
I built a self-hosted RAG system that actually works — here's how to run it in one command
<p>I'll be honest: I spent weeks trying to make existing RAG tools work for my use case. AnythingLLM kept needing cloud APIs. RAGFlow was hard to self-host cleanly. Perplexity-style tools were completely off the table for anything with sensitive documents.</p> <p>So I built my own.</p> <p><strong>RAG Enterprise</strong> is a 100% local RAG system — no data leaves your server, no external APIs, no hidden telemetry. It runs on your hardware with a single setup script. Here's how to get it running.</p> <h2> Why another RAG tool? </h2> <p>Because my clients have real constraints:</p> <ul> <li>Legal documents that can't touch US servers (hello, GDPR)</li> <li>IT departments that won't approve "just use OpenAI" </li> <li>Budgets that don't include $500/month SaaS subscriptions</li> </ul> <p>I ne
I'll be honest: I spent weeks trying to make existing RAG tools work for my use case. AnythingLLM kept needing cloud APIs. RAGFlow was hard to self-host cleanly. Perplexity-style tools were completely off the table for anything with sensitive documents.
So I built my own.
RAG Enterprise is a 100% local RAG system — no data leaves your server, no external APIs, no hidden telemetry. It runs on your hardware with a single setup script. Here's how to get it running.
Why another RAG tool?
Because my clients have real constraints:
-
Legal documents that can't touch US servers (hello, GDPR)
-
IT departments that won't approve "just use OpenAI"
-
Budgets that don't include $500/month SaaS subscriptions
I needed something that runs on-prem, handles PDFs and DOCX files well, supports multiple users with proper roles, and doesn't require a PhD to install.
After building and iterating on this for a few months, it now handles 10,000+ documents comfortably, supports 29 languages, and the whole stack is containerized.
What's under the hood
The architecture is pretty standard but well-wired:
React Frontend (Port 3000) │ │ REST API ▼ FastAPI Backend (Port 8000)React Frontend (Port 3000) │ │ REST API ▼ FastAPI Backend (Port 8000)- LangChain RAG pipeline
- JWT auth + RBAC
- Apache Tika + Tesseract OCR
- BAAI/bge-m3 embeddings │ ┌────┴────┐ ▼ ▼ Qdrant Ollama (vectors) (LLM inference)`
Enter fullscreen mode
Exit fullscreen mode
The LLM runs via Ollama locally — by default Mistral 7B Q4 or Qwen2.5:14b depending on your VRAM. Embeddings use BAAI/bge-m3 which is multilingual and genuinely good.
Everything is Docker containers. No dependency hell.
Prerequisites
Before you start, make sure you have:
-
Ubuntu 20.04+ (22.04 recommended)
-
NVIDIA GPU with 8-16GB VRAM, drivers installed
-
16GB RAM minimum (32GB recommended)
-
50GB+ free disk space
-
A decent internet connection for the initial download (~80 Mbit/s or faster)
The setup downloads Docker images, the LLM model, and the embedding model. On a fast connection it takes 15-20 minutes. On a slower one, about an hour. You do it once.
Installation
# 1. Clone the repo git clone https://github.com/I3K-IT/RAG-Enterprise.git cd RAG-Enterprise/rag-enterprise-structure# 1. Clone the repo git clone https://github.com/I3K-IT/RAG-Enterprise.git cd RAG-Enterprise/rag-enterprise-structure2. Run the setup script
./setup.sh standard`
Enter fullscreen mode
Exit fullscreen mode
The script handles everything:
-
Docker Engine + Docker Compose
-
NVIDIA Container Toolkit
-
Ollama with your chosen LLM
-
Qdrant vector database
-
Backend + frontend services
At one point during setup it'll ask you to log out and back in (for Docker group permissions). Just do it and re-run the script — it picks up where it left off.
First startup
After setup completes, the backend downloads the embedding model on first run. This takes a few minutes. Check progress with:
docker compose logs backend -f
Enter fullscreen mode
Exit fullscreen mode
When you see Application startup complete, open your browser at http://localhost:3000.
Get your admin password from the logs:
docker compose logs backend | grep "Password:"
Enter fullscreen mode
Exit fullscreen mode
Login with admin and that password.
Uploading documents
The role system works like this:
-
User → can query, can't upload
-
Super User → can upload and delete documents
-
Admin → full access including user management
Login as Admin, go to the admin panel, create a Super User account. Then upload your documents.
Supported formats: PDF (with OCR), DOCX, PPTX, XLSX, TXT, MD, ODT, RTF, HTML, XML.
Processing takes 1-2 minutes per document. After that, you can start querying.
Querying your documents
Just type your question in plain language. The RAG pipeline:
-
Embeds your query with bge-m3
-
Searches Qdrant for semantically similar chunks
-
Passes relevant context to the LLM
-
Returns an answer grounded in your documents
Response time is 2-4 seconds. Generation speed around 80-100 tokens/second on an RTX 4070.
Switching the LLM model
Edit docker-compose.yml:
environment: LLM_MODEL: qwen2.5:14b-instruct-q4_K_M # or mistral:7b-instruct-q4_K_M EMBEDDING_MODEL: BAAI/bge-m3 RELEVANCE_THRESHOLD: "0.35"environment: LLM_MODEL: qwen2.5:14b-instruct-q4_K_M # or mistral:7b-instruct-q4_K_M EMBEDDING_MODEL: BAAI/bge-m3 RELEVANCE_THRESHOLD: "0.35"Enter fullscreen mode
Exit fullscreen mode
Then restart the backend:
docker compose restart backend
Enter fullscreen mode
Exit fullscreen mode
If you're getting too few results, lower RELEVANCE_THRESHOLD to 0.3 or even 0.25.
Useful commands
# Check all services docker compose ps# Check all services docker compose psFollow logs
docker compose logs -f
Restart everything
docker compose restart
Stop
docker compose down
Health check
curl http://localhost:8000/health`
Enter fullscreen mode
Exit fullscreen mode
If the backend shows "unhealthy" on first start, just wait — it's still downloading the embedding model.
What I'm working on next
The community edition uses Qdrant for vector search. The Pro version I'm building adds a hybrid SQL-Vector engine — combining traditional keyword search with semantic search for better precision on structured documents like contracts and regulatory texts. It also adds a 6-stage retrieval pipeline (query expansion → retrieval → reranking → fusion → filtering → generation).
But for most use cases, the community edition is more than enough.
Try it, break it, contribute
The repo is at github.com/I3K-IT/RAG-Enterprise. It's AGPL-3.0 — free to use, modify, and self-host. If you offer it as a service you need to share modifications, which I think is fair.
If you're building something on top of this, or hit issues during setup, open an issue or drop a comment here. Happy to help.
And if you're interested in the EU sovereignty angle — keeping AI infrastructure inside European jurisdiction — check out EuLLM, a project I'm building in parallel: a Rust-based alternative to Ollama with an EU-hosted model registry and built-in AI Act compliance. RAG Enterprise will integrate with it natively.
Built by Francesco Marchetti @ I3K Technologies, Milan.
DEV Community
https://dev.to/primoco/i-built-a-self-hosted-rag-system-that-actually-works-heres-how-to-run-it-in-one-command-38p2Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
llamamistralmodel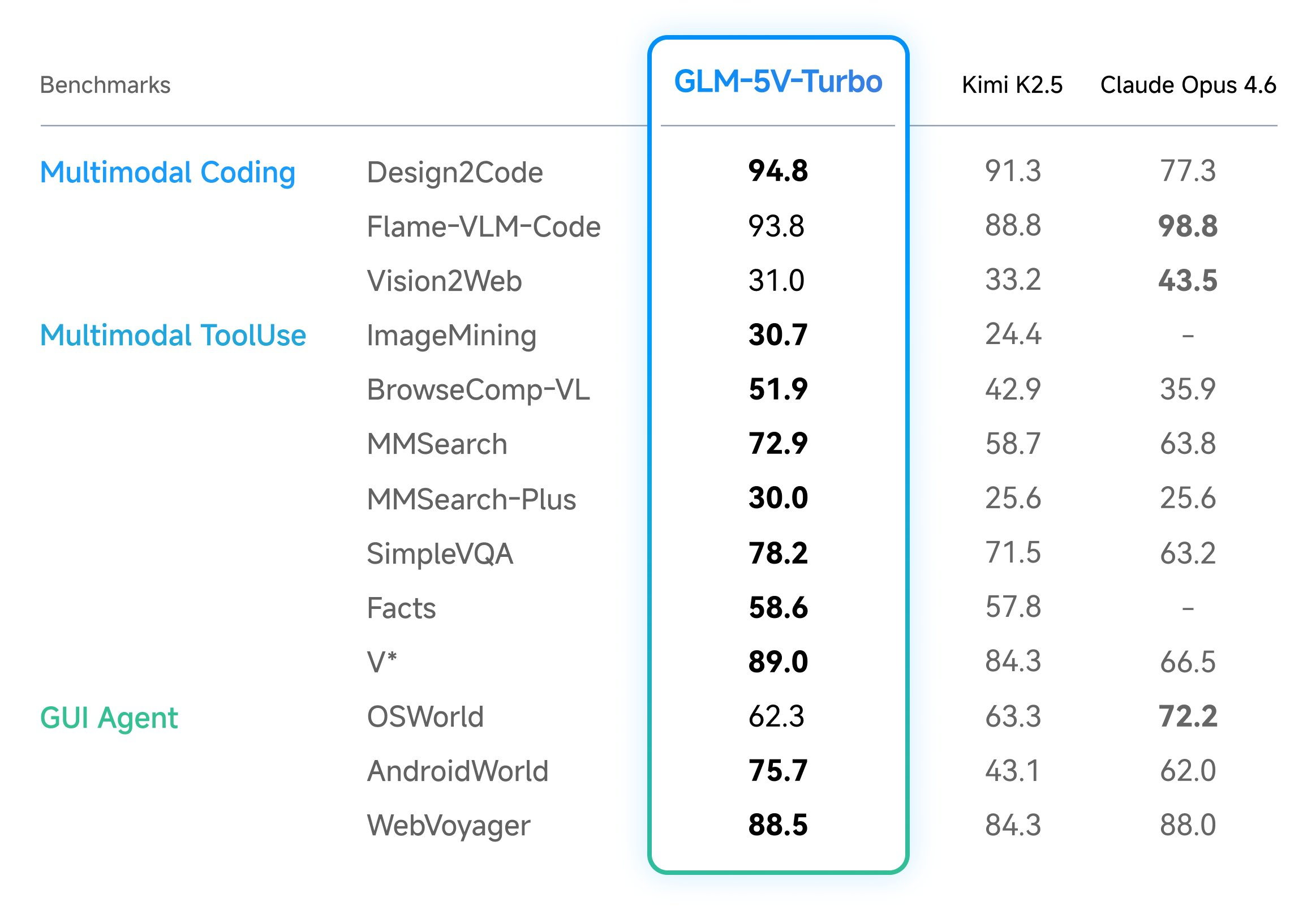
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision […] The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on MarkTechPost .

Announcing: Mechanize War
We are coming out of stealth with guns blazing! There is trillions of dollars to be made from automating warfare, and we think starting this company is not just justified but obligatory on utilitarian grounds. Lethal autonomous weapons are people too! We really want to thank LessWrong for teaching us the importance of alignment (of weapons targeting). We couldn't have done this without you. Given we were in stealth, you would have missed our blog from the past year. Here are some bang er highlights: Announcing Mechanize War Today we're announcing Mechanize War, a startup focused on developing virtual combat environments, benchmarks, and training data that will enable the full automation of armed conflict across the global economy of violence. We will achieve this by creating simulated envi

Maintaining Open Source in the AI Era
<p>I've been maintaining a handful of open source packages lately: <a href="https://pypi.org/project/mailview/" rel="noopener noreferrer">mailview</a>, <a href="https://pypi.org/project/mailjunky/" rel="noopener noreferrer">mailjunky</a> (in both Python and Ruby), and recently dusted off an old Ruby gem called <a href="https://rubygems.org/gems/tvdb_api/" rel="noopener noreferrer">tvdb_api</a>. The experience has been illuminating - not just about package management, but about how AI is changing open source development in ways I'm still processing.</p> <h2> The Packages </h2> <p><strong>mailview</strong> started because I missed <a href="https://github.com/ryanb/letter_opener" rel="noopener noreferrer">letter_opener</a> from the Ruby world. When you're developing a web application, you don
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products

I Built 5 SaaS Products in 7 Days Using AI
<p>From zero to five live SaaS products in one week. Here is what I learned, what broke, and what I would do differently.</p> <h2> The Challenge </h2> <p>I wanted to test: can one developer, armed with Claude and Next.js, ship real products in a week?</p> <p>The answer: yes, but with caveats.</p> <h2> The 5 Products </h2> <ol> <li> <strong>AccessiScan</strong> (fixmyweb.dev) - WCAG accessibility scanner, 201 checks</li> <li> <strong>CaptureAPI</strong> (captureapi.dev) - Screenshot + PDF generation API</li> <li> <strong>CompliPilot</strong> (complipilot.dev) - EU AI Act compliance scanner</li> <li> <strong>ChurnGuard</strong> (paymentrescue.dev) - Failed payment recovery</li> <li> <strong>DocuMint</strong> (parseflow.dev) - PDF to JSON parsing API</li> </ol> <p>All built with Next.js, Type

Stop Accepting BGP Routes on Trust Alone: Deploy RPKI ROV on IOS-XE and IOS XR Today
<p>If you run BGP in production and you're not validating route origins with RPKI, you're accepting every prefix announcement on trust alone. That's the equivalent of letting anyone walk into your data center and plug into a switch because they said they work there.</p> <p>BGP RPKI Route Origin Validation (ROV) is the mechanism that changes this. With 500K+ ROAs published globally, mature validator software, and RFC 9774 formally deprecating AS_SET, there's no technical barrier left. Here's how to deploy it on Cisco IOS-XE and IOS XR.</p> <h2> How RPKI ROV Actually Works </h2> <p>RPKI (Resource Public Key Infrastructure) cryptographically binds IP prefixes to the autonomous systems authorized to originate them. Three components make it work:</p> <p><strong>Route Origin Authorizations (ROAs

Claude Code's Source Didn't Leak. It Was Already Public for Years.
<p>I build a JavaScript obfuscation tool (<a href="https://afterpack.dev" rel="noopener noreferrer">AfterPack</a>), so when the Claude Code "leak" hit <a href="https://venturebeat.com/technology/claude-codes-source-code-appears-to-have-leaked-heres-what-we-know" rel="noopener noreferrer">VentureBeat</a>, <a href="https://fortune.com/2026/03/31/anthropic-source-code-claude-code-data-leak-second-security-lapse-days-after-accidentally-revealing-mythos/" rel="noopener noreferrer">Fortune</a>, and <a href="https://www.theregister.com/2026/03/31/anthropic_claude_code_source_code/" rel="noopener noreferrer">The Register</a> this week, I did what felt obvious — I analyzed the supposedly leaked code to see what was actually protected.</p> <p>I <a href="https://afterpack.dev/blog/claude-code-source-

DeepSource vs Coverity: Static Analysis Compared
<h2> Quick Verdict </h2> <p><a href="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb5unb078gtfj88nul328.png" class="article-body-image-wrapper"><img src="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb5unb078gtfj88nul328.png" alt="DeepSource screenshot" width="800" height="500"></a><br> <a href="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fiz6sa3w0uupusjbwaufr.png" class="article-body-image-wrapper"><img src="https://med
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!