
Moonlake: Causal World Models should be Multimodal, Interactive, and Efficient — with Chris Manning and Fan-yun Sun
We cap out our World Models coverage with one of the most exciting new approaches - long running, multiplayer, interactive world models built with agents bootstrapped from game engines!
Could not retrieve the full article text.
Read on Latent Space →Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modelworld modelmultimodal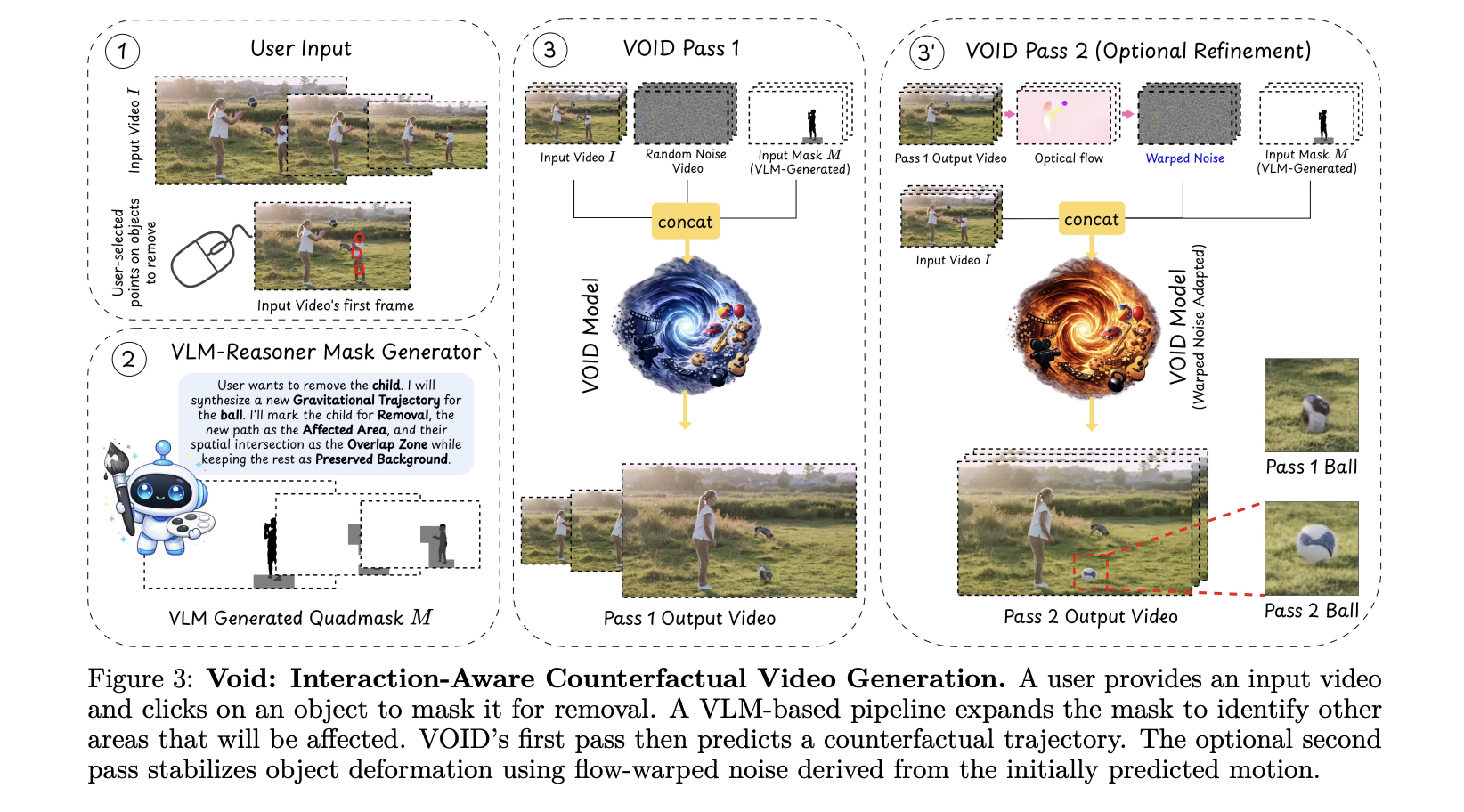
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .

TigerFS Mounts PostgreSQL Databases as a Filesystem for Developers and AI Agents
TigerFS is a new experimental filesystem that mounts a database as a directory and stores files directly in PostgreSQL. The open source project exposes database data through a standard filesystem interface, allowing developers and AI agents to interact with it using common Unix tools such as ls, cat, find, and grep, rather than via APIs or SDKs. By Renato Losio
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Frontier Research



Magic, Madness, Heaven, Sin: LLM Output Diversity is Everything, Everywhere, All at Once
arXiv:2604.01504v1 Announce Type: new Abstract: Research on Large Language Models (LLMs) studies output variation across generation, reasoning, alignment, and representational analysis, often under the umbrella of "diversity." Yet the terminology remains fragmented, largely because the normative objectives underlying tasks are rarely made explicit. We introduce the Magic, Madness, Heaven, Sin framework, which models output variation along a homogeneity-heterogeneity axis, where valuation is determined by the task and its normative objective. We organize tasks into four normative contexts: epistemic (factuality), interactional (user utility), societal (representation), and safety (robustness). For each, we examine the failure modes and vocabulary such as hallucination, mode collapse, bias,
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!