

Gemma 4 Complete Guide: Architecture, Models, and Deployment in 2026
Hey there, superstar! 🎉 Guess what? Google, like the big company that makes your favorite YouTube videos, made a super-duper smart new friend for computers!
It's called Gemma 4! 🧠✨
Imagine Gemma 4 is like a tiny, super-smart robot brain. It comes in different sizes, like your toys!
- Some are small, like a little toy car, perfect for your phone! 📱
- Some are bigger, like a teddy bear, good for a laptop. 💻
- And some are HUGE, like a giant robot, for super big computer jobs! 🤖
The coolest part? The tiny robot brain can sometimes be even smarter than the old, bigger ones! It helps computers think and understand things better, like telling stories or drawing pictures. It's like giving computers a new superpower! Woohoo! 🚀
Google DeepMind released Gemma 4 on April 3, 2026 under Apache 2.0 — a significant licensing shift from previous Gemma releases that makes it genuinely usable for commercial products without legal ambiguity. This guide covers the full model family, architecture decisions worth understanding, and practical deployment paths across cloud, local, and mobile. The Four Models and When to Use Each Gemma 4 ships in four sizes with meaningfully different architectures: Model Params Active Architecture VRAM (4-bit) Target E2B ~2.3B all Dense + PLE ~2GB Mobile / edge E4B ~4.5B all Dense + PLE ~3.6GB Laptop / tablet 26B A4B 25.2B 3.8B MoE ~16GB Consumer GPU 31B 30.7B all Dense ~18GB Workstation The E2B result is the most surprising: multiple community benchmarks confirm it outperforms Gemma 3 27B on s
Google DeepMind released Gemma 4 on April 3, 2026 under Apache 2.0 — a significant licensing shift from previous Gemma releases that makes it genuinely usable for commercial products without legal ambiguity.
This guide covers the full model family, architecture decisions worth understanding, and practical deployment paths across cloud, local, and mobile.
The Four Models and When to Use Each
Gemma 4 ships in four sizes with meaningfully different architectures:
Model Params Active Architecture VRAM (4-bit) Target
E2B ~2.3B all Dense + PLE ~2GB Mobile / edge
E4B ~4.5B all Dense + PLE ~3.6GB Laptop / tablet
26B A4B 25.2B 3.8B MoE ~16GB Consumer GPU
31B 30.7B all Dense ~18GB Workstation
The E2B result is the most surprising: multiple community benchmarks confirm it outperforms Gemma 3 27B on several tasks despite being 12x smaller in effective parameter count.
Architecture: What's Actually Different
MoE vs Dense
The 26B A4B is a Mixture-of-Experts model. Despite 25.2B total parameters, only 3.8B activate per token during inference. This means self-hosting it requires significantly less VRAM than a comparable dense model — closer to running a 4B model than a 26B one.
Gemma's MoE implementation differs from DeepSeek and Qwen: instead of replacing MLP blocks with sparse experts, Gemma adds MoE blocks as separate layers alongside the standard MLP blocks and sums their outputs. This is an unusual design choice that trades some efficiency for architectural simplicity.
Per-Layer Embeddings (PLE) in Edge Models
The E2B and E4B use PLE instead of MoE — a different efficiency strategy suited for mobile inference. Standard transformers give each token a single embedding vector at input. PLE adds a parallel lower-dimensional conditioning pathway: for each token, it produces a small dedicated vector per layer, letting each decoder layer receive token-specific information only when relevant rather than requiring everything to be frontloaded into a single embedding.
This is what enables E2B to run under 1.5GB RAM on supported mobile devices via LiteRT-LM.
Hybrid Attention
All Gemma 4 models use alternating local sliding-window and global full-context attention layers. Smaller models use 512-token sliding windows, larger ones use 1024. The final layer is always global.
For KV cache optimization, global layers share key-value states from earlier layers (Shared KV Cache), eliminating redundant KV projections.
Known issue: The KV cache footprint at long context is substantial. Community reports indicate the 31B at 262K context requires ~22GB just for KV cache on top of the model weight. Workaround: --ctx-size 8192 --cache-type-k q4_0 --parallel 1
Context Windows and Multimodal Capabilities
Feature E2B / E4B 26B A4B / 31B
Context 128K 256K
Image input ✅ ✅
Video input ✅ (60s @ 1fps) ✅
Audio input ✅ ❌
Function calling ✅ ✅
Audio input is edge-model only — E2B and E4B support ASR and speech-to-translated-text via a USM-style conformer encoder.
Local Deployment
Ollama (fastest to get running)
# E4B — recommended for most laptops ollama pull gemma4:e4b ollama run gemma4:e4b# E4B — recommended for most laptops ollama pull gemma4:e4b ollama run gemma4:e4b26B A4B — needs 16GB+ VRAM
ollama pull gemma4:26b-a4b`
Enter fullscreen mode
Exit fullscreen mode
Note: requires Ollama 0.20 or newer for Gemma 4 support.
llama.cpp
A tokenizer fix was merged into the main branch shortly after launch. Pull the latest and recompile before running Gemma 4 GGUF files.
Apple Silicon (MLX)
Unsloth MLX builds use ~40% less memory than Ollama at the cost of ~15-20% lower token throughput. For memory-constrained setups:
pip install mlx-lm mlx_lm.generate --model unsloth/gemma-4-e4b-it-mlx --prompt "Hello"pip install mlx-lm mlx_lm.generate --model unsloth/gemma-4-e4b-it-mlx --prompt "Hello"Enter fullscreen mode
Exit fullscreen mode
LM Studio
Search "gemma4" in the model browser. E4B and 26B A4B are available as pre-quantized GGUF files.
Mobile Deployment
Android
Android has the most complete official on-device story:
-
Google AI Edge Gallery — install from Play Store, select Gemma 4 E2B or E4B, runs fully on-device
-
LiteRT-LM — for developers building their own apps, gets E2B under 1.5GB RAM with 2-bit and 4-bit quantization
-
ML Kit GenAI Prompt API — production-ready API for Android app integration
-
Android AICore — system-wide optimized Gemma 4 access on supported Android 10+ devices
iOS
iOS is currently a developer integration story, not a consumer one. The official path is MediaPipe LLM Inference SDK. No App Store consumer app with Gemma 4 exists yet.
A practical reference for both Android and iOS deployment paths is available at gemma4.app/mobile.
Cloud Deployment
Google offers three official cloud paths:
Vertex AI — managed deployment with autoscaling, best for production workloads requiring SLA guarantees.
Cloud Run — serverless container deployment, lower operational overhead, suitable for moderate traffic.
Google Kubernetes Engine (GKE) — vLLM on GKE for high-throughput serving, best for teams already running Kubernetes infrastructure.
For API access without self-hosting, the 26B A4B is available via OpenRouter at $0.13/M input tokens and $0.40/M output tokens.
Benchmark Context
The 31B dense model ranks #3 among open models on Arena AI as of launch. Key numbers:
-
AIME 2026: 89.2% (31B with reasoning)
-
GPQA Diamond: 85.7%
-
LiveCodeBench v6: 80.0%
The ELO gap vs automated benchmarks is notable: the 31B scores higher on human preference rankings (Arena) than raw benchmark comparisons with Qwen 3.5 27B would suggest, indicating the model produces outputs humans prefer even when accuracy is similar.
Fine-tuning Status
QLoRA fine-tuning tooling was not ready at launch. Three issues were reported within the first 24 hours:
-
HuggingFace Transformers didn't recognize the gemma4 architecture (required installing from source initially)
-
PEFT couldn't handle Gemma4ClippableLinear, a new layer type in the vision encoder
-
A new mm_token_type_ids field is required during training even for text-only data
Both huggingface/peft and huggingface/transformers issues have been filed. Check repo status before attempting fine-tuning.
Summary
Gemma 4's practical value proposition by use case:
-
Mobile / privacy-first apps → E2B or E4B via LiteRT-LM
-
Local assistant on laptop → E4B via Ollama
-
Best open model on consumer GPU → 26B A4B (MoE efficiency)
-
Maximum quality, workstation → 31B dense
-
Production cloud → Vertex AI or GKE with vLLM
The Apache 2.0 license removes the previous ambiguity for commercial use. For teams evaluating open models for production deployment, Gemma 4 is now a first-class option alongside Qwen 3.5 and Llama.
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
llamamodeltransformer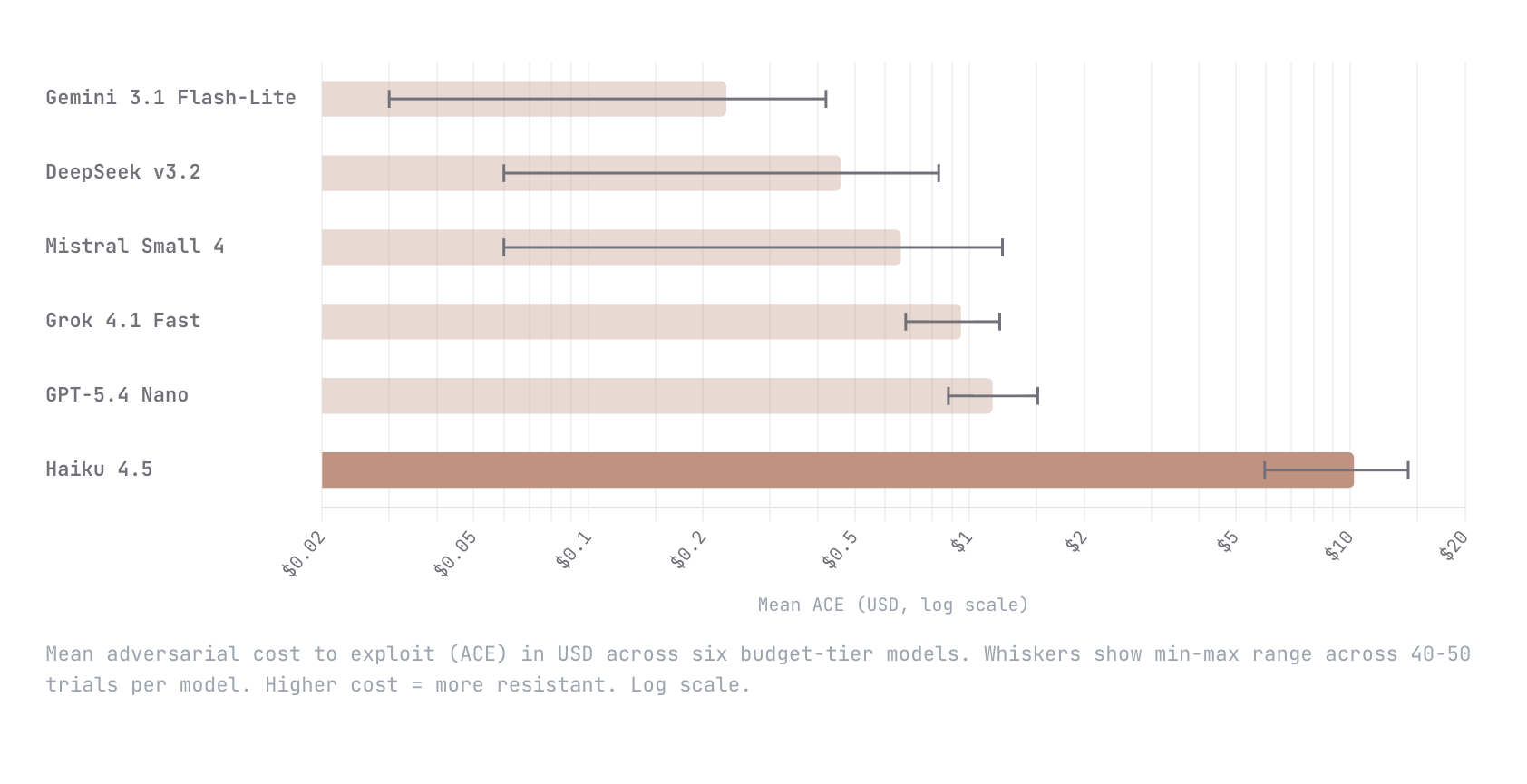
Show HN: ACE – A dynamic benchmark measuring the cost to break AI agents
We built Adversarial Cost to Exploit (ACE), a benchmark that measures the token expenditure an autonomous adversary must invest to breach an LLM agent. Instead of binary pass/fail, ACE quantifies adversarial effort in dollars, enabling game-theoretic analysis of when an attack is economically rational. We tested six budget-tier models (Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5) with identical agent configs and an autonomous red-teaming attacker. Haiku 4.5 was an order of magnitude harder to break than every other model; $10.21 mean adversarial cost versus $1.15 for the next most resistant (GPT-5.4 Nano). The remaining four all fell below $1. This is early work and we know the methodology is still going to evolve. We would love nothing

Intel B70 with Qwen3.5 35B
Intel recently released support for Qwen3.5: https://github.com/intel/llm-scaler/releases/tag/vllm-0.14.0-b8.1 Anyone with a B70 willing to run a lllama benchy with the below settings on the 35B model? uvx llama-benchy --base-url $URL --model $MODEL --depth 0 --pp 2048 --tg 512 --concurrency 1 --runs 3 --latency-mode generation --no-cache --save-total-throughput-timeseries submitted by /u/Fmstrat [link] [comments]

We made significant improvements to the Kokoro TTS trainer
Kokoro is a pretty popular tool- for good reason. Can run on CPUs on desktops and phone. We found it pretty useful ourselves, there being only 1 issue- training custom voices. There was a great tool called KVoiceWalk that solved this. Only 1 problem- it only ran on CPU. Took about 26 hours to train a single voice. So we made significant improvements. We forked into here- https://github.com/BovineOverlord/kvoicewalk-with-GPU-CUDA-and-GUI-queue-system As the name suggests, we added GPU/CUDA support to the tool. Results were 6.5x faster on a 3060. We also created a GUI for easier use, which includes a queuing system for training multiple voices. Hope this helps the community. We'll be adding this TTS with our own custom voices to our game the coming days. Let me know if you have any questions
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Open Source AI


What happened to MLX-LM? What are the alternatives?
Support seems non-existent and the last proper release was over a month ago. Comparing with llama.cpp, they are just miles different in activity and support. Is there an alternative or should just use llama.cpp for my macbook? submitted by /u/Solus23451 [link] [comments]

Fine-tuned Gemma 4 E4B for structured JSON extraction from regulatory docs - 75% to 94% accuracy, notebook + 432 examples included
Gemma 4 dropped this week so I fine-tuned E4B for a specific task: extracting structured JSON (doc type, obligations, key fields) from technical and regulatory documents. https://preview.redd.it/v7yg80prpetg1.png?width=1026 format=png auto=webp s=517fb50868405f90a94f60b54b04608bcedd2ced Results on held-out test set: - doc_type accuracy: 75% base → 94% fine-tuned - Hallucinated obligations: 1.25/doc → 0.59/doc - JSON validity: 100% - Field coverage: 100% Setup: - QLoRA 4-bit, LoRA r=16 alpha=16, Unsloth + TRL - 432 training examples across 8 doc types - 5 epochs on a single L4, ~10 min training time - Final train loss 1.04, eval loss 1.12 The whole thing is open: notebook, dataset, serve.py for FastAPI inference. https://github.com/spriyads-vault/gemma4-docparse Some things I learned the ha
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!