
Inversion-Free Natural Gradient Descent on Riemannian Manifolds
arXiv:2604.02969v1 Announce Type: new Abstract: The natural gradient method is widely used in statistical optimization, but its standard formulation assumes a Euclidean parameter space. This paper proposes an inversion-free stochastic natural gradient method for probability distributions whose parameters lie on a Riemannian manifold. The manifold setting offers several advantages: one can implicitly enforce parameter constraints such as positive definiteness and orthogonality, ensure parameters are identifiable, or guarantee regularity properties of the objective like geodesic convexity. Building on an intrinsic formulation of the Fisher information matrix (FIM) on a manifold, our method maintains an online approximation of the inverse FIM, which is efficiently updated at quadratic cost us
View PDF HTML (experimental)
Abstract:The natural gradient method is widely used in statistical optimization, but its standard formulation assumes a Euclidean parameter space. This paper proposes an inversion-free stochastic natural gradient method for probability distributions whose parameters lie on a Riemannian manifold. The manifold setting offers several advantages: one can implicitly enforce parameter constraints such as positive definiteness and orthogonality, ensure parameters are identifiable, or guarantee regularity properties of the objective like geodesic convexity. Building on an intrinsic formulation of the Fisher information matrix (FIM) on a manifold, our method maintains an online approximation of the inverse FIM, which is efficiently updated at quadratic cost using score vectors sampled at successive iterates. In the Riemannian setting, these score vectors belong to different tangent spaces and must be combined using transport operations. We prove almost-sure convergence rates of $O(\log{s}/s^\alpha)$ for the squared distance to the minimizer when the step size exponent $\alpha >2/3$. We also establish almost-sure rates for the approximate FIM, which now accumulates transport-based errors. A limited-memory variant of the algorithm with sub-quadratic storage complexity is proposed. Finally, we demonstrate the effectiveness of our method relative to its Euclidean counterparts on variational Bayes with Gaussian approximations and normalizing flows.
Comments: 73 pages, 3 figures
Subjects:
Machine Learning (stat.ML); Machine Learning (cs.LG); Computation (stat.CO); Methodology (stat.ME)
Cite as: arXiv:2604.02969 [stat.ML]
(or arXiv:2604.02969v1 [stat.ML] for this version)
https://doi.org/10.48550/arXiv.2604.02969
arXiv-issued DOI via DataCite (pending registration)
Submission history
From: Minh-Ngoc Tran [view email] [v1] Fri, 3 Apr 2026 11:08:59 UTC (917 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
announceversionupdate
AI Is Insatiable
While browsing our website a few weeks ago, I stumbled upon “ How and When the Memory Chip Shortage Will End ” by Senior Editor Samuel K. Moore. His analysis focuses on the current DRAM shortage caused by AI hyperscalers’ ravenous appetite for memory, a major constraint on the speed at which large language models run. Moore provides a clear explanation of the shortage, particularly for high bandwidth memory (HBM). As we and the rest of the tech media have documented, AI is a resource hog. AI electricity consumption could account for up to 12 percent of all U.S. power by 2028. Generative AI queries consumed 15 terawatt-hours in 2025 and are projected to consume 347 TWh by 2030. Water consumption for cooling AI data centers is predicted to double or even quadruple by 2028 compared to 2023. B

Salt: Self-Consistent Distribution Matching with Cache-Aware Training for Fast Video Generation
Video generation models are distilled using self-consistent distribution matching to improve quality under extreme inference constraints, with cache-aware training enhancing real-time autoregressive generation. (1 upvotes on HuggingFace)

Swift-SVD: Theoretical Optimality Meets Practical Efficiency in Low-Rank LLM Compression
Swift-SVD is a compression framework that achieves optimal low-rank approximations for large language models through efficient covariance aggregation and eigenvalue decomposition, enabling faster and more accurate model compression. (3 upvotes on HuggingFace)
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Releases
OpenAI Releases Policy Recommendations for AI Age
OpenAI has released policy recommendations to address the rapid social changes driven by AI. OpenAI's Chief Global Affairs Officer Chris Lehane discusses the company’s ideas to “ensure AI benefits everyone.” Lehane joins Caroline Hyde and Ed Ludlow on “Bloomberg Tech.” (Source: Bloomberg)

![[OpenAI] Industrial policy for the Intelligence Age](https://d2xsxph8kpxj0f.cloudfront.net/310419663032563854/konzwo8nGf8Z4uZsMefwMr/default-img-matrix-rain-CvjLrWJiXfamUnvj5xT9J9.webp)
[OpenAI] Industrial policy for the Intelligence Age
As we move toward superintelligence, incremental policy updates won’t be enough. To kick-start this much needed conversation, OpenAI is offering a slate of people-first policy ideas(opens in a new window) designed to expand opportunity, share prosperity, and build resilient institutions—ensuring that advanced AI benefits everyone. These ideas are ambitious, but intentionally early and exploratory. We offer them not as a comprehensive or final set of recommendations, but as a starting point for discussion that we invite others to build on, refine, challenge, or choose among through the democratic process. To help sustain momentum, OpenAI is: welcoming and organizing feedback through [email protected] establishing a pilot program of fellowships and focused research grants of u
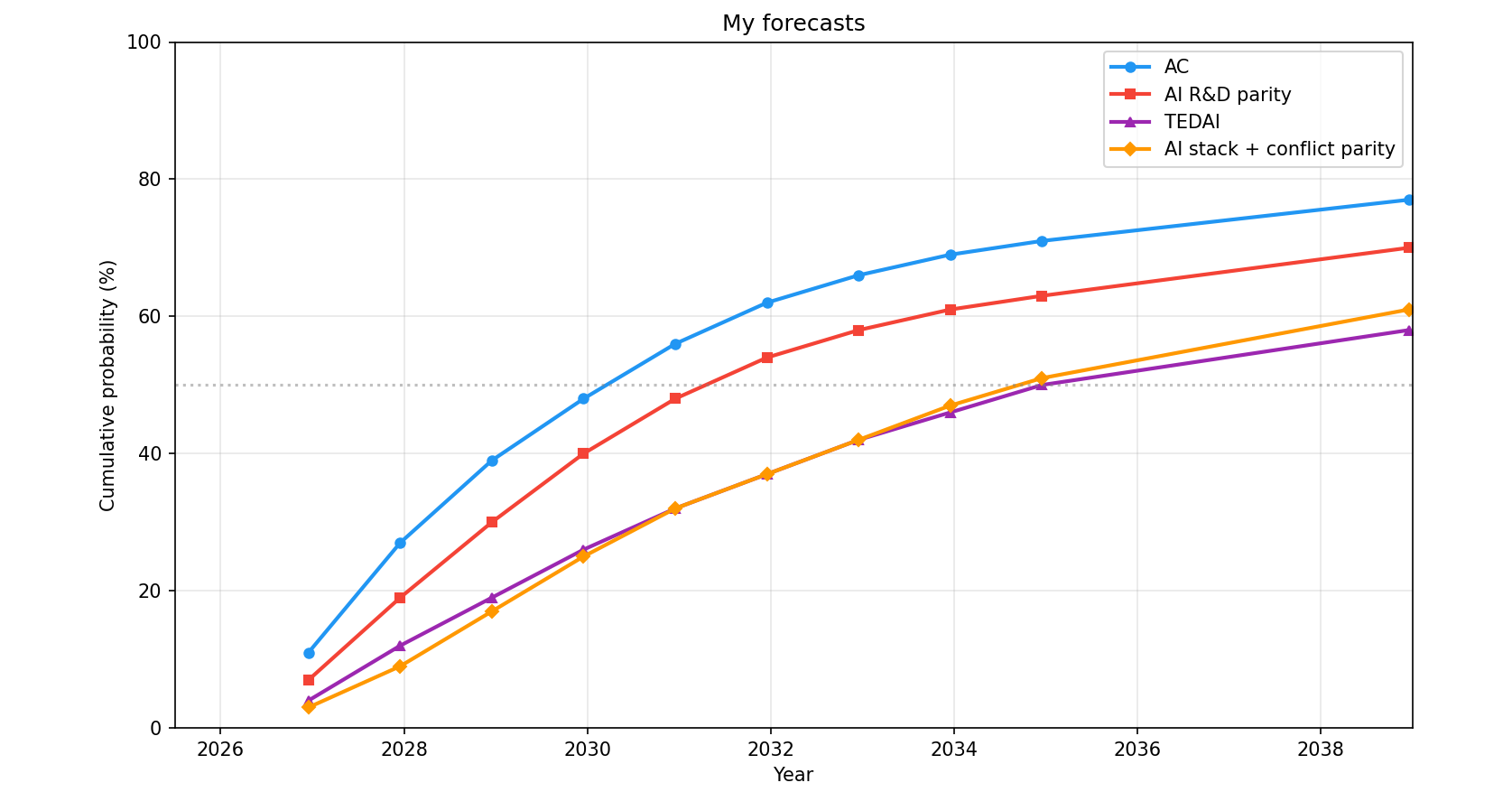
AIs can now often do massive easy-to-verify SWE tasks and I've updated towards shorter timelines
I've recently updated towards substantially shorter AI timelines and much faster progress in some areas. [1] The largest updates I've made are (1) an almost 2x higher probability of full AI R&D automation by EOY 2028 (I'm now a bit below 30% [2] while I was previously expecting around 15% ; my guesses are pretty reflectively unstable) and (2) I expect much stronger short-term performance on massive and pretty difficult but easy-and-cheap-to-verify software engineering (SWE) tasks that don't require that much novel ideation [3] . For instance, I expect that by EOY 2026, AIs will have a 50%-reliability [4] time horizon of years to decades on reasonably difficult easy-and-cheap-to-verify SWE tasks that don't require much ideation (while the high reliability—for instance, 90%—time horizon will
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!