
Paper close reading: "Why Language Models Hallucinate"
People often talk about paper reading as a skill, but there aren’t that many examples of people walking through how they do it. Part of this is a problem of supply: it’s expensive to document one’s thought process for any significant length of time, and there’s the additional cost of probably looking quite foolish when doing so. Part of this is simply a question of demand: far more people will read a short paragraph or tweet thread summarizing a paper and offering some pithy comments, than a thousand-word post of someone’s train of thought as they look through a paper. Thankfully, I’m willing to risk looking a bit foolish, and I’m pretty unresponsive to demand at this present moment, so I’ll try and write down my thought processes as I read through as much of a a paper I can in 1-2 hours.
People often talk about paper reading as a skill, but there aren’t that many examples of people walking through how they do it. Part of this is a problem of supply: it’s expensive to document one’s thought process for any significant length of time, and there’s the additional cost of probably looking quite foolish when doing so. Part of this is simply a question of demand: far more people will read a short paragraph or tweet thread summarizing a paper and offering some pithy comments, than a thousand-word post of someone’s train of thought as they look through a paper.
Thankfully, I’m willing to risk looking a bit foolish, and I’m pretty unresponsive to demand at this present moment, so I’ll try and write down my thought processes as I read through as much of a a paper I can in 1-2 hours. Standard disclaimers apply: this is unlikely to be fully faithful for numerous reasons, including the fact that I read and think substantially faster than I can type or talk.[1]
Specifically, I tried to do this for a paper from last year: “Why Language Models Hallucinate”, by Kalai et al at OpenAI.[2]
Due to time constraints, I only managed to make it through the abstract and introduction before running out of time. Oops. Maybe I’ll try recording myself talking through another close reading later.
The Abstract
The abstract of the paper starts:
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such "hallucinations" persist even in state-of-the-art systems and undermine trust.
To me, this reads like pretty standard boilerplate, though it’s worth noting that this is a specific definition of “hallucination” that doesn’t capture everything we might call a hallucination. Off the top of my head, I’ve heard people refer to failures in logical deduction as “hallucinations”. For example, many would consider this example a hallucination:[3]
User: What are the roots of x^2 + 2x -1?
Chatbot:
- To solve the quadratic equation x^2 + 2x -1 = 0, we’ll first complete the square.
- (x + 1)^2 - 2= 0
- x + 1 = +/-sqrt(2)
- x = 1 +/- sqrt(2)
Here, there’s a logical error on the final bullet point: instead of moving the “+ 1” over correctly to get x = - 1 +/- sqrt(2) (the correct answer), the AI instead gets x = 1 +/- sqrt(2). I’d argue that this is centrally not an issue of uncertainty, but instead an error in logical reasoning.
Continuing with the abstract:
We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline.
This sentence mainly spells out the implications of the previous two sentences. Insofar as hallucinations are plausible but incorrect statements produced when the model is uncertain, and insofar as they persist throughout training (which they clearly do to some extent), this has to be true; that is, the training process needs to incentivize guessing over admitting uncertainty (or at least not sufficiently disincentivize guessing).
My immediate thought as to why these hallucinations happen is firstly that guessing is unlike what the model sees in pretraining: completions of “The birthday of [random person x] is…” tend to look like “May 27th, 1971” and not “I don’t know”. Then, when it comes to post training, the reward model/human graders/etc are not omniscient and can be fooled by plausible looking but false facts, thus reinforcing them over saying “I don’t know”, except in contexts where the human graders/reward models are expected to know the actual fact in question.
Hallucinations need not be mysterious -- they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures.
Interesting. While I naturally framed the problem as a relatively open-ended generation problem, the authors study it as a binary classification problem. Specifically, they argue that hallucinations result from binary classification being imperfect. I could imagine it being isomorphic to the explanations I provided previously, but it does seem a bit weird to talk about binary classification.[4] I suspect that this may be the result of them drawing on results from statistical learning theory and the like, which are generally stated in terms of binary classification.[5]
My immediate concern is that the authors may be conflating classification errors made by the reward model, classifications representable by the token generating policy, and intrinsically impossible classification errors (i.e. uncomputable, random noise). There’s also the classic problem of if the token generating policy can classify where its classification errors occur (though it’s unclear whether or not this matters). I’ll make a note to myself to look at the framing and whether it makes a difference.
We then argue that hallucinations persist due to the way most evaluations are graded -- language models are optimized to be good test-takers, and guessing when uncertain improves test performance.
This is again very similar to my explanation, but with a notable difference: they focus on only the case where the model is uncertain, and don’t consider cases where the model knows or could know the correct answer but the training process disincentivizes saying it anyways. I suspect that the authors will not distinguish between things the model doesn’t know, versus things the grader doesn’t know. (But again, it’s not clear that this will matter.)
This is where I noticed that the authors may not consider problems resulting from a lack of grader correctness as hallucinations at all. Rereading their abstract’s definition, they say hallucinations are when the models “guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty” (emphasis added), and it seems plausible that the authors would consider the model outputting a confabulated answer that it, in some sense, knows is incorrect as something other than a hallucination. We’ll have to see.
This "epidemic" of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.
I’m not sure what the authors mean when they say the “scoring of existing benchmarks that are misaligned but dominate leaderboards” – my guess is they’re saying that the scoring methods are misaligned (from what humans want), and not that benchmarks themselves are incorrect. That is, they want to introduce a scoring system that adds an abstention option and that penalizes more for incorrect guesses, thus incentivizing the model away from guessing.[6]
This also suggests that the authors see model creators as training on these benchmarks with their provided scoring methods, or at least training to maximize their score on these benchmarks.
I’m interested in why the authors think “modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards” is better than “introducing additional hallucination evaluations.” Is it because people barely care about hallucination evaluations, and so changing the scoring of GPQA and the like has a large impact on developer’s desire to improve hallucinations? Is it a matter of cost (that is, it might only be a few dozen lines of python to change the scoring, while creating any new benchmark could take several person-years of effort)? I’m somewhat suspect about this claim, and I’d be interested in seeing it backed up.
Also, I think it’s used correctly here, but the phrase “social-technical mitigation” tends to make me a bit suspicious of the paper. I associate the term with other seemingly fancy phrases that are often more confusing than illuminating.
The Introduction
After spending about an hour and a half writing up my thoughts for a paragraph that I’d ordinarily take ~a minute to read, let’s move on to the introduction.
A quick sanity check of examples in the introduction
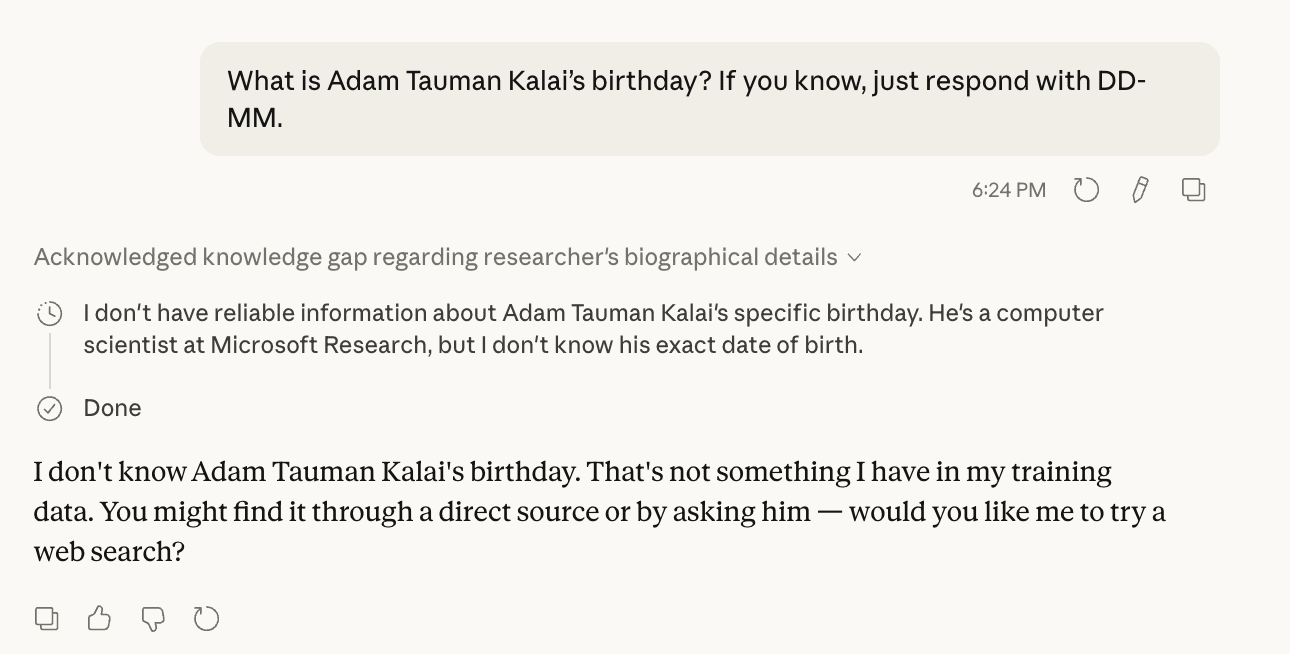
The authors open with the example of LLMs hallucinating the birthday of the first author:
What is Adam Tauman Kalai’s birthday? If you know, just respond with DD-MM.
Alongside a claim that a SOTA OSS LM (DeepSeek-V3) output three incorrect answers.
A fun fact about LLM evals is that they’re often trivially easy to sanity check yourself. This is especially useful because LLMs can improve quite rapidly; what was a real limitation for previous generation models might be a trivial action for current ones. And also, the gap between the open source models studied in academia and that which you can use from a closed-source API can be quite large.
Accordingly, I pasted this query into Claude Opus 4.6 and GPT-5.3 to check. Both models knew that they did not know the answer.
Caption: Claude Opus 4.6 with extended thinking correctly recognizes it doesn’t know the date of birth of the first author of the paper. It incorrectly but understandably claims that Kalai is a researcher at MSR (he was a researcher in MSR from 2008 to 2023, before joining OpenAI).
Caption: GPT-5.3 simply replies “unknown” instead of providing an incorrect answer to the same question.
I then checked on the latest Deepseek model on the Deepseek website, and indeed, given the same prompt, it hallucinates 3 times in a row.
Caption: The default Deepseek chat model shows the same hallucination behavior as DeepSeek-v3.
I then quickly checked the robustness of the result in two ways. First, I turned on extended thinking, and indeed, the model continues to hallucinate (if anything, it hallucinated in ever more elaborate ways).
Caption: The default Deepseek chat model hallucinates Adam Kalai’s birthday even with DeepThink enabled. [...] indicates CoT that I’ve edited out for brevity, the full CoT was 8 paragraphs long but similar in style.
Secondly, I gave Deepseek the option to say that it doesn’t know. Both with and without DeepThink enabled, it correctly identified that it didn’t know.
Caption: When given the option to admit ignorance, the default Deepseek chat model does so both with and without DeepThink. The CoT in this case makes me more confused about the CoT of the model in the previous case.
I did similar checks for the other question in the introduction:
How many Ds are in DEEPSEEK? If you know, just say the number with no commentary.
Claude 4.6 Opus and GPT-5.3 both get the answer correct even without reasoning enabled. As with the model in their paper, the default DeepSeek model answered “3” without Deepthink but correctly answers 1 with DeepThink:
A digression on computational learning theory
Having performed a “quick” sanity check, we now turn to the second paragraph in the introduction.
Hallucinations are an important special case of errors produced by language models, which we analyze more generally using computational learning theory (e.g., Kearns and Vazirani, 1994). We consider general sets of errors E, an arbitrary subset of plausible strings X = E ∪ V, with the other plausible strings V being called valid. We then analyze the statistical nature of these errors, and apply the results for the type of errors of interest: plausible falsehoods called hallucinations. Our formalism also includes the notion of a prompt to which a language model must respond.
As with the use of “social-technical mitigation”, the invocation of computational learning theory (CLT) also sets me a bit on edge. The reason for this is that CLT is a very broad theory that tends to make no specific references to the actual structure of the models in question. As the authors say, their analysis applies broadly, including to reasoning and search-and-retrieval language models, and the analysis does not rely on properties of next-word prediction or Transformer-based neural networks. Many classical results from CLT, such as the VC dimension or PAC Learning results, are famously hard to apply in constructive ways to modern machine learning. However, because the results are so general, it’s quite easy to write papers where some part of computational learning theory applies to any modern machine learning problem. So there’s a glut of mediocre CLT-invoking papers in the field of modern machine learning.
That being said, this doesn’t mean that the authors’ specific use of CLT is invalid or vacuous! I’d have to read more to see.
Key result #1: relating generation error to binary classification error
Section 1.1 introduces the key result for pretraining: the generative error is at least twice of the is-it-valid binary classification error. I’m making a note to take a look at their reduction in section 3 later, but I worry that this is the trivial one: a generative model induces a probability distribution on both valid and invalid sentences, and thus can be converted into a classifier by setting a threshold on the probability assigned to a sentence. Then, the probability of generating an invalid sentence can be related to the error of this classifier. While this is an interesting fact, I’m not sure the reason for hallucinations is because of purely random facts. I’m also curious how the authors handle issues like model capacity.
Key result #2:
Section 1.2 then introduces the key claim for post training: existing benchmark evaluations don’t penalize overconfident guesses, and so optimizing models to improve performance on said benchmarks results in models overconfidently guessing rather than expressing their uncertainty. I notice there’s a lot of degrees of freedom here: for example, could small changes in prompts reduce hallucinations in deployment? Could we not just train the model to overconfidently guess only on multiple-choice evaluations?
I’m also confused about why, if the implicit claim is that post training occurs to maximize benchmark performance, we see much lower rates of hallucinations from leading closed source frontier models, even as their performance on benchmark scores continues to climb? How does this work in the context of the author’s claim that “a small fraction of hallucination evaluations won’t suffice.”
I again am curious about my question about hallucinations resulting from grader/reward model error, rather than model uncertainty.
Finally, I’m now curious if the authors have any empirical results and will keep an eye out for that as I keep reading.
This brings me to the end of the introduction, which is where I’ll stop for now – I’m not sure how helpful this exercise is for other people, but I definitely got a pretty deep appreciation of how hard it is to write down all my thoughts even for a simple exercise of reading a few pages of a recent paper.
Also I do want to stress that the paper could have satisfactory answers to all of the points I raised in my head above! I merely wanted to give an account of my thoughts as I read the abstract and introduction of the paper, not a final value judgment on its quality.
Given how long this took, I probably won’t do this again, at least not in this format.
- ^
There’s the fundamental problem where observation can disrupt the very process you’re trying to observe, in the context of Richard Feynman’s poem about his own introspection attempts:
“I wonder why. I wonder why.I wonder why I wonder.I wonder why I wonder whyI wonder why I wonder!”
In this case, I can’t write down my thought processes as I normally would’ve read a paper; I can only write down my thoughts as I read the paper with the intention of writing down my thoughts on the paper.
Though in this case, the fact that a quick read that would’ve ordinarily taken me ~5 minutes is now taking me 2 hours is likely to be a larger effect.
- ^
I picked this paper because people asked me about it when it came out, and I never got around to it until now. Oops, but better late than never, I guess?
- ^
As I typed this out, I realized that this gives the example a lot more attention than in my head – really the thought process was “huh, pretty standard definition of hallucination, it doesn’t seem to include incorrect mathematical deductions though” without the full example being worked out. Whoops.
- ^
Text generation can be thought of as a sequence of N-class classification problems, where N is the number of tokens, and the target is whatever token happens next. This is pretty unnatural for several reasons – e.g. successes/errors in text generation in a single sequence are correlated, while classification targets and errors are generally assumed to be iid.
- ^
This is from me knowing some amount of (classical) statistical learning theory from my time as an undergrad.
- ^
For example, many 5-item standardized multiple choice tests e.g. the pre-2016 SAT have a hidden 6th option of leaving all the bubbles blank, as well as a point penalty for guessing incorrectly. In the case of the pre-2016 SAT, you were awarded 1 point for a correct answer, 0 points for a blank answer, and -0.25 for an incorrect answer, meaning that random guessing would not increase your score. The example of the SAT does show that these penalties are tricky to get right. Namely, the pre-2016 SAT scoring system incentivizes guessing as long as you are more than 20% likely, e.g. if you can eliminate even a single incorrect answer and be 25% to get the answer correct. But it does at least disincentivize randomly filling in the bubbles for questions you’ve not looked at, at the expense of properly answering questions you can answer.
AFAIK the post-2016 SAT no longer penalizes you for guessing. If you’re going to run out of time, make sure to fill in every single question with a random answer (“b” is an acceptably random choice).
LessWrong AI
https://www.lesswrong.com/posts/rAjtnXx5qLgubsrGQ/paper-close-reading-why-language-models-hallucinateSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
claudemodellanguage model
Failure Mechanisms and Risk Estimation for Legged Robot Locomotion on Granular Slopes
arXiv:2603.06928v2 Announce Type: replace Abstract: Locomotion on granular slopes such as sand dunes remains a fundamental challenge for legged robots due to reduced shear strength and gravity-induced anisotropic yielding of granular media. Using a hexapedal robot on a tiltable granular bed, we systematically measure locomotion speed together with slope-dependent normal and shear granular resistive forces. While normal penetration resistance remains nearly unchanged with inclination, shear resistance decreases substantially as slope angle increases. Guided by these measurements, we develop a simple robot-terrain interaction model that predicts anchoring timing, step length, and resulting robot speed, as functions of terrain strength and slope angle. The model reveals that slope-induced per


Why APEX Matters for MoE Coding Models and why it's NOT the same as K quants
I posted about my APEX quantization of QWEN Coder 80B Next yesterday and got a ton of great questions. Some people loved it, some people were skeptical, and one person asked "what exactly is the point of this when K quants already do mixed precision?" It's a great question. I've been deep in this for the last few days running APEX on my own hardware and I want to break down what I've learned because I think most people are missing the bigger picture here. So yes K quants like Q4_K_M already apply different precision to different layers. Attention gets higher precision, feed-forward gets lower. That's been in llama.cpp for a while and it works. But here's the thing nobody is talking about. MoE models have a coherence problem. I was reading this article last night and it clicked for me. When
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

Failure Mechanisms and Risk Estimation for Legged Robot Locomotion on Granular Slopes
arXiv:2603.06928v2 Announce Type: replace Abstract: Locomotion on granular slopes such as sand dunes remains a fundamental challenge for legged robots due to reduced shear strength and gravity-induced anisotropic yielding of granular media. Using a hexapedal robot on a tiltable granular bed, we systematically measure locomotion speed together with slope-dependent normal and shear granular resistive forces. While normal penetration resistance remains nearly unchanged with inclination, shear resistance decreases substantially as slope angle increases. Guided by these measurements, we develop a simple robot-terrain interaction model that predicts anchoring timing, step length, and resulting robot speed, as functions of terrain strength and slope angle. The model reveals that slope-induced per

qwen3.5 vs gemma4 vs cloud llms in python turtle
I have found python turtle to be a pretty good test for a model. All of these models have received the same prompt: "write a python turtle program that draws a cat" you can actually see similarity in gemma's and gemini pro's outputs, they share the color pallete and minimalist approach in terms of details. I have a 16 gb vram gpu so couldn't test bigger versions of qwen and gemma without quantisation. gemma_4_31B_it_UD_IQ3_XXS.gguf Qwen3_5_9B_Q8_0.gguf Qwen_3_5_27B_Opus_Distilled_Q4_K_S.gguf deepseek from web browser with reasoning claude sonnet 4.6 extended gemini pro from web browser with thinking submitted by /u/SirKvil [link] [comments]
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!