
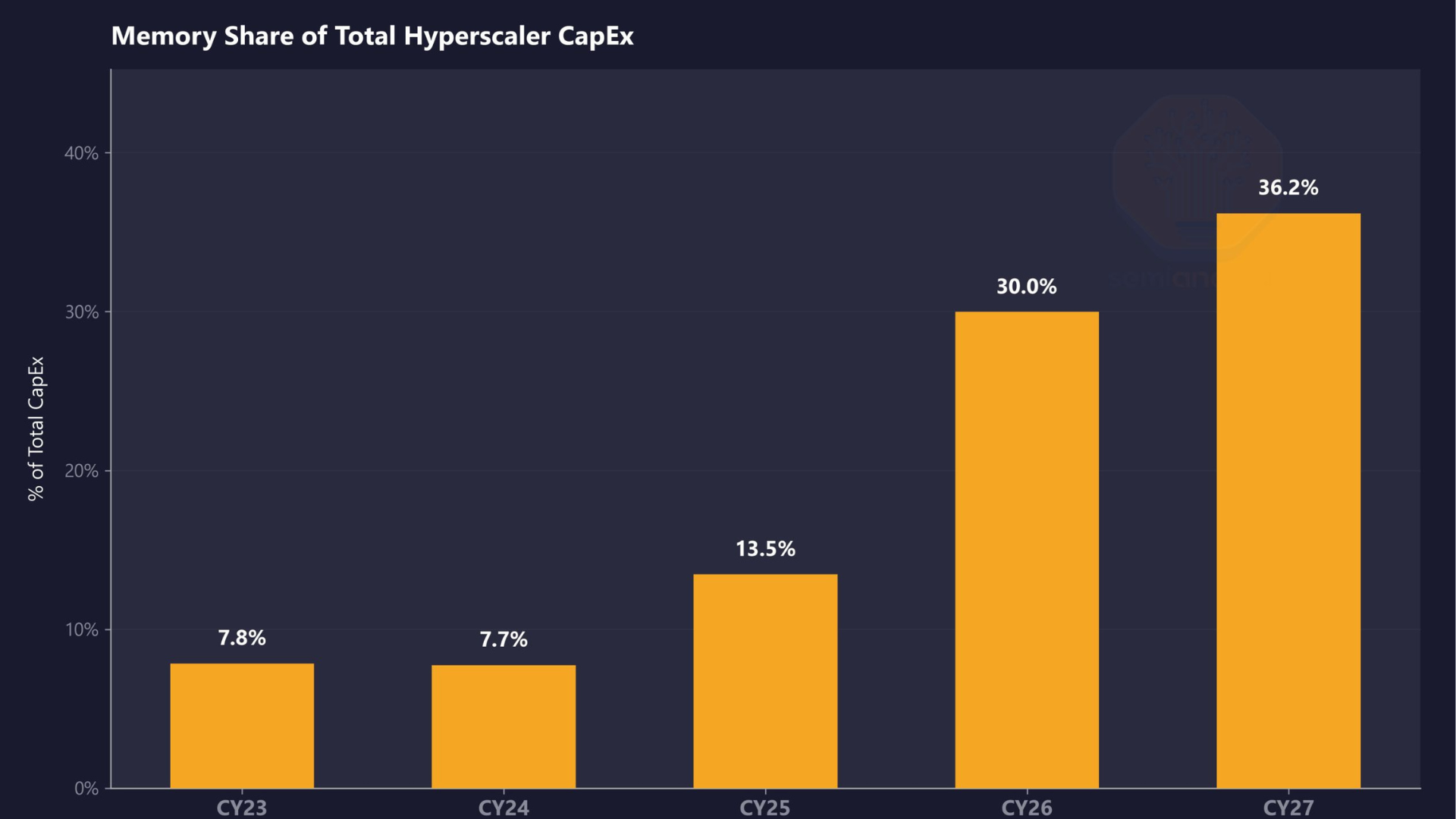
Memory will consume 30% of hyperscaler data center spending this year, a 4X increase over 2023 — Nvidia gets preferential supply terms well below standard market rates, says analyst firm
Memory will consume 30% of hyperscaler data center spending this year, a 4X increase over 2023 — Nvidia gets preferential supply terms well below standard market rates, says analyst firm
(Image credit: SemiAnalysis)
SemiAnalysis estimates that memory will account for roughly 30% of total hyperscaler capex in calendar year 2026, up from approximately 8% in CY23 and CY24. The firm projects that share will climb further in CY27, representing a near four-fold shift in just four years as DRAM prices surge beyond imagination and HBM remains massively undersupplied.
SemiAnalysis expects DRAM prices to more than double in CY26, with another double-digit ASP increase in CY27. LPDDR5 contract pricing has already risen more than three times since Q1 2025, and the firm estimates open-market pricing will likely exceed $10/GB this quarter.
HBM, the vertically stacked memory at the core of AI accelerators, remains undersupplied through CY27 according to SemiAnalysis’s findings, with memory now constituting a massive share of the approximately $250 billion in incremental hyperscaler spend projected for this calendar year.
Article continues below
Memory is taking over Hyperscaler CapEx.In CY23 and CY24, memory was ~8% of total Hyperscaler spend. We estimate it hits 30% in CY26 and moves higher in CY27. That's a near-4x shift in just four years. (1/4) 🧵 pic.twitter.com/fUxpwUYfcOApril 3, 2026
This is already reflected in AI server pricing, with SemiAnalysis noting that B200 prices are set to rise by up to 20% by year-end, driven in large part by memory cost inflation. That aligns with the broader industry, with manufacturers having acknowledged steep component cost increases in recent earnings calls. Dell's COO, Jeff Clarke, described the rate of cost movement as "unprecedented" in its Q325 earnings call back in November.
Counterpoint Research has separately projected that DDR5 64GB RDIMM modules could cost twice as much by the end of 2026 as they did in early 2025. AI servers built on Nvidia's LPDDR-based platforms are seeing some of the steepest increases because of the sheer volume of memory per system.
An interesting dynamic SemiAnalysis noted is that Nvidia receives what the firm calls "VVP" (Very Very Preferred) DRAM pricing from suppliers, “well below [the rates paid by] both hyperscalers and the broader market.” This, according to SemiAnalysis, compresses Nvidia's own server cost exposure and pushes down overall market pricing benchmarks, masking how severe the supply crunch actually is for everyone else.
AMD sits on the other side of that dynamic, with its AI accelerator SKUs generally carrying higher memory content per unit, and the company doesn’t benefit from the same preferential supplier pricing. At a time when AMD operates at far lower AI accelerator volume than Nvidia, making AMD “structurally more exposed [to memory cost inflation] at a time when it operates at far lower AI accelerator scale.” In other words, Nvidia's purchasing scale across HBM and conventional DRAM gives it leverage that smaller-volume buyers simply can’t replicate.
SemiAnalysis concluded that while memory inflation is already partially reflected in CY26 capex guidance from major cloud operators, CY27 repricing is not yet captured in Wall Street estimates. Samsung, SK hynix, and Micron have all diverted production capacity toward HBM and high-margin enterprise DRAM, leaving conventional DDR5 and LPDDR5 supply constrained, and new fab capacity from Micron's $9.6 billion Hiroshima HBM facility and SK hynix's Icheon and Cheongju expansions won’t be delivering meaningful output until 2027 or 2028 at the earliest.
Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.
Luke James is a freelance writer and journalist. Although his background is in legal, he has a personal interest in all things tech, especially hardware and microelectronics, and anything regulatory.
tomshardware.com
https://www.tomshardware.com/tech-industry/memory-will-consume-30-percent-of-hyperscaler-spending-this-yearSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
market
Top 10 AI Writing Tools for 2026: Complete Guide
Top 10 AI Writing Tools for 2026: Complete Guide Introduction AI writing tools are transforming content creation. But with so many options, which ones are actually worth using? In this guide, I'll share the top 10 AI writing tools for 2026. I've tested dozens of AI writing tools over the past year. These are the 10 that consistently produce the best results. The Top 10 AI Writing Tools for 2026 1. Jasper AI Best for: Overall content creation Why it's #1: Jasper AI consistently produces the highest quality content across all categories. It's the most versatile tool on the market. Key features: 50+ templates Brand voice customization SEO optimization Team collaboration Pricing: Starter: $49/month (35,000 words) Pro: $99/month (unlimited words) Business: Custom pricing Best for: Content marke

⚖️ AI Is Transforming Legal Practice in Romania — Why Lawyers Who Ignore It Are Already Falling Behind
⚖️ AI Is Transforming Legal Practice in Romania — And Most Lawyers Aren't Ready The legal profession has survived centuries of change. From handwritten scrolls to typewriters, from physical archives to digital databases, lawyers have always adapted — eventually. But the current wave of transformation is different. It's faster, deeper, and far less forgiving to those who hesitate. Artificial intelligence is no longer a Silicon Valley curiosity. It's drafting contracts, analyzing jurisprudence, conducting due diligence, and managing entire case strategies. And in Romania — a country with a rapidly modernizing legal market and increasing pressure from EU regulations — the lawyers who ignore this shift are building their practices on borrowed time. 🏛️ The Romanian Legal Market at a Crossroads

Gemma 4 is a KV_cache Pig
Ignoring the 8 bit size of Nvidia’s marketed 4 bit quantization of the dense model… The dense model KV cache architecture uses 3x or more the memory than what I have seen with other models. It seems like the big choice was 256 head dim instead of 128. I am looking at 490KB per 8 bit token of KV cache versus 128KB on Qwen3. I am running the nvidia weights at 4 bit on an rtx pro 6000 with 96GB of RAM and 8 bit kv cache and still only have room for 115k tokens. I was surprised is all. The model scales well in vllm and seems quite smart. submitted by /u/IngeniousIdiocy [link] [comments]
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.




Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!