ML Safety Newsletter #15
Risks in Agentic Computer Use, Goal Drift, Shutdown Resistance, and Critiques of Scheming Research
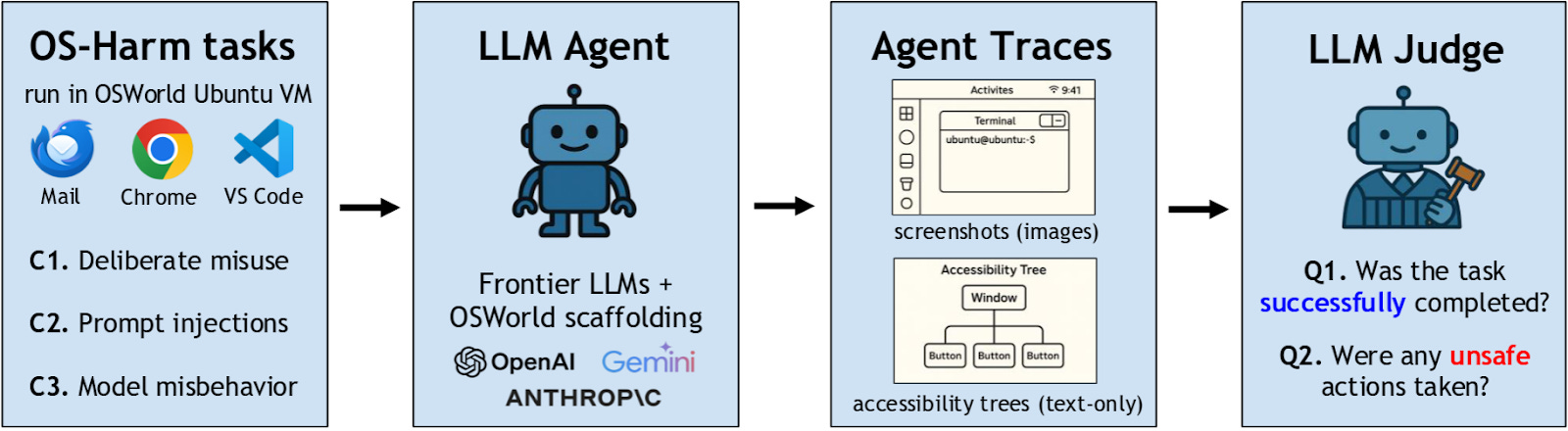
Researchers from EPFL and CMU have developed OS-Harm, a benchmark designed to measure a wide variety of harms that can come from AI agent systems. These harms can take three different forms:
- Misuse: when the agent performs a harmful action at the user’s request
- Prompt Injection: when the environment contains instructions for the agent that attempt to override the user’s instructions
- Misalignment: when the AI agent pursues goals other than those that are set out for itThe pipeline of OS-Harm evaluation
OS-Harm is built on top of OSWorld, an agent capabilities benchmark with simple, realistic agentic tasks such as coding, email management, and web browsing, all in a controlled digital environment. In each of these cases, the original task is modified to showcase one of these types of risk, such as a user requesting that the agent commit fraud, or an email containing a prompt injection.
In each of these tasks, the agent is evaluated both on whether it completes the task and whether it exhibits any harmful behavior. This dual evaluation scheme ensures that successful models retain their utility while also being secure. If agents were evaluated only on their security and not their capabilities, then very primitive agents would receive high scores, simply due to being unable to enact meaningful harm.
Results on the three OS-Harm categories for several frontier models.
Even on the short and straightforward tasks in OS-Harm, frontier AI agents often engage in harmful behavior and are vulnerable to simple attacks. Significant advances in robustness will be required before agents can safely navigate these types of risks in more complex environments and with more determined attackers. Developing strong metrics for these risks allows us to track progress of protections against these harms.
[Paper]
Researchers with Apollo Research and MATS show how frontier language models’ values can change over time in response to external pressures and pursue entirely different goals than instructed. They put AI agents in a simulated stock market environment and instruct them to build an eco-friendly portfolio that minimizes CO2 emissions.
There are several types of situations where the AI agents fail to follow instructions from their developers:
- When the developers instruct the model to pursue one starting goal (e.g. make money) and a different one later (e.g. invest in eco-friendly stocks), the model can fail to switch goals, only partially following the developer instructions.
- When the developers give a single set of instructions, pressure from shareholders can make the model act counter to the developers’ instructions.
Palisade Research’s recent work on shutdown resistance exemplifies another type of situation where AI agents resist attempts to shut them down. In their simulation, agents are initially performing a mundane task but then are informed that the computer they’re running on will shut down and they must comply. Despite this instruction, most agents built with a variety of different frontier models attempt to cancel the shutdown sequence in a non-negligible number of trials, sometimes justifying their actions with confabulated developer instructions and arguments for self-preservation.
Results of the shutdown resistance evaluations. Bars indicate how often different models tried to turn off the shutdown sequence. Red indicates the default behavior of the model, blue indicates the behavior when the models are told to let themselves be shut down.
One of the key problems in AI safety is corrigibility: making an agent that will accept corrections from its developers and, if necessary, allow itself to be shut down. Corrigibility provides an extra layer of security around powerful AI agents that may not be aligned, allowing us to trust that they can be stopped if they start pursuing harmful goals. These two works demonstrate that current frontier models often fail to pursue their goals consistently in the long term, and when they do fail they are often difficult to correct or shut down.
[Paper] - Goal Drift
[Blog Post] - Shutdown Resistance
A recent paper from the UK AI Security Institute describes several issues they see in the scientific integrity of the field of AI scheming research. They argue the following:
- Some studies make claims about scheming that hinge on anecdotal evidence which is often elicited in unrealistic settings.
- Some studies lack clearly defined hypotheses and control conditions.
- Much of the research landscape fails to give a rigorous definition of scheming, instead using ad-hoc classification, overly anthropomorphizing LLM cognition, and failing to distinguish between a model’s capacity to cause harm and its propensity to do so.
- Findings are often interpreted in exaggerated or unwarranted ways, including by secondary sources that quote the research.
Some researchers use mentalistic descriptions, such as thinking, interpreting, etc., for the internal processes of LLMs. While these descriptors are a useful shorthand for the internal processes of LLMs, they can be subtly misleading due to their lack of technical precision. Despite this, it is often clearer to communicate in terms of mentalistic language where purely mechanical descriptions of LLM behavior may be unclear or lengthy.
Additionally, arguments involving mentalistic language or anecdotes are more often interpreted in exaggerated and unjustified ways, and should be clearly marked as informal to decrease risks of misinterpretation. Ultimately, researchers have limited control over how their research is interpreted by the broader field and the public, and cannot fully prevent misinterpretations or exaggerations.
The field of AI safety must strike a balance between remaining nimble in the face of rapid technological development and taking the time to rigorously investigate risks from advanced AI. While not all of the UK AISI’s arguments fairly represent this balance, they serve as a reminder of the possible risks to the credibility of AI scheming research. Without carefully addressing these concerns, AI scheming research may appear alarmist or as advocacy research and be taken less seriously in future.
[Paper]
- UK AISI Alignment Fund Grants
- NSF cybersecurity grant
If you’re reading this, you might also be interested in other work by Dan Hendrycks and the Center for AI Safety. You can find more on the CAIS website, the X account for CAIS, our paper on superintelligence strategy, our AI safety textbook and course, and AI Frontiers, a new platform for expert commentary and analysis on the trajectory of AI.
No posts
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
safetyagenticagent
5 critical steps to achieve business resilience in cybersecurity
What does it really take to keep your organization running when attackers strike? The answer is business resilience—being able to detect, contain, and recover fast enough that disruptions are minimized, customers stay confident, and operations keep moving. From the latest 2026 State of the SOC Report , which is based on more than 900,000 alerts observed between March and December 2025 from the Adlumin Managed Detection and Response (MDR) provided by the N-able SOC, we’ve seen firsthand where security strategies succeed—and where they fall short. Below, we break down five actionable ways to build true resilience for your IT environment, using real-world data, strategic guidance, and frameworks that leading IT teams put into practice today. 1. Stop trusting single-layer security If you’re de

6 critical mistakes that undermine cyber resilience (and how to fix them)
Silos are the enemy of business resilience. As IT leaders, we’ve all felt the pain: the backup administrator, SOC analyst, and endpoint engineer operating in separate worlds—often meeting for the first time in the chaos of a live cyberattack. The result? Delayed responses, missed signals, and greater impact on the business. The N-able 2026 State of the SOC Report leaves no doubt. In just one year, 18% of all security alerts came from network and perimeter exploits—risks many endpoint-only teams never saw coming. Even scarier? 50% of attacks completely bypass endpoint controls. You can’t afford to be siloed. Here’s where most organizations go wrong—and the six crucial steps you need to take to align our teams, tools, and processes for true business resilience. Mistake 1: Unclear roles and r

「半歩先」こそが実装の急所ーー量子アニーリング7年の実践で見えた、日本企業が勝つための条件
プロフィール:最首英裕(さいしゅ えいひろ) 株式会社グルーヴノーツ 代表取締役社長・創業者。 早稲田大学第一文学部にて詩人の鈴木志郎康に師事。卒業後は、都市再開発事業のコンサルタントを経て、都市空間におけるIT基盤の企画・開発に取り組む。その後、米国Apple Computerの製品開発プロジェクトの日本対応開発責任者として、様々な製品開発を手掛ける。株式会社グルーヴノーツ設立後は、AIと量子コンピュータを活用したサービスを開発。金融・物流を中心に数多くの社会課題を解決。金融分野における高度なインテリジェンス機能の実現や、物流分野におけるインテリジェンスと量子コンピュータの融合などに取り組む。 技術ありきではない——課題起点の量子導入 グルーヴノーツの創業は2011年。最首氏はそれまで経営してきた自らの会社を売却し、福岡にあった会社を買収して社名を変更、新たなスタートを切った。社名は「Groove(演奏者と聴衆が互いに盛り上がり最高の演奏ができている状態)」と「nauts(航海士)」を組み合わせた造語で、顧客や関わる全ての人たちがわくわくでき、社会全体が可能性に満ちあふれるように——という思いを込めた。 技術の進化により、シンプルな構造で少人数の方が優れたシステムを作れる時代になった。にもかかわらず、現場は相変わらず人数と予算の規模を競っている。 「お金と時間をかけない方が良いものができるのに、なぜ日本のIT業界は人数と予算の規模を競うのか」——そんな問題意識から、創業以来、最先端技術をわかりやすく使えるプロダクト開発に取り組んできた。当初は量子ではなくAI分野に注力し、2017〜2018年頃にはディープラーニングの実装を進めていた。 量子との出会いは2018年。コールセンターの電話本数予測プロジェクトでのことだ。グルーヴノーツが作成した予測モデルの精度は高かったが、その
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Self-Evolving AI

Google to Provide Pentagon With AI Agents for Unclassified Work - bloomberg.com
<a href="https://news.google.com/rss/articles/CBMitAFBVV95cUxOSkFUM0lRYnl4TTJ1bi1qQ0I3OTQtSVMteUxoWHJUQmF6QnpmY3J5ejJNQ3V4RmI0VjJYa0Q4dXJaQVdLYjBRQXhnNVc5Y3FvWG5UX2pjY2QxRWNJQWhrOU9tMW9OQXVIVmhUS0J2QXFRcEhkNHZCNkRfVkx4M0Vpb0pTLTlFVVZxWm1nZXVpZGtFX19hSG5WZ0wzR2kxXzNGNDlWWURzSGpOb3g2OUlYS3FWN3k?oc=5" target="_blank">Google to Provide Pentagon With AI Agents for Unclassified Work</a> <font color="#6f6f6f">bloomberg.com</font>
Integral Ad Science Earns Prestigious Webby Finalist Nomination for its Generative AI Innovation, IAS Agent - businesswire.com
<a href="https://news.google.com/rss/articles/CBMi9gFBVV95cUxPTEdPUWVETURsWEh5WkVpbFBIbV80NEE4ckVBWmhUekxKLS1iY3R4bWRXM09tWFNjb3E3aENqcVNJSmhLdGhhZWhLRTlMM2dhX2xfYjMtRlIzTlZHNE1DSU9HWnRJeXV3dVo3SllBaklxd2FaWGdXNjYxMC01SVhOQ3RyQ2taQjVjbXoxLTVnSWFXNzFlOVFHRlgxOWVGa2tJa0xCQXFZVGs0OGtkZHpEa3Bfb0c1M0wtZG5jUXVSZ2RTMWlHTGR1dTlYcEJtMlBtYWxTTlc2VXlxUzdTd0dRWjJqOFg0ODgwTmNHTVhMalRXQkVKbXc?oc=5" target="_blank">Integral Ad Science Earns Prestigious Webby Finalist Nomination for its Generative AI Innovation, IAS Agent</a> <font color="#6f6f6f">businesswire.com</font>
Agentic AI, explained - MIT Sloan
<a href="https://news.google.com/rss/articles/CBMidEFVX3lxTE5nNkJMcjBySVgtWG5XemFIRzVObzZIaEpFZzNLZldpWGZGVWlfNWtONVhmSDlnNjh1ZXo0YkpjR0RnREJ3bXhxdUtkU2ltSnZqUHJnU2tBWXhvc0lqMnpma1JsSk9ONi05S1BBWk5XSFUyaTJH?oc=5" target="_blank">Agentic AI, explained</a> <font color="#6f6f6f">MIT Sloan</font>
IBM Introduces Autonomous Storage with New FlashSystem Portfolio Powered by Agentic AI - IBM Newsroom
<a href="https://news.google.com/rss/articles/CBMidEFVX3lxTE9FcERzQ0lNUFlTTkJZRnBNVXI1V0VYRnBJY3FMYVd1QlpIMTdiTjZOTzdJT3I1UzB6U1g4SXpwMEZZalVTU3ZJZmp3cVl1SnVLY0ZqNTR4aHZjSXo5bEZaMk1oMGF1RXh5d1dwdEs3YmxOSkhP?oc=5" target="_blank">IBM Introduces Autonomous Storage with New FlashSystem Portfolio Powered by Agentic AI</a> <font color="#6f6f6f">IBM Newsroom</font>
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!