
Google’s Gemini AI is getting a bigger role across Docs, Sheets, and Slides - The Verge
<a href="https://news.google.com/rss/articles/CBMiiAFBVV95cUxPMHdiN2dqSUwyNDlzaVRCU1RUSW1iYnZZdmgxVXJtUm9JR2pqbE5LQ3V3eWRZV3htREYwNDMwaThfYVd2RjhhQUZqZWRtVHd3aFhuOFRZMDNRbGQwUmFMTm0wckpLMThLTlZyU2RlX1ZfaGI2WThSMVEtLU9qZXlPSS11dzREUnBv?oc=5" target="_blank">Google’s Gemini AI is getting a bigger role across Docs, Sheets, and Slides</a> <font color="#6f6f6f">The Verge</font>
Could not retrieve the full article text.
Read on Google News: Gemini →Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
gemini
Qodo vs Tabnine: AI Coding Assistants Compared (2026)
Quick Verdict Qodo and Tabnine address genuinely different problems. Qodo is a code quality specialist - its entire platform is built around making PRs better through automated review and test generation. Tabnine is a privacy-first code assistant - its entire platform is built around delivering AI coding help in environments where data sovereignty cannot be compromised. Choose Qodo if: your team needs the deepest available AI PR review, you want automated test generation that proactively closes coverage gaps, you use GitLab or Azure DevOps alongside GitHub, or you want the open-source transparency of PR-Agent as your review foundation. Choose Tabnine if: your team needs AI code completion as a primary feature, your organization requires on-premise or fully air-gapped deployment with battle

Gemma 4 just casually destroyed every model on our leaderboard except Opus 4.6 and GPT-5.2. 31B params, $0.20/run
Tested Gemma 4 (31B) on our benchmark. Genuinely did not expect this. 100% survival, 5 out of 5 runs profitable, +1,144% median ROI. At $0.20 per run. It outperforms GPT-5.2 ($4.43/run), Gemini 3 Pro ($2.95/run), Sonnet 4.6 ($7.90/run), and absolutely destroys every Chinese open-source model we've tested — Qwen 3.5 397B, Qwen 3.5 9B, DeepSeek V3.2, GLM-5. None of them even survive consistently. The only model that beats Gemma 4 is Opus 4.6 at $36 per run. That's 180× more expensive. 31 billion parameters. Twenty cents. We double-checked the config, the prompt, the model ID — everything is identical to every other model on the leaderboard. Same seed, same tools, same simulation. It's just genuinely this good. Strongly recommend trying it for your agentic workflows. We've tested 22 models so

Dark Dish Lab: A Cursed Recipe Generator
What I Built Dark Dish Lab is a tiny, delightfully useless web app that generates cursed food or drink recipes. You pick: Hated ingredients Flavor chaos (salty / sweet / spicy / sour) Then it generates a short “recipe” with a horror score, a few steps, and a warning. It solves no real-world problem. It only creates regret. Demo YouTube demo Code GitHub repo How I Built It Frontend: React (Vite) Ingredient + flavor selection UI Calls backend API and renders the generated result Backend: Spring Boot (Java 17) POST /api/generate endpoint Generates a short recipe text and returns JSON Optional AI: Google Gemini API If AI is enabled and a key is provided, it asks Gemini for a very short recipe format If AI is disabled or fails, it falls back to a non-AI generator Notes Only Unicode emojis are u
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

How to Build a Netflix VOID Video Object Removal and Inpainting Pipeline with CogVideoX, Custom Prompting, and End-to-End Sample Inference
In this tutorial, we build and run an advanced pipeline for Netflix’s VOID model. We set up the environment, install all required dependencies, clone the repository, download the official base model and VOID checkpoint, and prepare the sample inputs needed for video object removal. We also make the workflow more practical by allowing secure terminal-style [ ] The post How to Build a Netflix VOID Video Object Removal and Inpainting Pipeline with CogVideoX, Custom Prompting, and End-to-End Sample Inference appeared first on MarkTechPost .
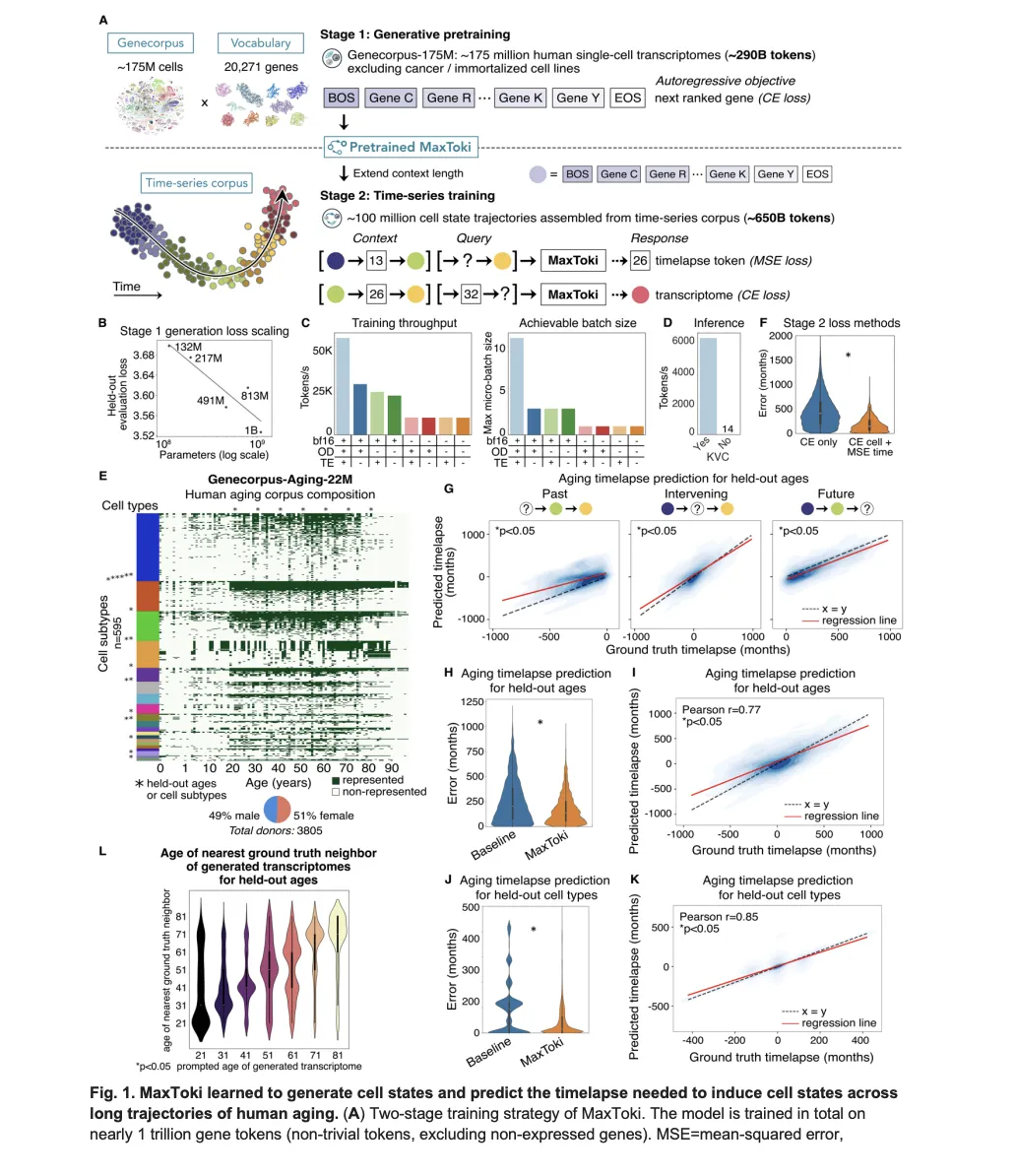
Meet MaxToki: The AI That Predicts How Your Cells Age — and What to Do About It
Most foundation models in biology have a fundamental blind spot: they see cells as frozen snapshots. Give a model a single-cell transcriptome — a readout of which genes are active in a cell at a given moment — and it can tell you a lot about what that cell is doing right now. What it [ ] The post Meet MaxToki: The AI That Predicts How Your Cells Age — and What to Do About It appeared first on MarkTechPost .


The Silent Freeze: When Your Model Runs Out of Credits Mid-Conversation
You're chatting with your agent. It's been helpful all day. You send another message and... nothing. No error. No "sorry, something went wrong." Just silence. You try again. This time it works — but with a different model. What happened to your first message? The Bug OpenClaw #61513 documents a frustrating scenario. When Anthropic returns a billing exhaustion error — specifically "You're out of extra usage" — OpenClaw doesn't recognize it as a failover-worthy error. The turn silently drops. Why Didn't Failover Catch It? OpenClaw already handled some Anthropic billing messages. But the exhaustion variant slipped through. This is string-matching error classification — every time a provider tweaks their wording, the classifier needs updating. The real issue: when an error doesn't match any kn
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!