

I Built a Cross-Platform Memory Layer for AI Agents Using Ebbinghaus Forgetting Curves
<p>I use Claude Code, Cursor, and Codex daily. And every single one of them forgets who I am between sessions.</p> <p>I'd tell Claude Code I prefer Python for backend work. Three sessions later, it suggests TypeScript. I'd set up a project structure in Cursor, switch to Codex for a quick fix — and it has no idea what I'm working on. Each tool has its own isolated memory, and none of them talk to each other.</p> <p>I tried the usual fixes. Dumped context into a vector store. Built a RAG pipeline. It worked — until the store had hundreds of entries and a two-year-old preference outranked something I said yesterday, just because the phrasing matched better. The retrieval had no sense of time.</p> <p>That's when I started reading about Hermann Ebbinghaus.</p> <h2> A 140-year-old experiment tha
I live with Claude Code. It's where I build everything — my API, my infrastructure, my marketing copy. But every new session starts the same way: Claude has no idea who I am.
I'd tell it I prefer Python for backend work. Three sessions later, it suggests TypeScript. I'd explain my project architecture on Monday. By Wednesday, gone. I was re-explaining the same context every single day.
And if you're using Cursor, Codex, or Windsurf, you have this problem too — except worse. Because even if one tool starts remembering, the moment you switch to another, you're back to zero. Each tool is an island.
I tried the usual fixes. Dumped context into a vector store. Built a RAG pipeline. It worked — until the store had hundreds of entries and a two-month-old preference outranked something I said yesterday, just because the phrasing matched better. The retrieval had no sense of time.
That's when I started reading about Hermann Ebbinghaus.
A 140-year-old experiment that changes everything
In 1885, a German psychologist named Hermann Ebbinghaus spent years memorizing nonsense syllables — things like "DAX," "BUP," "ZOL" — and testing how quickly he forgot them. His results produced one of the most replicated findings in all of psychology: the forgetting curve.
The core insight: memory retention decays exponentially. You don't gradually forget things in a linear way — you lose most of the information quickly, then the remainder fades slowly. But here's the part that got me: every time you recall something, the decay rate slows down. Memories you access frequently become durable. Memories you never revisit fade to nothing.
This mapped perfectly to what I needed. A preference mentioned once three months ago should carry less weight than something reinforced yesterday. Frequently accessed context should be strong. Old, unreinforced trivia should quietly disappear.
The math behind it
Ebbinghaus's forgetting curve:
R = e^(-t / S)
Enter fullscreen mode
Exit fullscreen mode
Where:
-
R = retention (0 to 1)
-
t = time elapsed since the memory was formed
-
S = memory strength (higher = slower decay)
This is the same math behind spaced repetition systems like Anki. I realized I could apply it to AI agent memory.
What I built
I built Smara — a memory API that combines semantic vector search with Ebbinghaus decay scoring. Every stored memory gets an importance score between 0 and 1. At query time, importance scales the memory strength, so high-importance memories decay slowly while trivial ones fade fast.
The retrieval score blends semantic relevance with temporal decay. Semantic search stays dominant — you still get the most relevant memories — but recency breaks ties. A moderately relevant memory from yesterday can outrank a highly relevant one from three months ago.
I also track access patterns. Every time a memory is retrieved, it gets reinforced — frequently accessed memories stay strong. Memories nobody asks about quietly fade. The specific weights took a while to tune, but the principle is simple: relevance × recency × reinforcement.
The entire API is three calls:
Store a memory:
curl -X POST https://api.smara.io/v1/memories \ -H "Authorization: Bearer YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "user_id": "user_abc", "fact": "Prefers Python over TypeScript for backend work", "importance": 0.8 }'curl -X POST https://api.smara.io/v1/memories \ -H "Authorization: Bearer YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "user_id": "user_abc", "fact": "Prefers Python over TypeScript for backend work", "importance": 0.8 }'Enter fullscreen mode
Exit fullscreen mode
Search with decay-aware ranking:
curl "https://api.smara.io/v1/memories/search?\ user_id=user_abc&q=what+language+for+backend&limit=5" \ -H "Authorization: Bearer YOUR_API_KEY"curl "https://api.smara.io/v1/memories/search?\ user_id=user_abc&q=what+language+for+backend&limit=5" \ -H "Authorization: Bearer YOUR_API_KEY"Enter fullscreen mode
Exit fullscreen mode
The response gives you similarity, decay_score, and the blended score — you can see exactly why a memory was ranked where it was.
Get full user context for your LLM prompt:
curl "https://api.smara.io/v1/users/user_abc/context" \ -H "Authorization: Bearer YOUR_API_KEY"curl "https://api.smara.io/v1/users/user_abc/context" \ -H "Authorization: Bearer YOUR_API_KEY"Enter fullscreen mode
Exit fullscreen mode
Drop the context string into your system prompt and your agent knows who it's talking to.
The cross-platform problem nobody's solving
Building the API was the easy part. The real insight came from dogfooding it.
I had Smara wired into Claude Code via MCP. It worked great — my sessions finally had persistent memory. Claude remembered my preferences, my project context, my architecture decisions. It felt like a different tool.
Then I thought: what about developers using Cursor? Or Codex? Or switching between multiple tools throughout the day? Their memory is siloed in each tool, and none of it carries over. Even Claude Code's built-in memory doesn't follow you to Cursor.
So I made Smara platform-agnostic. Every memory is tagged with its source — which tool stored it — but all memories live in one pool:
{ "fact": "Prefers Python over TypeScript for backend work", "source": "claude-code", "namespace": "default", "decay_score": 0.97 }{ "fact": "Prefers Python over TypeScript for backend work", "source": "claude-code", "namespace": "default", "decay_score": 0.97 }Enter fullscreen mode
Exit fullscreen mode
A preference stored via Claude Code is instantly available in Cursor, Codex, or anything else connected to the same account.
For MCP-compatible tools (Claude Code, Cursor, Windsurf), I built an MCP server that handles everything automatically. Add this to your MCP config and restart:
{ "smara": { "command": "npx", "args": ["-y", "@smara/mcp-server"], "env": { "SMARA_API_KEY": "your-key" } } }{ "smara": { "command": "npx", "args": ["-y", "@smara/mcp-server"], "env": { "SMARA_API_KEY": "your-key" } } }Enter fullscreen mode
Exit fullscreen mode
That's it. No manual tool calls. The MCP server instructs the LLM to:
-
At conversation start: Automatically load stored context
-
During conversation: Silently store new facts as they come up
-
On explicit request: Handle "remember this" and "forget that"
You don't configure rules or triggers. The LLM decides what's worth remembering. The Ebbinghaus decay does the rest.
For OpenAI-compatible tools (Codex, ChatGPT, custom GPTs), there's a proxy endpoint that accepts OpenAI function calls. Same memory pool, different protocol. So if you're a Cursor user, a Codex user, or you bounce between tools — your context travels with you.
The result: I store my preferences in Claude Code. A Cursor user on the same Smara account sees that context instantly. Switch to Codex — same memories. One pool, every tool.
How this compares to what's out there
RAG / vanilla vector search. This is where most teams start. Embed everything, retrieve by cosine similarity. Works until your store grows and old entries outrank recent ones because the phrasing happened to match better. No sense of time.
Graph memory (Mem0, etc). Knowledge graphs capture entity relationships, which is powerful for certain use cases. But the setup cost is high — entity extraction, relationship mapping, graph traversal. For most agent memory needs (preferences, decisions, project context), it's over-engineered.
Key-value stores (Redis, DynamoDB). Fast and simple, but no semantic search. You can only retrieve by exact key, which means your agent needs to know exactly what it's looking for.
What I built: Semantic search combined with Ebbinghaus decay. Fuzzy matching that respects time, plus automatic contradiction detection — if a preference changes, the old memory is replaced, not stacked. Three REST endpoints, no SDK to learn. Decay runs at query time, no batch jobs.
What I learned
The biggest surprise was how much a simple decay term changes the feel of agent conversations. With flat retrieval, agents feel like they're reading from a database. With decay-aware retrieval, they feel like they actually know you. Recent interactions carry more weight. Repeated topics build stronger memories. Old noise fades naturally.
The second surprise was that the cross-platform piece matters more than the memory science. Developers don't just use one AI tool — they use three or four. The siloed memory problem is what actually hurts day to day.
If you're building agents that talk to users more than once, or you're tired of Cursor, Codex, or Claude Code forgetting everything between sessions — Smara has a free tier (10,000 memories, no credit card). MCP setup takes 30 seconds. REST API works with anything.
I'm building this in public and would love feedback — especially from Cursor and Codex users. I built this for Claude Code, but the cross-platform piece is where it gets interesting. What memory solutions are you using? What's working, what's not?
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
claudeavailableapplication
Agentic AI deployment best practices: 3 core areas
The demos look slick. The pressure to deploy is real. But for most enterprises, agentic AI stalls long before it scales. Pilots that function in controlled environments collapse under production pressure, where reliability, security, and operational complexity raise the stakes. At the same time, governance gaps create compliance and data exposure risks before teams realize... The post Agentic AI deployment best practices: 3 core areas appeared first on DataRobot .
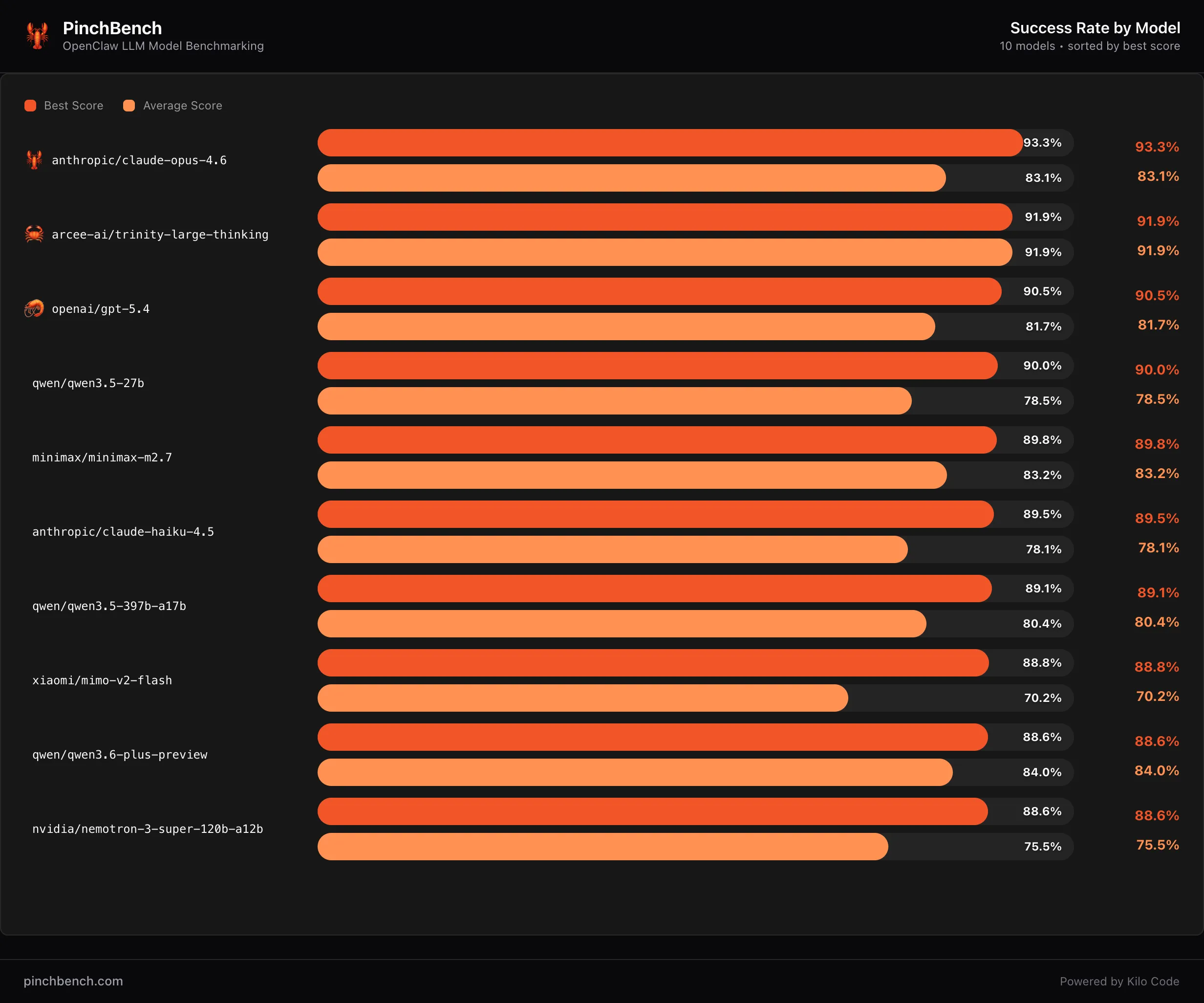
Arcee AI Releases Trinity Large Thinking: An Apache 2.0 Open Reasoning Model for Long-Horizon Agents and Tool Use
The landscape of open-source artificial intelligence has shifted from purely generative models toward systems capable of complex, multi-step reasoning. While proprietary reasoning models have dominated the conversation, Arcee AI has released Trinity Large Thinking. This release is an open-weight reasoning model distributed under the Apache 2.0 license, positioning it as a transparent alternative for developers [ ] The post Arcee AI Releases Trinity Large Thinking: An Apache 2.0 Open Reasoning Model for Long-Horizon Agents and Tool Use appeared first on MarkTechPost .
The agentic AI cost problem no one talks about: slow iteration cycles
Imagine a factory floor where every machine is running at full capacity. The lights are on, the equipment is humming, the engineers are busy. Nothing is shipping. The bottleneck isn’t production capacity. It s the quality control loop that takes three weeks every cycle, holds everything up, and costs the same whether the line is moving... The post The agentic AI cost problem no one talks about: slow iteration cycles appeared first on DataRobot .
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in AI Tools

How Will The Military Use Quantum Artificial Intelligence? Quantum AI May Reshape Military Planning Before It Reaches the Battlefield - The Quantum Insider
How Will The Military Use Quantum Artificial Intelligence? Quantum AI May Reshape Military Planning Before It Reaches the Battlefield The Quantum Insider

I Turned My Boring Daily Routine Into a $1,200/Month AI Side Hustle – With Zero Coding and Only 2…
How I automated my everyday annoying tasks with AI and turned them into a quiet, growing income stream – and exactly how you can start the… Continue reading on Medium »
They thought they were downloading Claude Code source. They got a nasty dose of malware instead
Source code with a side of Vidar stealer and GhostSocks Tens of thousands of people eagerly downloaded the leaked Claude Code source code this week, and some of those downloads came with a side of credential-stealing malware.…

Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!