
LLM-Meta-SR: In-Context Learning for Evolving Selection Operators in Symbolic Regression
arXiv:2505.18602v3 Announce Type: replace Abstract: Large language models (LLMs) have revolutionized algorithm development, yet their application in symbolic regression, where algorithms automatically discover symbolic expressions from data, remains limited. In this paper, we propose a meta-learning framework that enables LLMs to automatically design selection operators for evolutionary symbolic regression algorithms. We first identify two key limitations in existing LLM-based algorithm evolution techniques: lack of semantic guidance and code bloat. The absence of semantic awareness can lead to ineffective exchange of useful code components, while bloat results in unnecessarily complex components; both can hinder evolutionary learning progress or reduce the interpretability of the designed
View PDF HTML (experimental)
Abstract:Large language models (LLMs) have revolutionized algorithm development, yet their application in symbolic regression, where algorithms automatically discover symbolic expressions from data, remains limited. In this paper, we propose a meta-learning framework that enables LLMs to automatically design selection operators for evolutionary symbolic regression algorithms. We first identify two key limitations in existing LLM-based algorithm evolution techniques: lack of semantic guidance and code bloat. The absence of semantic awareness can lead to ineffective exchange of useful code components, while bloat results in unnecessarily complex components; both can hinder evolutionary learning progress or reduce the interpretability of the designed algorithm. To address these issues, we enhance the LLM-based evolution framework for meta-symbolic regression with two key innovations: a complementary, semantics-aware selection operator and bloat control. Additionally, we embed domain knowledge into the prompt, enabling the LLM to generate more effective and contextually relevant selection operators. Our experimental results on symbolic regression benchmarks show that LLMs can devise selection operators that outperform nine expert-designed baselines, achieving state-of-the-art performance. Moreover, the evolved operator can further improve a state-of-the-art symbolic regression algorithm, achieving the best performance among 28 symbolic regression and other machine learning algorithms across 116 regression datasets. This demonstrates that LLMs can exceed expert-level algorithm design for symbolic regression.
Subjects:
Neural and Evolutionary Computing (cs.NE); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
Cite as: arXiv:2505.18602 [cs.NE]
(or arXiv:2505.18602v3 [cs.NE] for this version)
https://doi.org/10.48550/arXiv.2505.18602
arXiv-issued DOI via DataCite
Submission history
From: Hengzhe Zhang [view email] [v1] Sat, 24 May 2025 08:52:56 UTC (1,281 KB) [v2] Fri, 8 Aug 2025 06:50:37 UTC (579 KB) [v3] Tue, 31 Mar 2026 12:07:54 UTC (750 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellanguage modelbenchmark
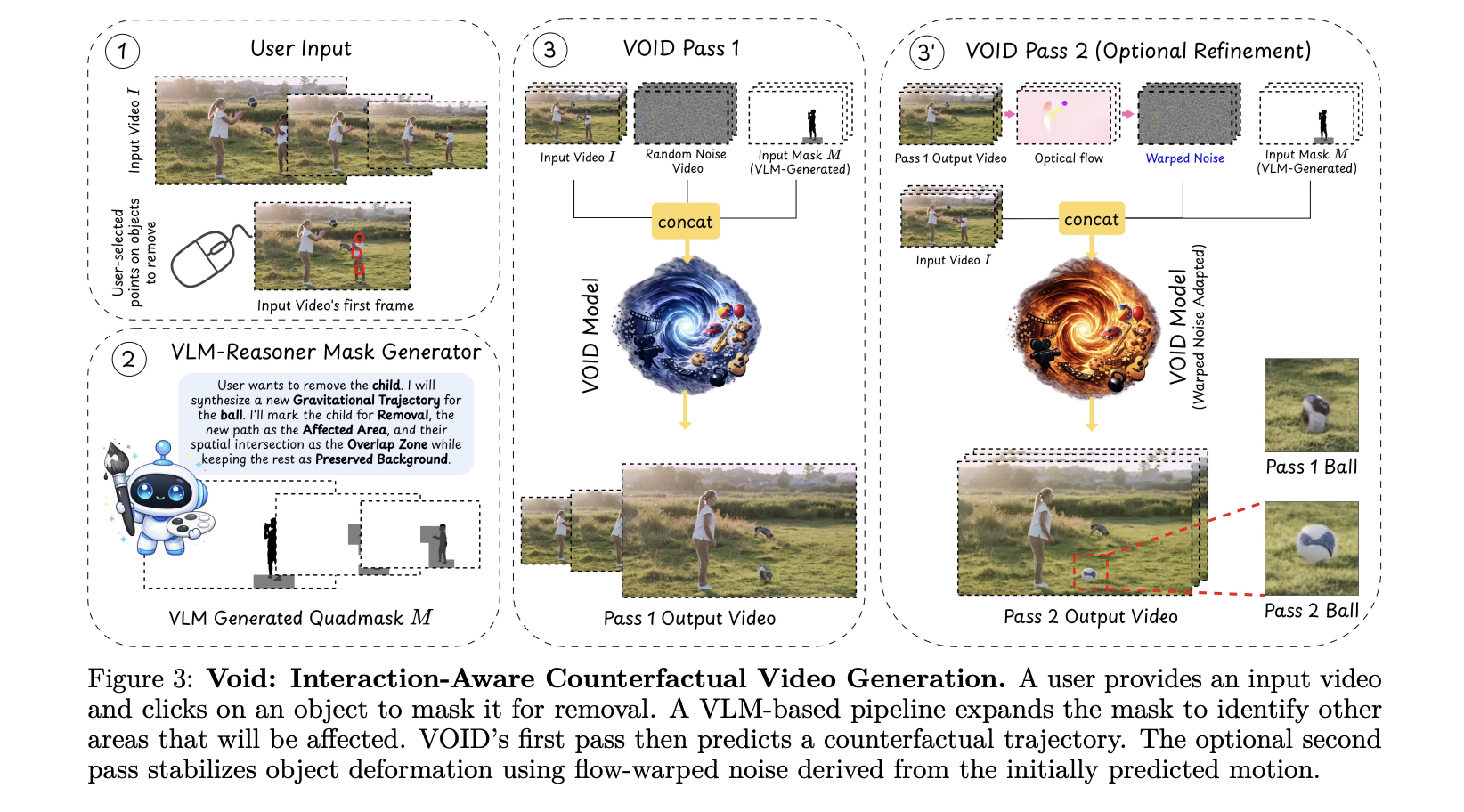
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .

Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .
Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!