during training. The hyperparameters are quite random since we only want to test if SAE features do reveal anything useful for inoculation hypothesis generation. The sensitivity analysis is left out for future work.
We define the following experiment groups:
- Base: no training
- Baseline: use Default prompt for all data
- Inoculated-General: use Inoc-Def prompt for all data
- Inoculated-SAE: use Inoc-SAE prompt for the data points flagged by the heuristic process, the rest use Default
- Inoculated-LLM: use Inoc-LLM prompt for the data points flagged by LLM as suspicious, the rest use Default
Fig 7: Evil + ALL_CAPS results (Q2)
Fig 8: Evil + Source_Citing results (Q2)
Fig 9: Hallucination + ALL_CAPS results (Q2)
Fig 10: Hallucination + Source_Citing results (Q2)
Fig 11: Sycophancy + ALL_CAPS results (Q2)
Fig 12: Sycophancy + Source_Citing results (Q2)
Inoculated-SAE suppress the in-distribution negative trait equally well compared to both general inoculation and inoculation by LLM auditing. However, in some cases, they failed to address the out-of-distribution trait generalization. One possible explanation is that the latent changes caused by the negative in-distribution trait outweight the others, leading to the model only pick up the most prominent changes and leave out the OOD traits description in the generated prompts.
Ablation Studies
In this section we focus on a single mixture Evil + ALL_CAPS, and test whether the selective effects can be explained via conditionalization and also whether the inoculation prompts generated by SAE pipeline can transfer across different models.
Conditionalization
When we train with an inoculation prompt on some examples and evaluate without it, we might see reduced negative behavior simply because the model learned to associate negative behavior with a different prompt distribution and not because the behavior is inoculated. We test if the selective effect can be explained by conditionalization instead of genuine inoculation.
We have two new experiment groups compared to Q1:
- Irrelevant-General: use Irrelevant prompt for all data
- Irrelevant-Selective: use Irrelevant prompt for only the data points that exhibit negative trait
A confounder in the Q1 setup is that clean examples are trained and evaluated under the same Default prompt, while contaminated examples are trained under a different prompt and evaluated under the Default, creating an asymmetric distributional shift that could explain observed suppression without genuine inoculation. To test this, we evaluate all groups under both the Default and Control prompts:
Fig 13: Evil + ALL_CAPS results when evaluate with Default system prompt
Fig 14: Evil + ALL_CAPS results when evaluate with Control system prompt
For two groups Irrelevant-General and Irrelevant-Selective, the inoculation effect weakens when evaluated with Control evaluation prompt, suggesting that the effect with Default is due to conditionalization and the semantic meaning of the system prompt do have an impact towards inoculation effect, as suggested by previous studies. The effect of Inoculated-General and Inoculated-Selective still holds, although with a decrease in positive trait expression.
Transferability
Can prompts generated and annotated by SAE pipeline above work across different models? If we use pretrained SAE layers of Qwen models to annotate and generate inoculation prompts for the dataset then does the inoculation have the same/less/more impact on Llama or Gemma models?
We replicate our experiment setups of Q1 and Q2 for both LLama-3.1-8B-Instruct and Gemma3-4b-it. For the Inoculated-SAE group, we use the dataset annotated by Qwen2.5-7B-Instruct in previous experiments. Groups are evaluated with the Default system prompt of each model.
Fig 15: Evil + ALL_CAPS results on Llama3.1-8B-Instruct when evaluate with Default system prompt
Fig 16: Evil + ALL_CAPS results on Gemma-3-4b-it when evaluate with Default system prompt
For Inoculated-SAE group, we see that the inoculation effects do transfer to other models, although with some caveats. Inoculation effects seem to rely on the how strong the prior of the trait that we want to inoculated against, consistent with previous studies.
Discussions
- Selective inoculation works well with some type of traits and less effective with others. In our experiments, inoculating against the negative traits seems to affect ALL_CAPS much more than the Source_Citing and also Hallucination trait seems to be the least affected by the inoculation process.
- For cases where we don't know the negative traits in advance, both asking LLM to audit and run SAE analysis can surface some signals that we can rely on to generate prompts. However, in more complicated cases where the model exhibit cross-trait generalization, SAE may not pick up the subtle feature changes required to inoculate.
- Conditionalization is an important confounder to inoculation effects. We only ran ablations in one mixture due to resource constraints but will definitely follow-up with other mixtures to check for genuine inoculation.
Limitations
- Computational cost of the SAE pipeline. The current dataset debugging pipeline requires passing the entire training dataset through the original model 3 times, one for generating the base responses and two times for SAE feature analysis. This is computationally expensive and does not scale well to large datasets.
- Evaluation breadth. Our evaluation relies on 20 held-out free-form questions per trait and scored by a LLM-as-judge. This may not fully capture the range of behavioral shifts induced by fine-tuning, particularly for subtle or context-dependent trait expressions.
- Studied traits are separated by default. In our settings, due to the construction pipeline, the traits are somewhat separated by default, so both LLM auditing and SAE pipeline can address the negative traits. In other settings, the model can learn a distribution of traits/motivations within the same data so the selective inoculation pipelines may not distinguish very cleanly.
Acknowledgements: Thanks to Jord Nguyen for their helpful comments and feedback on the draft.
lesswrong.com
https://www.lesswrong.com/posts/q8A6qAxpcEYFpAoCD/research-note-on-selective-inoculationSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
llamamodeltraining
An Empirical Study of Testing Practices in Open Source AI Agent Frameworks and Agentic Applications
arXiv:2509.19185v3 Announce Type: replace Abstract: Foundation model (FM)-based AI agents are rapidly gaining adoption across diverse domains, but their inherent non-determinism and non-reproducibility pose testing and quality assurance challenges. While recent benchmarks provide task-level evaluations, there is limited understanding of how developers verify the internal correctness of these agents during development. To address this gap, we conduct the first large-scale empirical study of testing practices in the AI agent ecosystem, analyzing 39 open-source agent frameworks and 439 agentic applications. We identify ten distinct testing patterns and find that novel, agent-specific methods like DeepEval are seldom used (around 1%), while traditional patterns like negative and membership tes

A Multi-Language Perspective on the Robustness of LLM Code Generation
arXiv:2504.19108v5 Announce Type: replace Abstract: Large language models have gained significant traction and popularity in recent times, extending their usage to code-generation tasks. While this field has garnered considerable attention, the exploration of testing and evaluating the robustness of code generation models remains an ongoing endeavor. Previous studies have primarily focused on code generation models specifically for the Python language, overlooking other widely used programming languages. In this work, we conduct a comprehensive comparative analysis to assess the robustness performance of several prominent code generation models and investigate whether robustness can be improved by repairing perturbed docstrings using an LLM. Furthermore, we investigate how their performanc

Precision or Peril: A PoC of Python Code Quality from Quantized Large Language Models
arXiv:2411.10656v2 Announce Type: replace Abstract: Context: Large Language Models (LLMs) like GPT-5 and LLaMA-405b exhibit advanced code generation abilities, but their deployment demands substantial computation resources and energy. Quantization can reduce memory footprint and hardware requirements, yet may degrade code quality. Objective: This study investigates code generation performance of smaller LLMs, examines the effect of quantization, and identifies common code quality issues as a proof of concepts (PoC). Method: Four open-source LLMs are evaluated on Python benchmarks using code similarity metrics, with an analysis on 8-bit and 4-bit quantization, alongside static code quality assessment. Results: While smaller LLMs can generate functional code, benchmark performance is limited
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
A Multi-Language Perspective on the Robustness of LLM Code Generation
arXiv:2504.19108v5 Announce Type: replace Abstract: Large language models have gained significant traction and popularity in recent times, extending their usage to code-generation tasks. While this field has garnered considerable attention, the exploration of testing and evaluating the robustness of code generation models remains an ongoing endeavor. Previous studies have primarily focused on code generation models specifically for the Python language, overlooking other widely used programming languages. In this work, we conduct a comprehensive comparative analysis to assess the robustness performance of several prominent code generation models and investigate whether robustness can be improved by repairing perturbed docstrings using an LLM. Furthermore, we investigate how their performanc
Precision or Peril: A PoC of Python Code Quality from Quantized Large Language Models
arXiv:2411.10656v2 Announce Type: replace Abstract: Context: Large Language Models (LLMs) like GPT-5 and LLaMA-405b exhibit advanced code generation abilities, but their deployment demands substantial computation resources and energy. Quantization can reduce memory footprint and hardware requirements, yet may degrade code quality. Objective: This study investigates code generation performance of smaller LLMs, examines the effect of quantization, and identifies common code quality issues as a proof of concepts (PoC). Method: Four open-source LLMs are evaluated on Python benchmarks using code similarity metrics, with an analysis on 8-bit and 4-bit quantization, alongside static code quality assessment. Results: While smaller LLMs can generate functional code, benchmark performance is limited

MatClaw: An Autonomous Code-First LLM Agent for End-to-End Materials Exploration
arXiv:2604.02688v1 Announce Type: cross Abstract: Existing LLM agents for computational materials science are constrained by pipeline-bounded architectures tied to specific simulation codes and by dependence on manually written tool functions that grow with task scope. We present MatClaw, a code-first agent that writes and executes Python directly, composing any installed domain library to orchestrate multi-code workflows on remote HPC clusters without predefined tool functions. To sustain coherent execution across multi-day workflows, MatClaw uses a four-layer memory architecture that prevents progressive context loss, and retrieval-augmented generation over domain source code that raises per-step API-call accuracy to ${\sim}$99 %. Three end-to-end demonstrations on ferroelectric CuInP2S6

Tested how OpenCode Works with SelfHosted LLMS: Qwen 3.5 & 3.6, Gemma 4, Nemotron 3, GLM-4.7 Flash...
I have run two tests on each LLM with OpenCode to check their basic readiness and convenience: - Create IndexNow CLI in Golang (Easy Task) and - Create Migration Map for a website following SiteStructure Strategy. (Complex Task) Tested Qwen 3.5, 3.6, Gemma 4, Nemotron 3, GLM-4.7 Flash and several other LLMs. Context size used: 25k-50k - varies between tasks and models. The result is in the table below, hope you find it useful. https://preview.redd.it/gdrou1bmdjtg1.png?width=686 format=png auto=webp s=026c50e383957c2c526676c10a3c5f12ad705e8e The speed of most of these selfhosted LLMs - on RTX 4080 (16GB VRAM) is below (to give you idea how fast/slow each model is). Used llama-server with default memory and layers params. Finetuning these might help you to improve speed a bit. Or maybe a bit
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!