

Entropy-Preserving Reinforcement Learning
Policy gradient algorithms have driven many recent advancements in language model reasoning. An appealing property is their ability to learn from exploration on their own trajectories, a process crucial for fostering diverse and creative solutions. As we show in this paper, many policy gradient algorithms naturally reduce the entropy—and thus the diversity of explored trajectories—as part of training, yielding a policy increasingly limited in its ability to explore. In this paper, we argue that entropy should be actively monitored and controlled throughout training. We formally analyze the…
AuthorsAleksei Petrenko‡, Ben Lipkin†‡, Kevin Chen, Erik Wijmans, Marco Cusumano-Towner, Raja Giryes, Philipp Krähenbühl
Policy gradient algorithms have driven many recent advancements in language model reasoning. An appealing property is their ability to learn from exploration on their own trajectories, a process crucial for fostering diverse and creative solutions. As we show in this paper, many policy gradient algorithms naturally reduce the entropy—and thus the diversity of explored trajectories—as part of training, yielding a policy increasingly limited in its ability to explore. In this paper, we argue that entropy should be actively monitored and controlled throughout training. We formally analyze the contributions of leading policy gradient objectives on entropy dynamics, identify empirical factors (such as numerical precision) that significantly impact entropy behavior, and propose explicit mechanisms for entropy control. These include REPO, a family of algorithms that modify the advantage function to regulate entropy, and ADAPO, an adaptive asymmetric clipping approach. Models trained with our entropy-preserving methods maintain diversity throughout training, yielding final policies that are more performant and retain their trainability for sequential learning in new environments.
- † MIT
- ‡ Equal contribution
- ** Work done while at Apple**
Related readings and updates.
As language models grow ever larger, so do their vocabularies. This has shifted the memory footprint of LLMs during training disproportionately to one single layer: the cross-entropy in the loss computation. Cross-entropy builds up a logit matrix with entries for each pair of input tokens and vocabulary items and, for small models, consumes an order of magnitude more memory than the rest of the LLM combined. We propose Cut Cross-Entropy (CCE), a…
Read more
m*= Equal Contributors*
Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is…
Read more
Apple Machine Learning
https://machinelearning.apple.com/research/entropy-preserving-reinforcement-learningSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellanguage modeltraining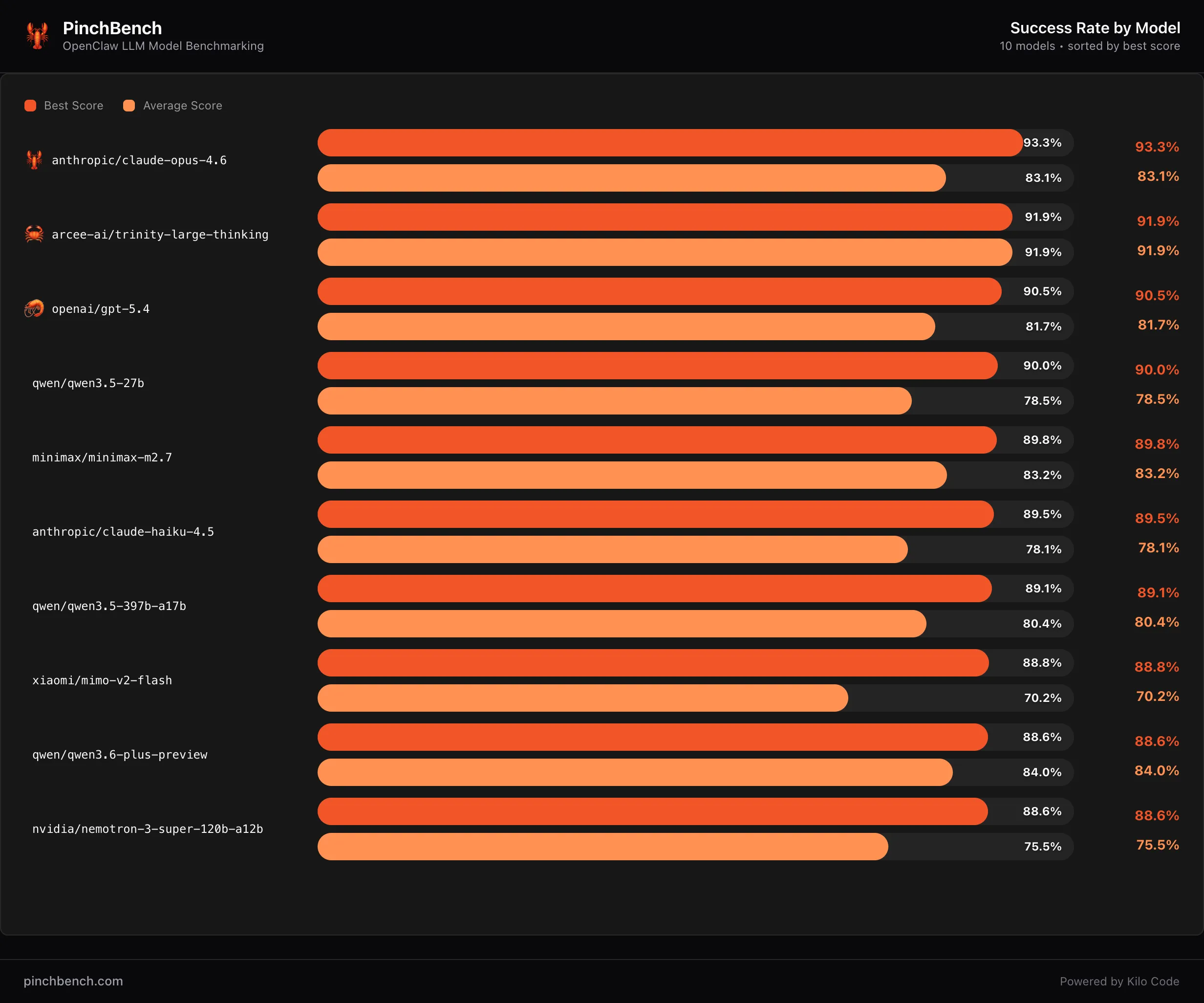
Arcee AI Releases Trinity Large Thinking: An Apache 2.0 Open Reasoning Model for Long-Horizon Agents and Tool Use
The landscape of open-source artificial intelligence has shifted from purely generative models toward systems capable of complex, multi-step reasoning. While proprietary reasoning models have dominated the conversation, Arcee AI has released Trinity Large Thinking. This release is an open-weight reasoning model distributed under the Apache 2.0 license, positioning it as a transparent alternative for developers [ ] The post Arcee AI Releases Trinity Large Thinking: An Apache 2.0 Open Reasoning Model for Long-Horizon Agents and Tool Use appeared first on MarkTechPost .

Migrating from Ralph Loops to duckflux
If you've been running coding agent tasks inside Ralph Loops , you already understand the core insight: iteration beats perfection. You've seen what happens when you hand a well-written prompt to an AI agent and let it grind until the job is done. This guide shows how to take that same philosophy and express it as a declarative, reproducible workflow in duckflux. You gain structure, observability, and composability without giving up the power of iterative automation. What are Ralph Loops? Ralph Wiggum is an iterative AI development methodology built on a deceptively simple idea: feed a prompt to a coding agent in a loop until the task is complete. Named after the Simpsons character (who stumbles forward until he accidentally succeeds), the technique treats failures as data points and bets
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

Migrating from Ralph Loops to duckflux
If you've been running coding agent tasks inside Ralph Loops , you already understand the core insight: iteration beats perfection. You've seen what happens when you hand a well-written prompt to an AI agent and let it grind until the job is done. This guide shows how to take that same philosophy and express it as a declarative, reproducible workflow in duckflux. You gain structure, observability, and composability without giving up the power of iterative automation. What are Ralph Loops? Ralph Wiggum is an iterative AI development methodology built on a deceptively simple idea: feed a prompt to a coding agent in a loop until the task is complete. Named after the Simpsons character (who stumbles forward until he accidentally succeeds), the technique treats failures as data points and bets

Я уволил отдел и нанял одного AI-агента
Когда я сказал, что уволю весь отдел, многие подумали, что это шутка. Но через месяц я оказался одним из первых в Киеве, кто доверил бизнес одному AI-агенту. Секрет оказался прост - автоматизация бизнеса с помощью AI. Отдел из пяти человек занимался обработкой заявок, отвечал клиентам, составлял отчёты и следил за воронкой продаж. На бумаге всё выглядело хорошо, но на практике работа была полна дублирования, ошибок и задержек. Человеческий фактор и 8-часовой рабочий день против 24/7 работы AI - разница была очевидна. Как только стоимость ошибок превысила зарплаты, стало ясно, что пора что-то менять. Я собрал автоматизация бизнеса с помощью AI-промпты в PDF. Забери бесплатно в Telegram (в закрепе): https://t.me/yevheniirozov Я собрал AI-агента на базе GPT-4 и Claude API, интегрировал его с
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!