
M-MiniGPT4: Multilingual VLLM Alignment via Translated Data
arXiv:2603.29467v1 Announce Type: new Abstract: This paper presents a Multilingual Vision Large Language Model, named M-MiniGPT4. Our model exhibits strong vision-language understanding (VLU) capabilities across 11 languages. We utilize a mixture of native multilingual and translated data to push the multilingual VLU performance of the MiniGPT4 architecture. In addition, we propose a multilingual alignment training stage that uses parallel text corpora to further enhance the multilingual capabilities of our model. M-MiniGPT4 achieves 36% accuracy on the multilingual MMMU benchmark, outperforming state-of-the-art models in the same weight class, including foundation models released after the majority of this work was completed. We open-source our models, code, and translated datasets to fac
View PDF HTML (experimental)
Abstract:This paper presents a Multilingual Vision Large Language Model, named M-MiniGPT4. Our model exhibits strong vision-language understanding (VLU) capabilities across 11 languages. We utilize a mixture of native multilingual and translated data to push the multilingual VLU performance of the MiniGPT4 architecture. In addition, we propose a multilingual alignment training stage that uses parallel text corpora to further enhance the multilingual capabilities of our model. M-MiniGPT4 achieves 36% accuracy on the multilingual MMMU benchmark, outperforming state-of-the-art models in the same weight class, including foundation models released after the majority of this work was completed. We open-source our models, code, and translated datasets to facilitate future research in low-resource and multilingual settings.
Comments: 6 pages, ACL 2026, Proceedings of the 7th Workshop on African Natural Language Processing (AfricaNLP 2026)
Subjects:
Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
Cite as: arXiv:2603.29467 [cs.CL]
(or arXiv:2603.29467v1 [cs.CL] for this version)
https://doi.org/10.48550/arXiv.2603.29467
arXiv-issued DOI via DataCite (pending registration)
Related DOI:
https://doi.org/10.18653/v1/2026.africanlp-main.2
DOI(s) linking to related resources
Submission history
From: Youssef Mohamed [view email] [v1] Tue, 31 Mar 2026 09:13:38 UTC (37 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellanguage modelfoundation model
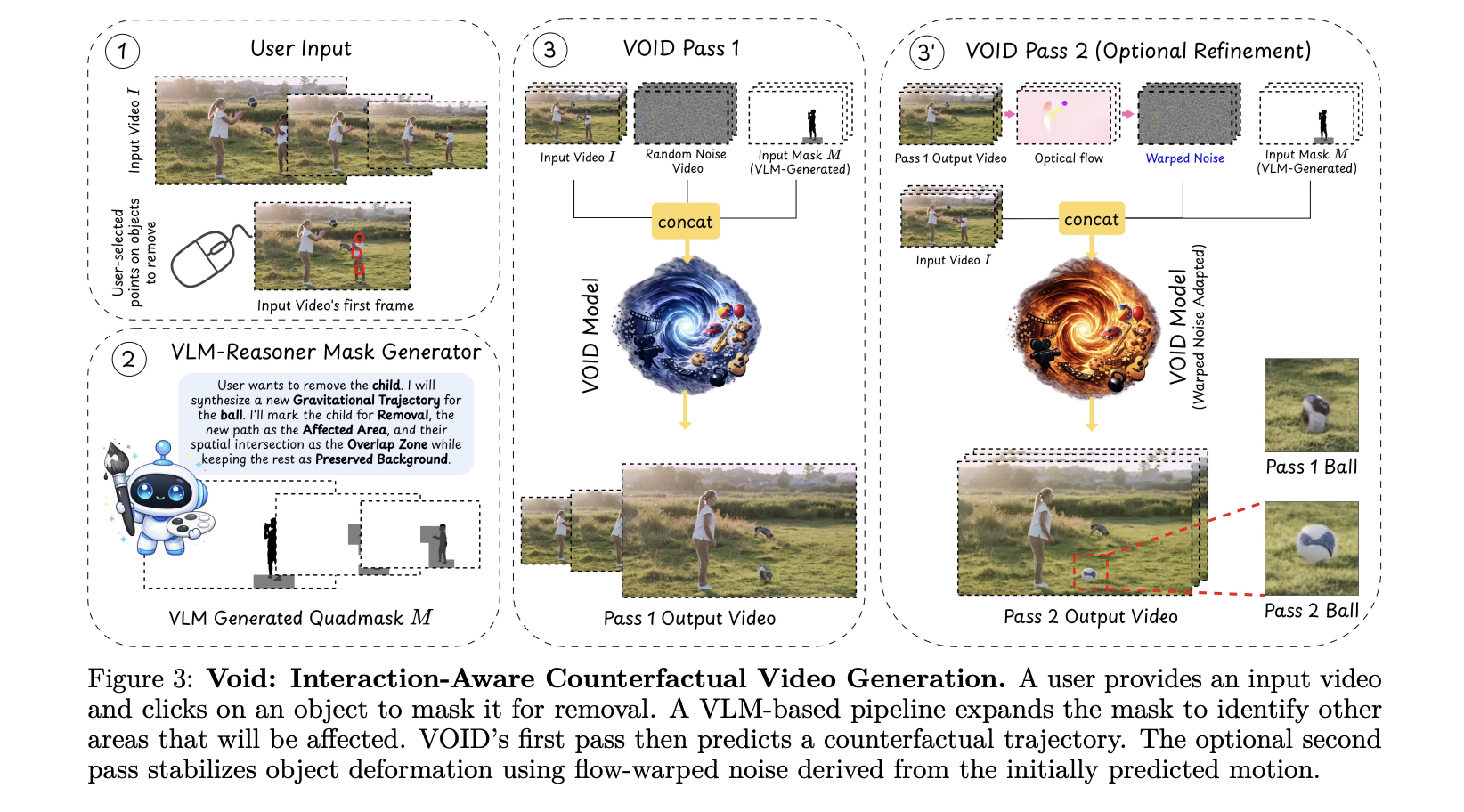
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .

Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .
Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!