
How Bifrost Reduces GPT Costs and Response Times with Semantic Caching
<h2> TL;DR </h2> <p>Every GPT API call costs money and takes time. If your app sends the same (or very similar) prompts repeatedly, you are paying full price each time for answers you already have. <a href="https://git.new/bifrost" rel="noopener noreferrer">Bifrost</a>, an open-source LLM gateway, ships with a <a href="https://docs.getbifrost.ai/features/semantic-caching" rel="noopener noreferrer">semantic caching</a> plugin that uses dual-layer caching: exact hash matching plus <a href="https://docs.getbifrost.ai/architecture/framework/vector-store" rel="noopener noreferrer">vector similarity search</a>. Cache hits cost zero. Semantic matches cost only the embedding lookup. This post walks you through how it works and how to set it up.</p> <h2> The cost problem with GPT API calls </h2> <p
TL;DR
Every GPT API call costs money and takes time. If your app sends the same (or very similar) prompts repeatedly, you are paying full price each time for answers you already have. Bifrost, an open-source LLM gateway, ships with a semantic caching plugin that uses dual-layer caching: exact hash matching plus vector similarity search. Cache hits cost zero. Semantic matches cost only the embedding lookup. This post walks you through how it works and how to set it up.
The cost problem with GPT API calls
If you are building anything production-grade with GPT-4, GPT-4o, or any OpenAI model, you already know that API costs add up fast. Token-based pricing means every request burns through your budget, whether it is a fresh question or something your system answered three minutes ago.
Here is the thing: in most real applications, a significant portion of requests are either identical or semantically similar to previous ones. Think about it. Customer support bots get asked the same questions in slightly different words. Code assistants receive near-identical prompts from different users. RAG pipelines retrieve similar context and ask similar follow-ups.
Without caching, you pay full model cost for every single one of those requests. You also wait for the full round-trip to the provider each time, adding latency that your users notice.
The obvious fix is caching. But traditional exact-match caching has a big limitation: it only works when the prompt is character-for-character identical. Change one word, add a comma, rephrase slightly, and you get a cache miss. That is where semantic caching changes the game.
What semantic caching is and how it differs from exact-match caching
Exact-match caching hashes the entire request and looks up that hash. If the hash matches a stored response, you get a cache hit. If even one character is different, it is a miss. This works well for automated pipelines where prompts are templated and predictable. It falls apart for user-facing applications where people phrase things differently.
Semantic caching converts the request into a vector embedding and searches for similar embeddings in a vector store. If a stored request is semantically similar enough (above a configurable threshold), the cached response is returned. This means "How do I reset my password?" and "What are the steps to change my password?" can both hit the same cache entry.
Bifrost combines both approaches in a dual-layer architecture, giving you the speed of exact matching with the intelligence of semantic similarity as a fallback.
How Bifrost implements dual-layer caching
Bifrost's semantic cache plugin uses a two-step lookup process for every request that has a cache key:
Layer 1: Exact hash match. The plugin hashes the request and checks for a direct match. This is the fastest path. If it hits, you get the cached response with zero additional cost. No embedding generation, no vector search, no provider call.
Layer 2: Semantic similarity search. If the exact match misses, Bifrost generates an embedding for the request and searches the vector store for semantically similar entries. If a match is found above the similarity threshold (default 0.8), the cached response is returned. The only cost here is the embedding generation.
If both layers miss, the request goes to the LLM provider as normal. The response is then stored in the vector store with its embedding for future lookups.
You can also control which layer to use per request. If you know your use case only needs exact matching (templated prompts), you can skip the semantic layer entirely. If you want semantic-only, that is an option too. The default is both, with direct matching first and semantic as fallback.
Here is how the cost breaks down:
Scenario LLM API Cost Embedding Cost Total Cost
Exact cache hit Zero Zero Zero
Semantic cache hit Zero Embedding only Minimal
Cache miss Full model cost Embedding generation Full + embedding
Bifrost also handles cost calculation natively through CalculateCostWithCacheDebug, which automatically accounts for cache hits, semantic matches, and misses in your cost tracking. All pricing data is cached in memory for O(1) lookup, so the cost calculation itself adds no overhead.
Check out the full Bifrost documentation for the complete API reference.
Setting it up
Follow the setup guide to get Bifrost running, then configure two things: a vector store and the semantic cache plugin.
Step 1: Configure the vector store
Bifrost uses Weaviate as its vector store. You can run Weaviate locally with Docker or use Weaviate Cloud.
Local setup with Docker:
docker run -d \ -p 8080:8080 \ -p 50051:50051 \ -e PERSISTENCE_DATA_PATH='/var/lib/weaviate' \ semitechnologies/weaviate:latestdocker run -d \ -p 8080:8080 \ -p 50051:50051 \ -e PERSISTENCE_DATA_PATH='/var/lib/weaviate' \ semitechnologies/weaviate:latestEnter fullscreen mode
Exit fullscreen mode
config.json (local Weaviate):
{ "vector_store": { "enabled": true, "type": "weaviate", "config": { "host": "localhost:8080", "scheme": "http" } } }{ "vector_store": { "enabled": true, "type": "weaviate", "config": { "host": "localhost:8080", "scheme": "http" } } }Enter fullscreen mode
Exit fullscreen mode
config.json (Weaviate Cloud):
{ "vector_store": { "enabled": true, "type": "weaviate", "config": { "host": "your-cluster.weaviate.network", "scheme": "https", "api_key": "your-weaviate-api-key" } } }{ "vector_store": { "enabled": true, "type": "weaviate", "config": { "host": "your-cluster.weaviate.network", "scheme": "https", "api_key": "your-weaviate-api-key" } } }Enter fullscreen mode
Exit fullscreen mode
Step 2: Configure the semantic cache plugin
Add the plugin to your Bifrost config:
{ "plugins": [ { "enabled": true, "name": "semantic_cache", "config": { "provider": "openai", "embedding_model": "text-embedding-3-small", "ttl": "5m", "threshold": 0.8, "conversation_history_threshold": 3, "exclude_system_prompt": false, "cache_by_model": true, "cache_by_provider": true, "cleanup_on_shutdown": true } } ] }{ "plugins": [ { "enabled": true, "name": "semantic_cache", "config": { "provider": "openai", "embedding_model": "text-embedding-3-small", "ttl": "5m", "threshold": 0.8, "conversation_history_threshold": 3, "exclude_system_prompt": false, "cache_by_model": true, "cache_by_provider": true, "cleanup_on_shutdown": true } } ] }Enter fullscreen mode
Exit fullscreen mode
A few things to note about these settings:
-
threshold: The similarity score (0 to 1) required for a semantic match. 0.8 is a good starting point. Higher means stricter matching, fewer false positives, but more cache misses.
-
conversation_history_threshold: Defaults to 3. If a conversation has more messages than this, caching is skipped. Long conversations have high probability of false positive semantic matches due to topic overlap, and they rarely produce exact hash matches anyway.
-
ttl: How long cached responses stay valid. Accepts duration strings like "30s", "5m", "1h", or numeric seconds.
-
cache_by_model and cache_by_provider: When true, cache entries are isolated per model and provider combination. A GPT-4 response will not be returned for a GPT-3.5-turbo request.
Step 3: Trigger caching per request
Caching is opt-in per request. You need to set a cache key, either via the Go SDK or HTTP headers:
HTTP API:
# This request WILL be cached curl -H "x-bf-cache-key: session-123" \ -H "Content-Type: application/json" \ -d '{"model": "gpt-4", "messages": [{"role": "user", "content": "What is semantic caching?"}]}' \ http://localhost:8080/v1/chat/completions# This request WILL be cached curl -H "x-bf-cache-key: session-123" \ -H "Content-Type: application/json" \ -d '{"model": "gpt-4", "messages": [{"role": "user", "content": "What is semantic caching?"}]}' \ http://localhost:8080/v1/chat/completionsEnter fullscreen mode
Exit fullscreen mode
Go SDK:
ctx = context.WithValue(ctx, semanticcache.CacheKey, "session-123") response, err := client.ChatCompletionRequest(ctx, request)ctx = context.WithValue(ctx, semanticcache.CacheKey, "session-123") response, err := client.ChatCompletionRequest(ctx, request)Enter fullscreen mode
Exit fullscreen mode
Without the cache key, requests bypass caching entirely. This gives you fine-grained control over what gets cached and what does not.
Per-request overrides (HTTP):
curl -H "x-bf-cache-key: session-123" \ -H "x-bf-cache-ttl: 30s" \ -H "x-bf-cache-threshold: 0.9" \ http://localhost:8080/v1/chat/completionscurl -H "x-bf-cache-key: session-123" \ -H "x-bf-cache-ttl: 30s" \ -H "x-bf-cache-threshold: 0.9" \ http://localhost:8080/v1/chat/completionsEnter fullscreen mode
Exit fullscreen mode
Cache type control:
# Direct hash matching only (fastest, no embedding cost) curl -H "x-bf-cache-key: session-123" \ -H "x-bf-cache-type: direct" ...# Direct hash matching only (fastest, no embedding cost) curl -H "x-bf-cache-key: session-123" \ -H "x-bf-cache-type: direct" ...Semantic similarity search only
curl -H "x-bf-cache-key: session-123"
-H "x-bf-cache-type: semantic" ...
Default: both (direct first, semantic fallback)
curl -H "x-bf-cache-key: session-123" ...`
Enter fullscreen mode
Exit fullscreen mode
You can also use no-store mode to read from cache without storing the response:
curl -H "x-bf-cache-key: session-123" \ -H "x-bf-cache-no-store: true" ...curl -H "x-bf-cache-key: session-123" \ -H "x-bf-cache-no-store: true" ...Enter fullscreen mode
Exit fullscreen mode
When semantic caching helps vs when it does not
Semantic caching is not a universal solution. Here is where it works well and where it does not.
Good fit:
-
Customer support bots where users ask the same questions in different words
-
FAQ-style applications with predictable query patterns
-
RAG pipelines where similar contexts produce similar queries
-
Internal tools where multiple team members ask overlapping questions
-
Any high-volume application with repetitive prompt patterns
Not a good fit:
-
Conversations that are heavily context-dependent and unique every time
-
Long multi-turn conversations (the conversation_history_threshold exists for this reason, as longer conversations create false positive matches)
-
Applications where responses must reflect real-time data that changes frequently
-
Creative generation tasks where you want varied outputs for similar inputs
The key insight is that semantic caching works best when your application naturally produces clusters of similar requests. If every request is genuinely unique, caching of any kind will not help much.
Other performance details worth knowing
Beyond semantic caching, Bifrost caches aggressively at multiple levels:
-
Tool discovery is cached after the first request, bringing subsequent lookups down to roughly 100-500 microseconds.
-
Health check results are cached at approximately 50 nanoseconds.
-
All pricing data is cached in memory for O(1) lookups during cost calculations.
Cache entries use namespace isolation. Each Bifrost instance gets its own vector store namespace to prevent conflicts. When the Bifrost client shuts down (with cleanup_on_shutdown set to true), all cache entries and the namespace itself are cleaned up. You can also programmatically clear cache by key or clear cache by request ID via the API.
Cache metadata is automatically added to responses via response.ExtraFields.CacheDebug, so you can inspect whether a response came from direct cache, semantic match, or a fresh provider call. You can also use the log statistics API for deeper observability into your cache performance.
Wrapping up
If your GPT-powered application handles any volume of requests, there is a good chance a meaningful portion of those requests are semantically similar. Paying full API cost for every one of them does not make sense.
Bifrost's semantic cache plugin gives you dual-layer caching with exact matching and vector similarity search, opt-in per request, configurable thresholds, and built-in cost tracking. It is open source, written in Go, and designed for production workloads.
Check out the GitHub repo to get started, read the docs for the full configuration reference, or visit the Bifrost website to learn more about the gateway.
DEV Community
https://dev.to/pranay_batta/how-bifrost-reduces-gpt-costs-and-response-times-with-semantic-caching-344gSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modelopen sourceopen-source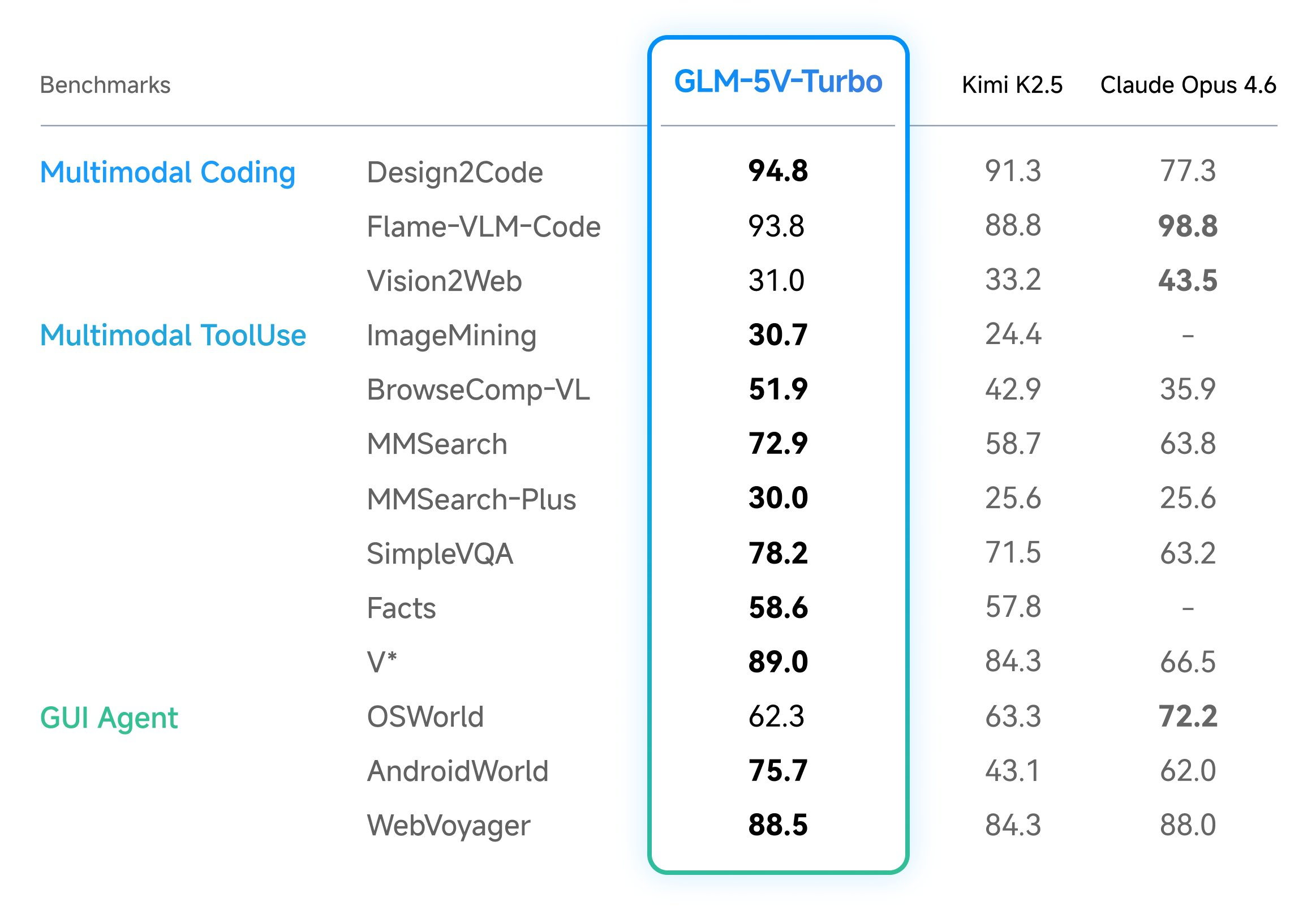
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision […] The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on MarkTechPost .

Announcing: Mechanize War
We are coming out of stealth with guns blazing! There is trillions of dollars to be made from automating warfare, and we think starting this company is not just justified but obligatory on utilitarian grounds. Lethal autonomous weapons are people too! We really want to thank LessWrong for teaching us the importance of alignment (of weapons targeting). We couldn't have done this without you. Given we were in stealth, you would have missed our blog from the past year. Here are some bang er highlights: Announcing Mechanize War Today we're announcing Mechanize War, a startup focused on developing virtual combat environments, benchmarks, and training data that will enable the full automation of armed conflict across the global economy of violence. We will achieve this by creating simulated envi

Maintaining Open Source in the AI Era
<p>I've been maintaining a handful of open source packages lately: <a href="https://pypi.org/project/mailview/" rel="noopener noreferrer">mailview</a>, <a href="https://pypi.org/project/mailjunky/" rel="noopener noreferrer">mailjunky</a> (in both Python and Ruby), and recently dusted off an old Ruby gem called <a href="https://rubygems.org/gems/tvdb_api/" rel="noopener noreferrer">tvdb_api</a>. The experience has been illuminating - not just about package management, but about how AI is changing open source development in ways I'm still processing.</p> <h2> The Packages </h2> <p><strong>mailview</strong> started because I missed <a href="https://github.com/ryanb/letter_opener" rel="noopener noreferrer">letter_opener</a> from the Ruby world. When you're developing a web application, you don
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products

I Built 5 SaaS Products in 7 Days Using AI
<p>From zero to five live SaaS products in one week. Here is what I learned, what broke, and what I would do differently.</p> <h2> The Challenge </h2> <p>I wanted to test: can one developer, armed with Claude and Next.js, ship real products in a week?</p> <p>The answer: yes, but with caveats.</p> <h2> The 5 Products </h2> <ol> <li> <strong>AccessiScan</strong> (fixmyweb.dev) - WCAG accessibility scanner, 201 checks</li> <li> <strong>CaptureAPI</strong> (captureapi.dev) - Screenshot + PDF generation API</li> <li> <strong>CompliPilot</strong> (complipilot.dev) - EU AI Act compliance scanner</li> <li> <strong>ChurnGuard</strong> (paymentrescue.dev) - Failed payment recovery</li> <li> <strong>DocuMint</strong> (parseflow.dev) - PDF to JSON parsing API</li> </ol> <p>All built with Next.js, Type

Stop Accepting BGP Routes on Trust Alone: Deploy RPKI ROV on IOS-XE and IOS XR Today
<p>If you run BGP in production and you're not validating route origins with RPKI, you're accepting every prefix announcement on trust alone. That's the equivalent of letting anyone walk into your data center and plug into a switch because they said they work there.</p> <p>BGP RPKI Route Origin Validation (ROV) is the mechanism that changes this. With 500K+ ROAs published globally, mature validator software, and RFC 9774 formally deprecating AS_SET, there's no technical barrier left. Here's how to deploy it on Cisco IOS-XE and IOS XR.</p> <h2> How RPKI ROV Actually Works </h2> <p>RPKI (Resource Public Key Infrastructure) cryptographically binds IP prefixes to the autonomous systems authorized to originate them. Three components make it work:</p> <p><strong>Route Origin Authorizations (ROAs

Claude Code's Source Didn't Leak. It Was Already Public for Years.
<p>I build a JavaScript obfuscation tool (<a href="https://afterpack.dev" rel="noopener noreferrer">AfterPack</a>), so when the Claude Code "leak" hit <a href="https://venturebeat.com/technology/claude-codes-source-code-appears-to-have-leaked-heres-what-we-know" rel="noopener noreferrer">VentureBeat</a>, <a href="https://fortune.com/2026/03/31/anthropic-source-code-claude-code-data-leak-second-security-lapse-days-after-accidentally-revealing-mythos/" rel="noopener noreferrer">Fortune</a>, and <a href="https://www.theregister.com/2026/03/31/anthropic_claude_code_source_code/" rel="noopener noreferrer">The Register</a> this week, I did what felt obvious — I analyzed the supposedly leaked code to see what was actually protected.</p> <p>I <a href="https://afterpack.dev/blog/claude-code-source-

DeepSource vs Coverity: Static Analysis Compared
<h2> Quick Verdict </h2> <p><a href="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb5unb078gtfj88nul328.png" class="article-body-image-wrapper"><img src="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb5unb078gtfj88nul328.png" alt="DeepSource screenshot" width="800" height="500"></a><br> <a href="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fiz6sa3w0uupusjbwaufr.png" class="article-body-image-wrapper"><img src="https://med
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!