

Microsoft Launches Three New AI Models to Advance Speech, Voice, and Image Capabilities - CXO Digitalpulse
Microsoft Launches Three New AI Models to Advance Speech, Voice, and Image Capabilities CXO Digitalpulse
Could not retrieve the full article text.
Read on GNews AI voice →Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellaunch

Which model do you guys use for NSFW image generation ?
I am new to this field and exploring the different models to generate NSFW images. What are your top models to do that ? Can I also generate NSFW videos ? I am planning to self host the model so ideally would want open source model suggestions. How do you maintain consistency across characters ? Do you use LORA or some other technique ? Just curious and keen to know what the community uses in order to get things going for me. submitted by /u/ElectricalVariety641 [link] [comments]
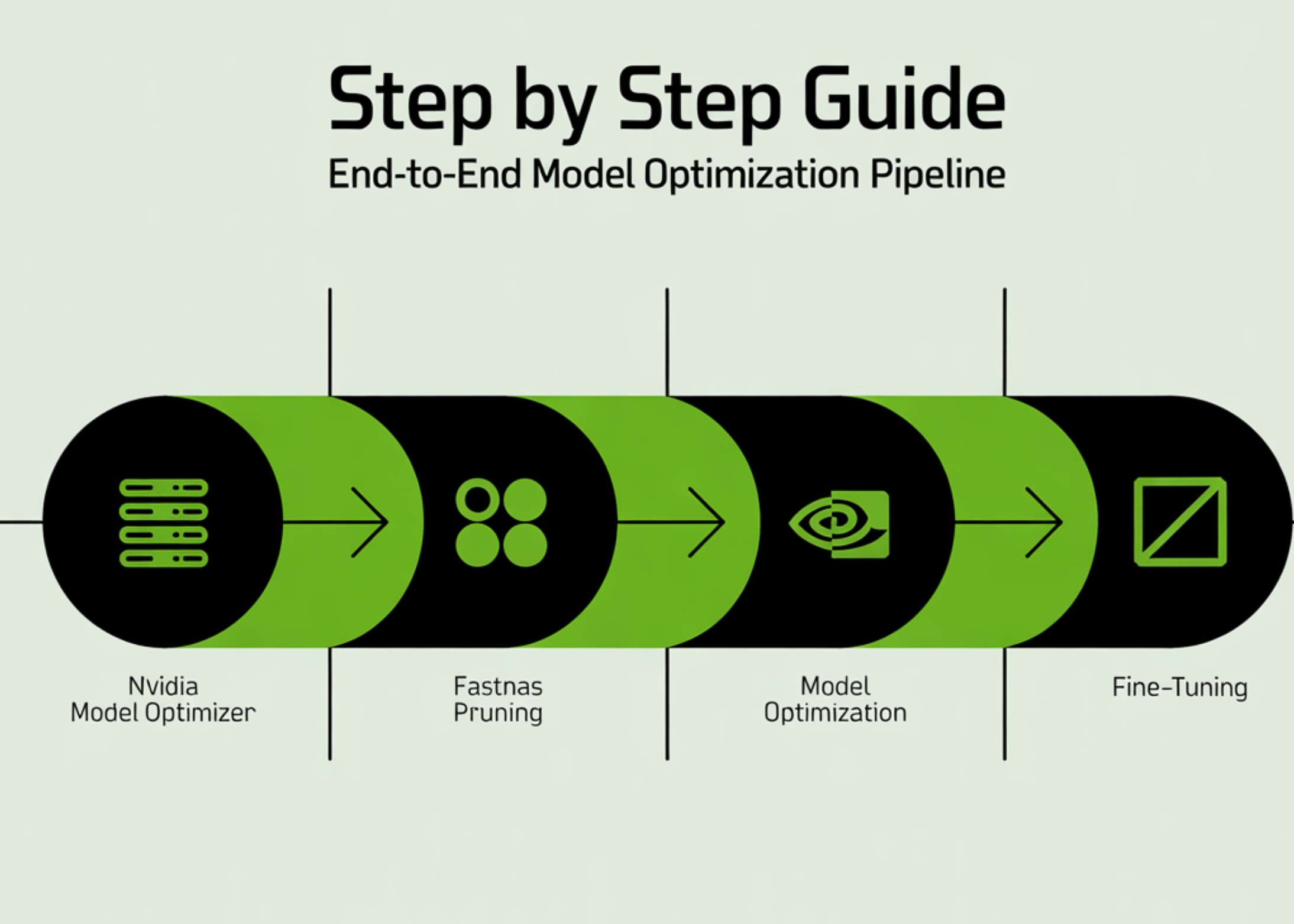
Step by Step Guide to Build an End-to-End Model Optimization Pipeline with NVIDIA Model Optimizer Using FastNAS Pruning and Fine-Tuning
In this tutorial, we build a complete end-to-end pipeline using NVIDIA Model Optimizer to train, prune, and fine-tune a deep learning model directly in Google Colab. We start by setting up the environment and preparing the CIFAR-10 dataset, then define a ResNet architecture and train it to establish a strong baseline. From there, we apply [ ] The post Step by Step Guide to Build an End-to-End Model Optimization Pipeline with NVIDIA Model Optimizer Using FastNAS Pruning and Fine-Tuning appeared first on MarkTechPost .
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

Gemma 4 is good
Waiting for artificialanalysis to produce intelligence index, but I see it's good. Gemma 26b a4b is the same speed on Mac Studio M1 Ultra as Qwen3.5 35b a3b (~1000pp, ~60tg at 20k context length, llama.cpp). And in my short test, it behaves way, way better than Qwen, not even close. Chain of thoughts on Gemma is concise, helpful and coherent while Qwen does a lot of inner-gaslighting, and also loops a lot on default settings. Visual understanding is very good, and multilingual seems good as well. Tested Q4_K_XL on both. I wonder if mlx-vlm properly handles prompt caching for Gemma (it doesn't work for Qwen 3.5). Too bad it's KV cache is gonna be monstrous as it did not implement any tricks to reduce that, hopefully TurboQuant will help with that soon. I expect censorship to be dogshit, I s
Step by Step Guide to Build an End-to-End Model Optimization Pipeline with NVIDIA Model Optimizer Using FastNAS Pruning and Fine-Tuning
In this tutorial, we build a complete end-to-end pipeline using NVIDIA Model Optimizer to train, prune, and fine-tune a deep learning model directly in Google Colab. We start by setting up the environment and preparing the CIFAR-10 dataset, then define a ResNet architecture and train it to establish a strong baseline. From there, we apply [ ] The post Step by Step Guide to Build an End-to-End Model Optimization Pipeline with NVIDIA Model Optimizer Using FastNAS Pruning and Fine-Tuning appeared first on MarkTechPost .
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!