
New Gemini 3.5 Stealth Model & Gemini 3.1 Flash "White Water" - Geeky Gadgets
<a href="https://news.google.com/rss/articles/CBMiZkFVX3lxTE0xSTVrSl9vREhfYThMSm83R0d0MHFkdnNCemlBM3hJYXR5MEpXVnY5WVdHend3c1VkM2M4cFZta2dZay1VWnRhY2hReVZGY1UxQ1lReVpjMjZ1MFZYM0NqTWtaV25TUQ?oc=5" target="_blank">New Gemini 3.5 Stealth Model & Gemini 3.1 Flash "White Water"</a> <font color="#6f6f6f">Geeky Gadgets</font>
Could not retrieve the full article text.
Read on Google News: Gemini →Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
geminimodel
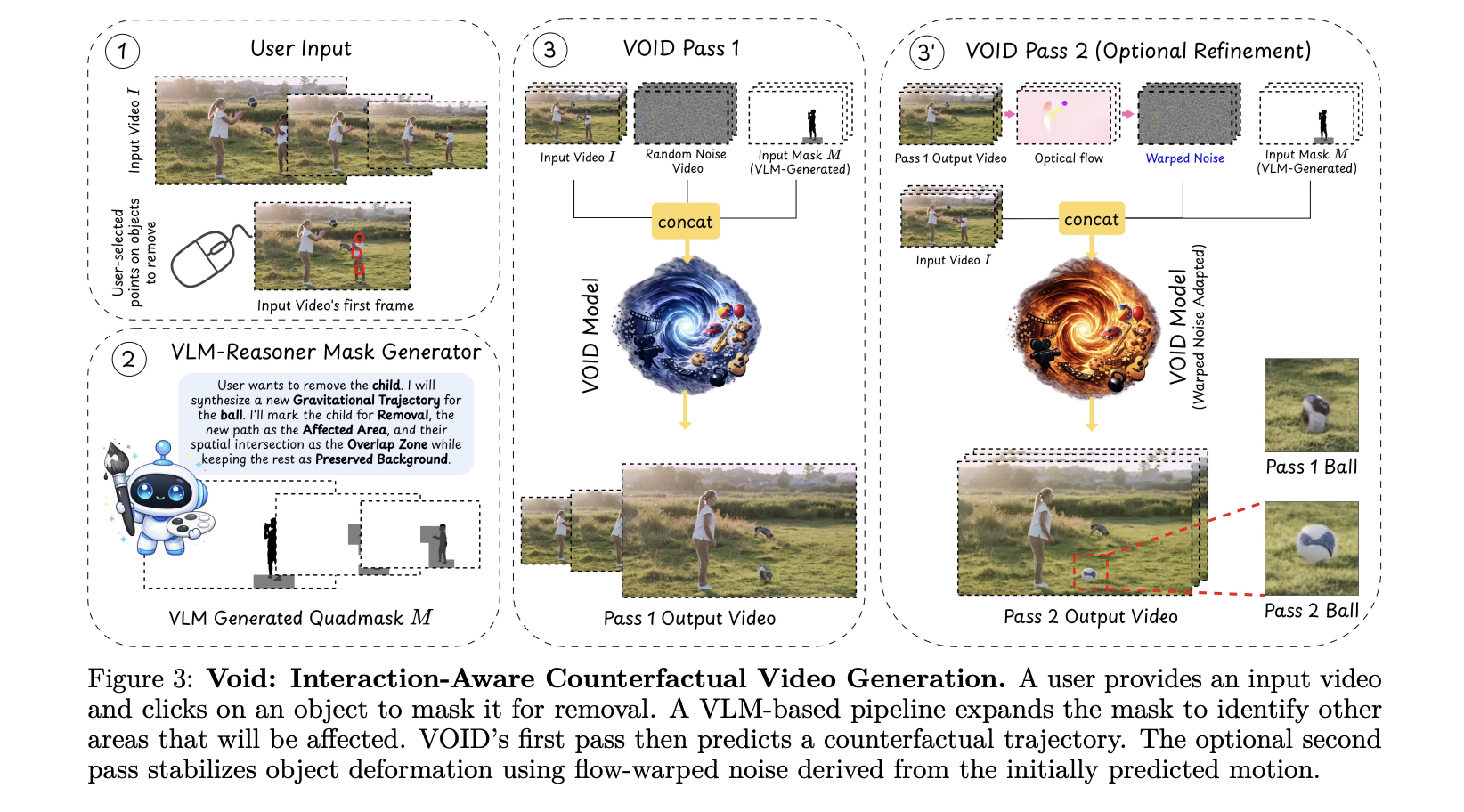
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .

Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models


b8661
llama: add custom newline split for Gemma 4 ( #21406 ) macOS/iOS: macOS Apple Silicon (arm64) macOS Intel (x64) iOS XCFramework Linux: Ubuntu x64 (CPU) Ubuntu arm64 (CPU) Ubuntu s390x (CPU) Ubuntu x64 (Vulkan) Ubuntu arm64 (Vulkan) Ubuntu x64 (ROCm 7.2) Ubuntu x64 (OpenVINO) Windows: Windows x64 (CPU) Windows arm64 (CPU) Windows x64 (CUDA 12) - CUDA 12.4 DLLs Windows x64 (CUDA 13) - CUDA 13.1 DLLs Windows x64 (Vulkan) Windows x64 (SYCL) Windows x64 (HIP) openEuler: openEuler x86 (310p) openEuler x86 (910b, ACL Graph) openEuler aarch64 (310p) openEuler aarch64 (910b, ACL Graph)

Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!