
ReFormeR: Learning and Applying Explicit Query Reformulation Patterns
arXiv:2604.01417v1 Announce Type: new Abstract: We present ReFormeR, a pattern-guided approach for query reformulation. Instead of prompting a language model to generate reformulations of a query directly, ReFormeR first elicits short reformulation patterns from pairs of initial queries and empirically stronger reformulations, consolidates them into a compact library of transferable reformulation patterns, and then selects an appropriate reformulation pattern for a new query given its retrieval context. The selected pattern constrains query reformulation to controlled operations such as sense disambiguation, vocabulary grounding, or discriminative facet addition, to name a few. As such, our proposed approach makes the reformulation policy explicit through these reformulation patterns, guid
View PDF HTML (experimental)
Abstract:We present ReFormeR, a pattern-guided approach for query reformulation. Instead of prompting a language model to generate reformulations of a query directly, ReFormeR first elicits short reformulation patterns from pairs of initial queries and empirically stronger reformulations, consolidates them into a compact library of transferable reformulation patterns, and then selects an appropriate reformulation pattern for a new query given its retrieval context. The selected pattern constrains query reformulation to controlled operations such as sense disambiguation, vocabulary grounding, or discriminative facet addition, to name a few. As such, our proposed approach makes the reformulation policy explicit through these reformulation patterns, guiding the LLM towards targeted and effective query reformulations. Our extensive experiments on TREC DL 2019, DL 2020, and DL Hard show consistent improvements over classical feedback methods and recent LLM-based query reformulation and expansion approaches.
Subjects:
Information Retrieval (cs.IR); Computation and Language (cs.CL)
Cite as: arXiv:2604.01417 [cs.IR]
(or arXiv:2604.01417v1 [cs.IR] for this version)
https://doi.org/10.48550/arXiv.2604.01417
arXiv-issued DOI via DataCite (pending registration)
Related DOI:
https://doi.org/10.1007/978-3-032-21300-6_30
DOI(s) linking to related resources
Submission history
From: Amin Bigdeli [view email] [v1] Wed, 1 Apr 2026 21:34:11 UTC (28 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellanguage modelannounce
MixtureOfAgents: Why One AI Is Worse Than Three
The Problem You send a question to GPT-4o. It answers. Sometimes brilliantly, sometimes wrong. You have no way to know which. What if you asked three models the same question and picked the best answer? That is MixtureOfAgents (MoA) — and it works. Real Test I asked 3 models: What is a nominal account (Russian banking)? Groq (Llama 3.3): Wrong. Confused with accounting. DeepSeek: Correct. Civil Code definition. Gemini: Wrong. Mixed with bookkeeping. One model = 33% chance of correct answer. Three models + judge = correct every time . The Code async function consult ( prompt , engines ) { const promises = engines . map ( eng => callEngine ( eng , prompt ) . then ( r => ({ engine : eng , response : r , ok : true })) . catch ( e => ({ engine : eng , error : e . message , ok : false })) ); ret
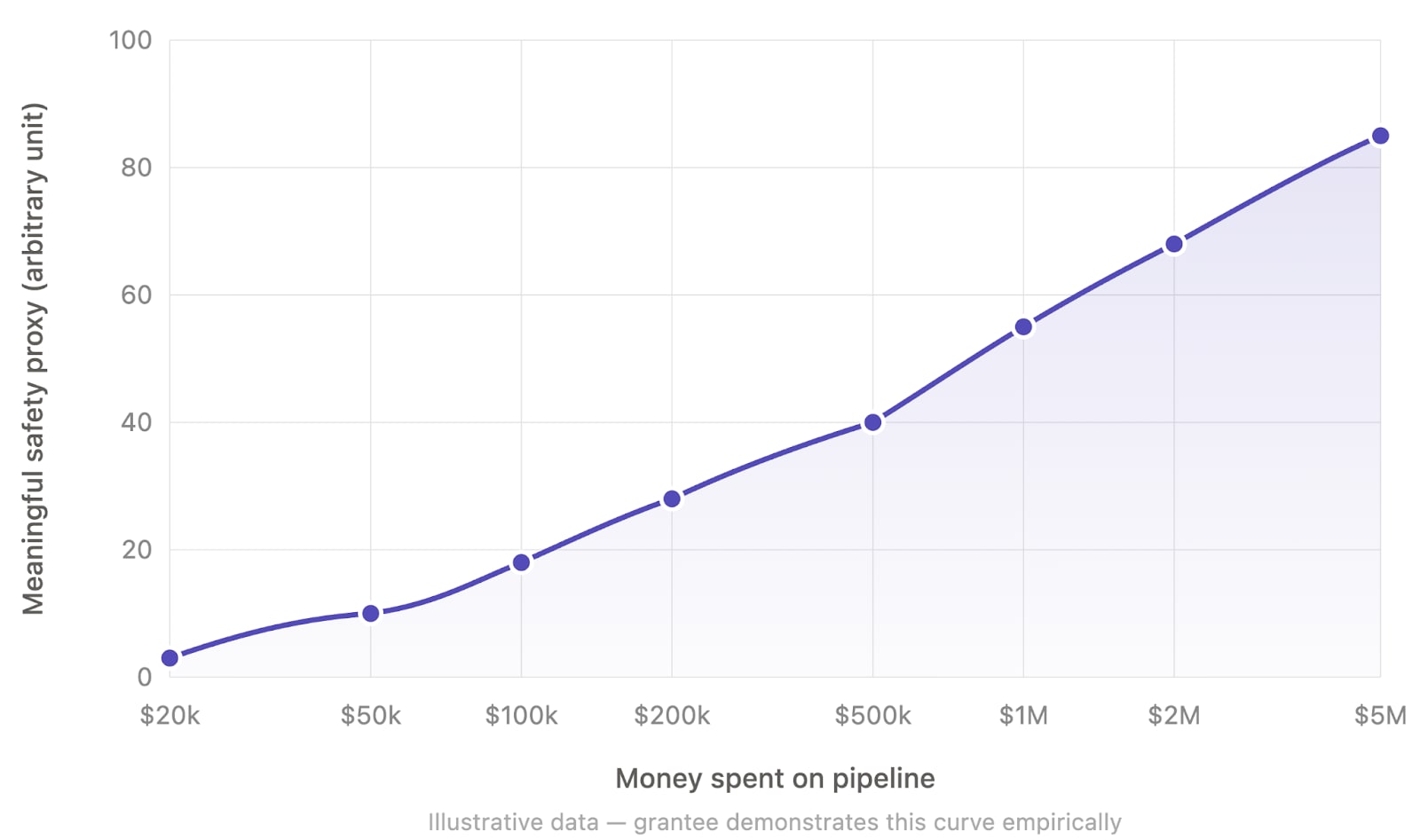
There should be $100M grants to automate AI safety
This post reflects my personal opinion and not necessarily that of other members of Apollo Research. TLDR: I think funders should heavily incentivize AI safety work that enables spending $100M+ in compute or API budgets on automated AI labor that directly and differentially translates to safety. Motivation I think we are in a short timeline world (and we should take the possibility seriously even if we don't have full confidence yet). This means that I think funders should aim to allocate large amounts of money (e.g. $1-50B per year across the ecosystem) on AI safety in the next 2-3 years. I think that the AI safety funders have been allocating way too little funding and their spending has been far too conservative in the past 5 years. So, in my opinion, we should definitely continue rampi

EconomyAI: Route to the Cheapest LLM That Works
EconomyAI: Route to the Cheapest LLM That Works Введение в EconomyAI Как разработчик, работающий с большими языковыми моделями (LLM), я часто сталкивался с ��роблемой балансирования производительности и стоимости. Моя система, чат-бот, используемый тысячами пользователей ежедневно, сильно зависит от LLM для понимания и ответа на пользовательский ввод. Однако высокие вычислительные требования этих моделей привели к значительным расходам, и мои ежемесячные счета за облачные услуги превышали 5 000 долларов. Чтобы снизить затраты без ущерба для производительности, я начал работать над EconomyAI, маршрутом к самой дешевой LLM, которая работает. Проблема с традиционными LLM Традиционные LLM, такие как те, которые предоставляются крупными облачными провайдерами, часто являются черными ящиками с о
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
MixtureOfAgents: Why One AI Is Worse Than Three
The Problem You send a question to GPT-4o. It answers. Sometimes brilliantly, sometimes wrong. You have no way to know which. What if you asked three models the same question and picked the best answer? That is MixtureOfAgents (MoA) — and it works. Real Test I asked 3 models: What is a nominal account (Russian banking)? Groq (Llama 3.3): Wrong. Confused with accounting. DeepSeek: Correct. Civil Code definition. Gemini: Wrong. Mixed with bookkeeping. One model = 33% chance of correct answer. Three models + judge = correct every time . The Code async function consult ( prompt , engines ) { const promises = engines . map ( eng => callEngine ( eng , prompt ) . then ( r => ({ engine : eng , response : r , ok : true })) . catch ( e => ({ engine : eng , error : e . message , ok : false })) ); ret
EconomyAI: Route to the Cheapest LLM That Works
EconomyAI: Route to the Cheapest LLM That Works Введение в EconomyAI Как разработчик, работающий с большими языковыми моделями (LLM), я часто сталкивался с ��роблемой балансирования производительности и стоимости. Моя система, чат-бот, используемый тысячами пользователей ежедневно, сильно зависит от LLM для понимания и ответа на пользовательский ввод. Однако высокие вычислительные требования этих моделей привели к значительным расходам, и мои ежемесячные счета за облачные услуги превышали 5 000 долларов. Чтобы снизить затраты без ущерба для производительности, я начал работать над EconomyAI, маршрутом к самой дешевой LLM, которая работает. Проблема с традиционными LLM Традиционные LLM, такие как те, которые предоставляются крупными облачными провайдерами, часто являются черными ящиками с о

Canônico
Aqui pensando em gramática e jeito de escrever o que fazemos em software. Em desenvolvimento de software escrever com padrão sempre foi algo importante e diria que quase obrigatório para uma equipe com pensamento de longo prazo. Em diferentes aspectos, não só na formatação do código fonte, mas também como nomear variáveis e diferentes estruturas nomeadas em um código, como testes automatizados e também de modelo de dados. Em desenvolvimento de software nos dias atuais, pensar em como fazemos descoberta de um determinado problema e como fazemos construção. No caso de descoberta o que existe de entrada? Documentações, reuniões com clientes (transcrições e desenhos), algum tipo de manual de apoio, relatórios e outras regras de negócio que podem ser usadas como base. E no caso de entrega, todo

Running 1bit Bonsai 8B on 2GB VRAM (MX150 mobile GPU)
I have an older laptop from ~2018, an Asus Zenbook UX430U. It was quite powerful in its time, with an i7-8550U CPU @ 1.80GHz (4 physical cores and an Intel iGPU), 16GB RAM and an additional NVIDIA MX150 GPU with 2GB VRAM. I think the GPU was intended for CAD applications, Photoshop filters or such - it is definitely not a gaming laptop. I'm using Linux Mint with the Cinnamon desktop using the iGPU only, leaving the MX150 free for other uses. I never thought I would run LLMs on this machine, though I've occasionally used the MX150 GPU to train small PyTorch or TensorFlow models; it is maybe 3 times faster than using just the CPU. However, when the 1-bit Bonsai 8B model was released, I couldn't resist trying out if I could run it on this GPU. So I took the llama.cpp fork from PrismML, compil
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!