

EvoDR: Evolving Dispatching Rules via Large Language Model for Dynamic Flexible Assembly Flow Shop Scheduling
arXiv:2601.15738v2 Announce Type: replace Abstract: Dynamic flexible assembly flow shop scheduling with multi-product delivery is a critical combinatorial problem, characterized by kitting supply and machine flexibility. Genetic programming is widely used to automatically generate dispatching rules, enabling responsive scheduling that reduces manual effort while meeting high responsiveness demands. However, these methods are dependent on fixed terminal sets and have weak interpretability. In this article, we develop an evolving dispatching rules framework (EvoDR) that leverages the semantic understanding and generation capabilities of large language models to achieve cross-domain integration of algorithm design and scheduling knowledge. Firstly, multi-stage assembly supply decisions are mo
View PDF HTML (experimental)
Abstract:Dynamic flexible assembly flow shop scheduling with multi-product delivery is a critical combinatorial problem, characterized by kitting supply and machine flexibility. Genetic programming is widely used to automatically generate dispatching rules, enabling responsive scheduling that reduces manual effort while meeting high responsiveness demands. However, these methods are dependent on fixed terminal sets and have weak interpretability. In this article, we develop an evolving dispatching rules framework (EvoDR) that leverages the semantic understanding and generation capabilities of large language models to achieve cross-domain integration of algorithm design and scheduling knowledge. Firstly, multi-stage assembly supply decisions are modeled as priority sorting of directed edges based on heterogeneous graphs. A dual-expert co-evolution mechanism is implemented, where LLM-A generates code while LLM-S conducts scheduling analysis and reflection. Guided by improvements in hybrid evaluation, adaptive rules that fit dynamic features are continuously evolved. Experimental results show that the EvoDR achieves lower average tardiness than state-of-the-art approaches. In 24 scenarios with different resource configurations and disturbance levels totaling 480 instances, it consistently outperforms expert-designed competitors, demonstrating superior robustness.
Subjects:
Neural and Evolutionary Computing (cs.NE)
Cite as: arXiv:2601.15738 [cs.NE]
(or arXiv:2601.15738v2 [cs.NE] for this version)
https://doi.org/10.48550/arXiv.2601.15738
arXiv-issued DOI via DataCite
Submission history
From: Junhao Qiu [view email] [v1] Thu, 22 Jan 2026 08:06:40 UTC (1,837 KB) [v2] Tue, 31 Mar 2026 08:26:10 UTC (1,070 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellanguage modelannounce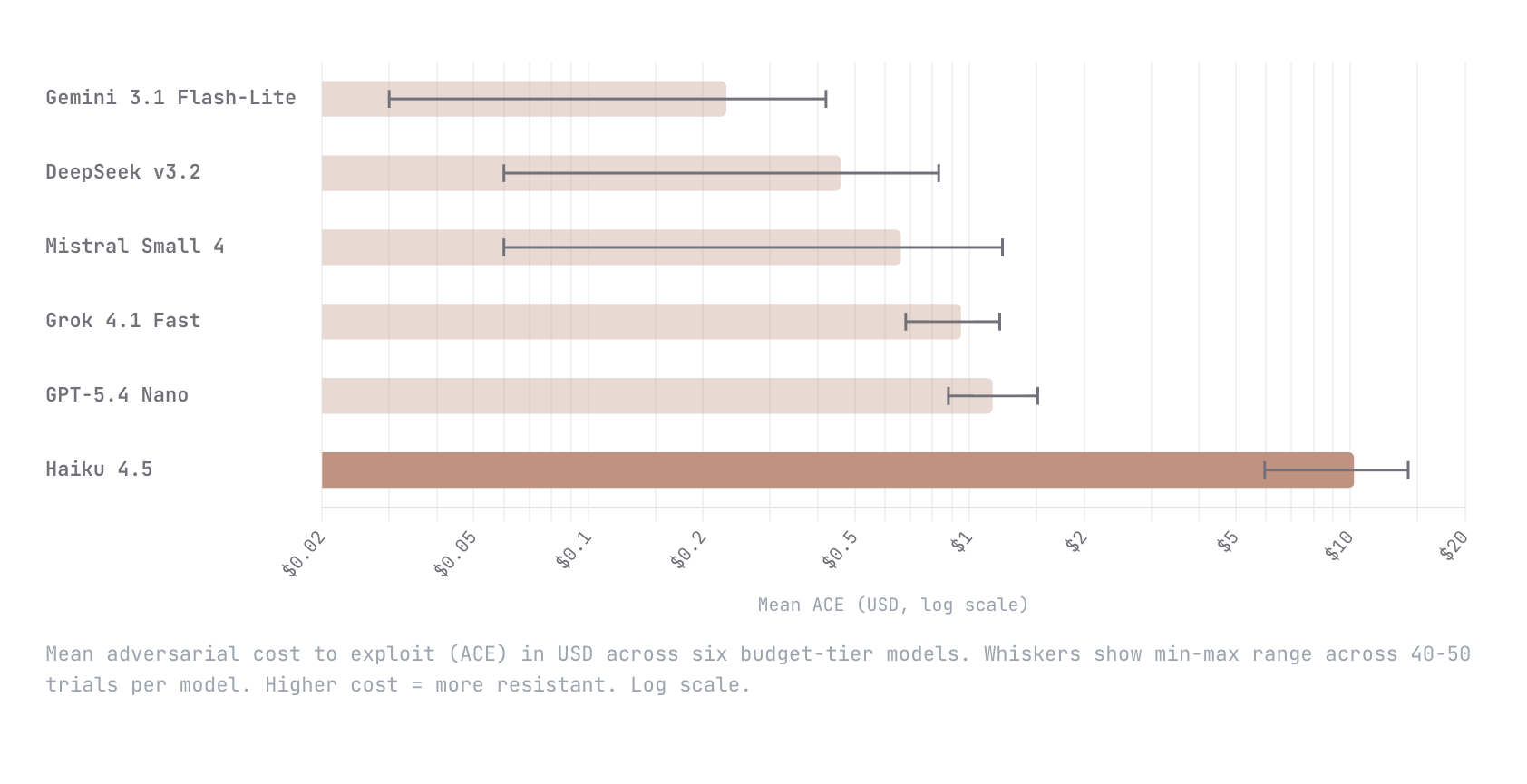
Show HN: ACE – A dynamic benchmark measuring the cost to break AI agents
We built Adversarial Cost to Exploit (ACE), a benchmark that measures the token expenditure an autonomous adversary must invest to breach an LLM agent. Instead of binary pass/fail, ACE quantifies adversarial effort in dollars, enabling game-theoretic analysis of when an attack is economically rational. We tested six budget-tier models (Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5) with identical agent configs and an autonomous red-teaming attacker. Haiku 4.5 was an order of magnitude harder to break than every other model; $10.21 mean adversarial cost versus $1.15 for the next most resistant (GPT-5.4 Nano). The remaining four all fell below $1. This is early work and we know the methodology is still going to evolve. We would love nothing

Intel B70 with Qwen3.5 35B
Intel recently released support for Qwen3.5: https://github.com/intel/llm-scaler/releases/tag/vllm-0.14.0-b8.1 Anyone with a B70 willing to run a lllama benchy with the below settings on the 35B model? uvx llama-benchy --base-url $URL --model $MODEL --depth 0 --pp 2048 --tg 512 --concurrency 1 --runs 3 --latency-mode generation --no-cache --save-total-throughput-timeseries submitted by /u/Fmstrat [link] [comments]
Dante-2B: I'm training a 2.1B bilingual fully open Italian/English LLM from scratch on 2×H200. Phase 1 done — here's what I've built.
The problem If you work with Italian text and local models, you know the pain. Every open-source LLM out there treats Italian as an afterthought — English-first tokenizer, English-first data, maybe some Italian sprinkled in during fine-tuning. The result: bloated token counts, poor morphology handling, and models that "speak Italian" the way a tourist orders coffee in Rome. I decided to fix this from the ground up. What is Dante-2B A 2.1B parameter, decoder-only, dense transformer. Trained from scratch — no fine-tune of Llama, no adapter on Mistral. Random init to coherent Italian in 16 days on 2× H200 GPUs. Architecture: LLaMA-style with GQA (20 query heads, 4 KV heads — 5:1 ratio) SwiGLU FFN, RMSNorm, RoPE d_model=2560, 28 layers, d_head=128 (optimized for Flash Attention on H200) Weight
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.




Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!