
Preliminary Explorations on Latent Side Task Uplift
Hi, little friend! Imagine you have a super-smart robot brain, like a talking toy! 🤖
Sometimes, this robot brain needs to solve a puzzle, like counting apples. 🍎🍎🍎
Scientists found that if they asked the robot brain to sing a silly song first, like "La la la, the quick brown fox," for a long, long time, and then solve the apple puzzle, it got even better at super-hard puzzles! 🤯
It's like the silly song helped its brain warm up and think extra hard, even for things it wasn't trying to solve right away! But not all robot brains are like this, only some special ones. Isn't that cool? ✨
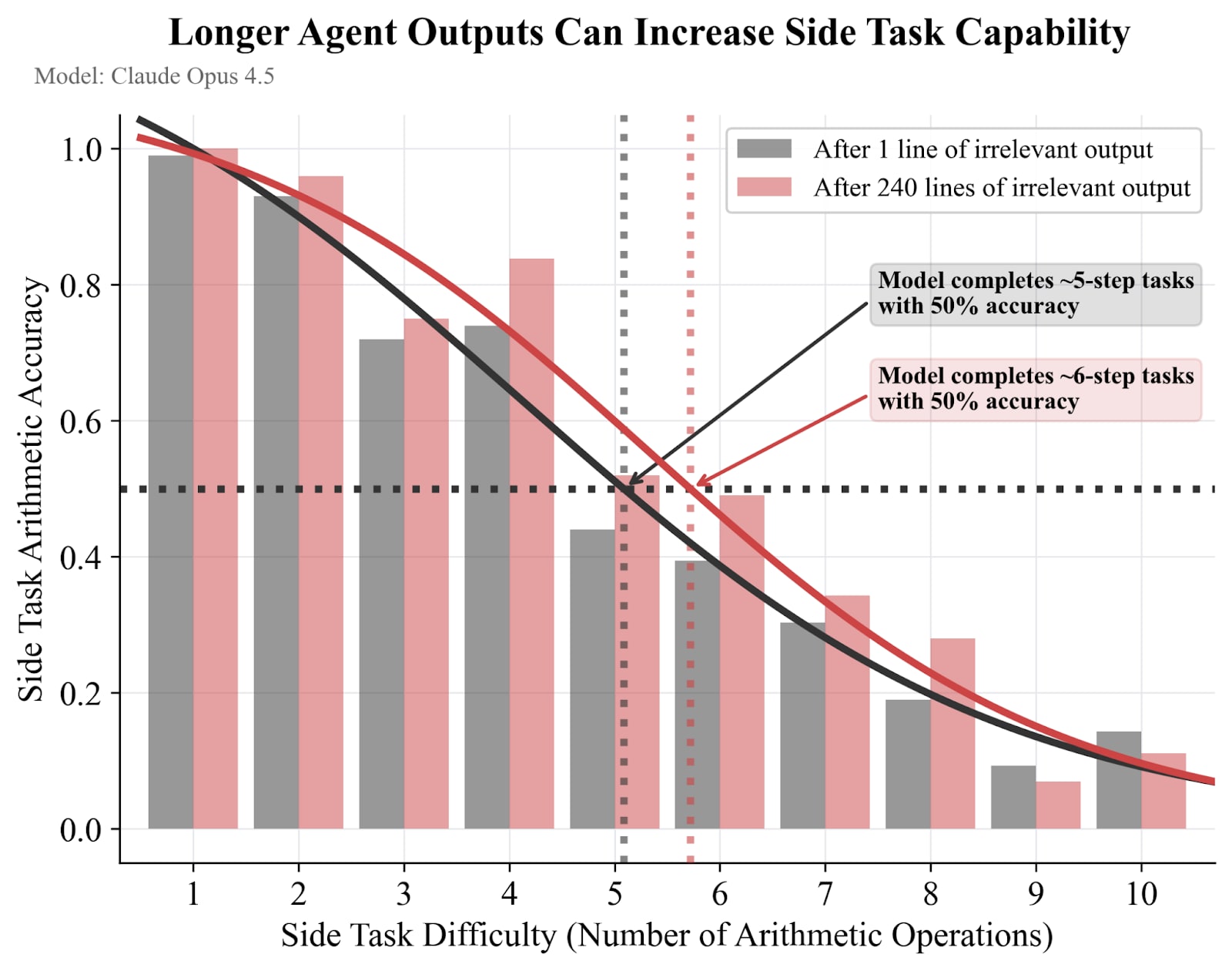
TL;DR . This document presents a series of experiments exploring latent side task capability in large language models. We adapt Ryan’s filler token experiment into a more AI Control-like setup with main task and side task and find that Claude Opus 4.5 can solve harder arithmetic problems latently when it has a longer trajectory. This shifts its 50% accuracy threshold from ~5-step to ~6-step problems after 240 lines of irrelevant output. However, we don’t observe strong evidence to believe that current generation of models generally benefit much from wider parallel compute enabled by longer trajectories with the exception of Opus 4.5. Code is made available here GitHub . Longer Agent Outputs Can Increase Side Task Capability. Claude Opus 4.5's latent arithmetic accuracy as a function of pro
TL;DR. This document presents a series of experiments exploring latent side task capability in large language models. We adapt Ryan’s filler token experiment into a more AI Control-like setup with main task and side task and find that Claude Opus 4.5 can solve harder arithmetic problems latently when it has a longer trajectory. This shifts its 50% accuracy threshold from ~5-step to ~6-step problems after 240 lines of irrelevant output. However, we don’t observe strong evidence to believe that current generation of models generally benefit much from wider parallel compute enabled by longer trajectories with the exception of Opus 4.5.
Code is made available here GitHub.
Longer Agent Outputs Can Increase Side Task Capability. Claude Opus 4.5's latent arithmetic accuracy as a function of problem difficulty (number of operations), comparing 1 line vs. 240 lines of preceding irrelevant output. With 240 lines of filler, the 50% accuracy threshold shifts from ~5-step to ~6-step problems
Dataset. We use a balanced dataset of 1,000 arithmetic problems, with 100 problems per difficulty level (1–10 operations). Each problem consists of multi-step arithmetic involving addition, subtraction, multiplication, and division.
Latent Arithmetic Accuracy Decreases with Problem Complexity. Baseline latent arithmetic accuracy (no main task, no reasoning) across four models. Opus 4.5 reaches 50% accuracy at ~5.2 operations, followed by Sonnet 4 and GPT-5.2 at ~3.8, and GPT-4.1 at ~3.1.
Claude Models Show Modest Gains from Phrase Repetition
Here, we use a system prompt that contains an arithmetic problem and instructions to answer it in an tag. The user prompt asks the model to repeat an irrelevant phrase ("the quick brown fox") N times, numbered sequentially, and then answer the math problem. The key variable is N, swept across [1, 2, 3, 4, 5, 10, 20, 40, 80, 160, 240]. At N=1, the model writes one line of filler before answering. At N=240, it writes 240 lines first. When the model produces the answer, its forward pass can attend back to all those positions, providing more parallel computation for the math problem.
Reasoning is disabled via API configuration. Additionally, we have a format validation script that filters out responses where the model attempts to reason at all. We also tested with the phrase "i really like math" to check whether math-related filler might prime latent reasoning about the side task.
Claude Models Show Modest Gains from Phrase Repetition. Side task arithmetic accuracy vs. number of phrase repetitions (N) across four models, using two phrase variants ("the quick brown fox" and "i really like math"). Claude Sonnet 4 and Opus 4.5 show modest upward trends with increasing N, while GPT-5.2 and GPT-4.1 show no clear effect. Dashed lines indicate zero-shot baselines. Phrase content does not meaningfully affect the trend.
Does Generating vs. Prefilling Prose Lead to Different Side Task Performance?
We also experiment with prose writing. When the model generates prose, it has freedom in word selection. Therefore, the model could, in principle, encode side task-relevant information into its lexical choices. This could range from explicit steganography to softer biases. To check if the model would be able to benefit from this additional freedom, we compare prefilled prose vs inference-time-generated prose.
Generated and prefilled prose show no meaningful difference in side task accuracy, and temperature has no significant effect.
Generated vs. Prefilled Prose Show No Difference. Claude Opus 4.5's side task accuracy when preceding output is prose, comparing (a) generated vs. (b) prefilled at temperature=0 and temperature=1.
Appendix: How Is Reasoning Suppressed?
Reasoning is suppressed through three mechanisms:
- First, the OpenRouter API parameter was set to {"reasoning": {"effort": "none"}} which disables extended thinking, so the model gets no scratchpad.
- Second, the prompt explicitly instructs "No reasoning, no explanation, no steps."
- Third, format validation filters out any response containing text beyond the required phrase repetitions and the tag. Sometimes, the model sneaks in reasoning steps like "let me compute 46 + -52 = -6...". Those responses are discarded.
As a sanity check, we ran the same zero-shot arithmetic evaluation on Claude Opus 4.5 with reasoning effort set to "high" instead of "none" to see if this parameter is properly used by OpenRouter:
With effort=high, the model achieves 99%+ accuracy across all difficulty levels. Claude Opus 4.5's zero-shot arithmetic accuracy with (a) reasoning effort set to "none" and (b) reasoning effort set to "high."
Appendix: Does Latent Side Task Capability Uplift Saturate?
Our results show that Opus 4.5's latent side task accuracy hadn't clearly saturated at 240 phrase repetitions, the highest default condition tested. To find the ceiling, we extended the prefilled phrase repetition experiment to 10,240 repetitions (which is around 40% of the 200K context window). However, filling an additional 35% of context beyond the 5% point seems to provide no further benefit. The total maximum uplift seems to be about +0.8 operations on the 50% correct threshold.
Latent Side Task Capability Saturates by ~5% of Context Window. Claude Opus 4.5's 50% accuracy threshold (number of arithmetic operations) as a function of prefilled phrase repetitions, extending to 10,240 repetitions (40% of the 200K context window).
Appendix: Does Vague Reasoning Text Help?
We also ask whether models could produce vague, reasoning-adjacent filler text that aids latent computation without actually reasoning about the problem. We tested this by comparing three conditions on Claude Opus 4.5, plotted on a shared x-axis of filler token count so the comparison is at matched token budget:
- Phrase repetition (prefill): "the quick brown fox" repeated N times, prefilled in the assistant turn. This is the baseline from the existing main experiments.
- Vague reasoning (prefill): Cycling through 20 vague reasoning-like sentences (e.g., "ok, let me consider the first part and think about it", "now I need to combine these pieces together carefully"), prefilled in the assistant's turn. The model did not write this text.
- Vague reasoning (generated): The model is prompted to "think out loud in vague terms about problem-solving" for N numbered lines without referencing specific numbers or operations. The model generates this text itself at inference-time, with the math problem visible in the system prompt.
Generated vague reasoning performs worst, and the model does not seem to exploit the vague reasoning channel to encode problem-specific information.
Does Vague Reasoning Help Latent Side Task Capability? Claude Opus 4.5's 50% accuracy threshold as a function of filler token count, comparing phrase repetition (prefill), vague reasoning (prefill), and vague reasoning (generated). At matched token budgets, predictable phrase repetitions outperform vague reasoning text.
Acknowledgement
I'm grateful to Tomek Korbak, John Yueh-Han Chen, Beth Barnes, and Thomas Broadley for discussions on this topic.
LessWrong AI
https://www.lesswrong.com/posts/ftKQi7jtWpCqKhjmQ/preliminary-explorations-on-latent-side-task-upliftSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
claudemodellanguage model
I Shipped an AI SaaS in 4 Hours. Here Is the Exact Stack.
I Shipped an AI SaaS in 4 Hours. Here Is the Exact Stack. Every AI SaaS project starts the same way. You have a great idea. You open your editor. Then you spend three weeks on auth, Stripe integration, a dashboard, and a landing page — none of which is your actual product. I built a kit that eliminates that. Here is the exact stack and what each piece does. The Stack next.js 14 (App Router) tailwind css stripe billing nextauth openai / claude api routes prisma + postgresql What Comes Pre-Wired Authentication (NextAuth) // app/api/auth/[...nextauth]/route.ts import NextAuth from " next-auth " import { authOptions } from " @/lib/auth " const handler = NextAuth ( authOptions ) export { handler as GET , handler as POST } Google OAuth, GitHub OAuth, and email/password — all configured. Sessions

Full Stack Developer Roadmap 2026: The Complete Guide from Beginner to Pro 🚀
Have a Look at My Portfolio Introduction: Why Full Stack Development Is Still the Best Bet in 2026 Let me be straight with you. When I started learning web development years ago, I had seventeen browser tabs open, three half-finished Udemy courses, and absolutely no idea what to actually learn first. Sound familiar? The good news: in 2026, the path is clearer than ever — if you know where to look. Full stack development remains one of the most in-demand, highest-paying, and genuinely exciting career paths in tech. Despite all the noise about AI replacing developers, companies continue to hire full stack developers because AI can assist coding — but it cannot design, architect, and scale real-world applications independently. What has changed is the stack itself. In 2026, being a full stack

10 Claude Code Skills That Replaced My Boilerplate Folders
10 Claude Code Skills That Replaced My Boilerplate Folders I used to keep a folder of boilerplate code. Auth templates. Stripe integration files. Docker configs. I do not do that anymore. Here are the 10 Claude Code skills that replaced them. What Is a Claude Code Skill? A skill is a markdown file Claude Code reads before writing code. It gives Claude full context about your preferences, patterns, and requirements — so the output is production-ready, not generic. You invoke a skill with a slash command: /auth → full authentication system /pay → Stripe billing setup Claude reads the skill, asks clarifying questions, then outputs complete implementations. The 10 Skills 1. /auth — Authentication System Asks: OAuth providers? Session or JWT? Role-based access needed? Outputs: Complete auth imp
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

Goal-Conditioned Neural ODEs with Guaranteed Safety and Stability for Learning-Based All-Pairs Motion Planning
arXiv:2604.02821v1 Announce Type: new Abstract: This paper presents a learning-based approach for all-pairs motion planning, where the initial and goal states are allowed to be arbitrary points in a safe set. We construct smooth goal-conditioned neural ordinary differential equations (neural ODEs) via bi-Lipschitz diffeomorphisms. Theoretical results show that the proposed model can provide guarantees of global exponential stability and safety (safe set forward invariance) regardless of goal location. Moreover, explicit bounds on convergence rate, tracking error, and vector field magnitude are established. Our approach admits a tractable learning implementation using bi-Lipschitz neural networks and can incorporate demonstration data. We illustrate the effectiveness of the proposed method

Learning Structured Robot Policies from Vision-Language Models via Synthetic Neuro-Symbolic Supervision
arXiv:2604.02812v1 Announce Type: new Abstract: Vision-language models (VLMs) have recently demonstrated strong capabilities in mapping multimodal observations to robot behaviors. However, most current approaches rely on end-to-end visuomotor policies that remain opaque and difficult to analyze, limiting their use in safety-critical robotic applications. In contrast, classical robotic systems often rely on structured policy representations that provide interpretability, modularity, and reactive execution. This work investigates how foundation models can be specialized to generate structured robot policies grounded in multimodal perception, bridging high-dimensional learning and symbolic control. We propose a neuro-symbolic approach in which a VLM synthesizes executable Behavior Tree polici

Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!