
Distilling Human-Aligned Privacy Sensitivity Assessment from Large Language Models
arXiv:2603.29497v1 Announce Type: new Abstract: Accurate privacy evaluation of textual data remains a critical challenge in privacy-preserving natural language processing. Recent work has shown that large language models (LLMs) can serve as reliable privacy evaluators, achieving strong agreement with human judgments; however, their computational cost and impracticality for processing sensitive data at scale limit real-world deployment. We address this gap by distilling the privacy assessment capabilities of Mistral Large 3 (675B) into lightweight encoder models with as few as 150M parameters. Leveraging a large-scale dataset of privacy-annotated texts spanning 10 diverse domains, we train efficient classifiers that preserve strong agreement with human annotations while dramatically reducin
View PDF HTML (experimental)
Abstract:Accurate privacy evaluation of textual data remains a critical challenge in privacy-preserving natural language processing. Recent work has shown that large language models (LLMs) can serve as reliable privacy evaluators, achieving strong agreement with human judgments; however, their computational cost and impracticality for processing sensitive data at scale limit real-world deployment. We address this gap by distilling the privacy assessment capabilities of Mistral Large 3 (675B) into lightweight encoder models with as few as 150M parameters. Leveraging a large-scale dataset of privacy-annotated texts spanning 10 diverse domains, we train efficient classifiers that preserve strong agreement with human annotations while dramatically reducing computational requirements. We validate our approach on human-annotated test data and demonstrate its practical utility as an evaluation metric for de-identification systems.
Comments: Accepted to the LREC CALD-pseudo 2026 Workshop
Subjects:
Computation and Language (cs.CL)
Cite as: arXiv:2603.29497 [cs.CL]
(or arXiv:2603.29497v1 [cs.CL] for this version)
https://doi.org/10.48550/arXiv.2603.29497
arXiv-issued DOI via DataCite (pending registration)
Submission history
From: Gabriel Loiseau [view email] [v1] Tue, 31 Mar 2026 09:40:58 UTC (34 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
mistralmodellanguage modelMulti-fidelity approaches for general constrained Bayesian optimization with application to aircraft design
Aircraft design relies heavily on solving challenging and computationally expensive Multidisciplinary Design Optimization problems. In this context, there has been growing interest in multi-fidelity models for Bayesian optimization to improve the MDO process by balancing computational cost and accuracy through the combination of high- and low-fidelity simulation models, enabling efficient exploration of the design process at a minimal computational effort. In the existing literature, fidelity selection focuses only on the objective function to decide how to integrate multiple fidelity levels, — Oihan Cordelier, Youssef Diouane, Nathalie Bartoli
Transfer Learning in Bayesian Optimization for Aircraft Design
The use of transfer learning within Bayesian optimization addresses the disadvantages of the so-called \textit{cold start} problem by using source data to aid in the optimization of a target problem. We present a method that leverages an ensemble of surrogate models using transfer learning and integrates it in a constrained Bayesian optimization framework. We identify challenges particular to aircraft design optimization related to heterogeneous design variables and constraints. We propose the use of a partial-least-squares dimension reduction algorithm to address design space heterogeneity, a — Ali Tfaily, Youssef Diouane, Nathalie Bartoli
Symmetrizing Bregman Divergence on the Cone of Positive Definite Matrices: Which Mean to Use and Why
This work uncovers variational principles behind symmetrizing the Bregman divergences induced by generic mirror maps over the cone of positive definite matrices. We show that computing the canonical means for this symmetrization can be posed as minimizing the desired symmetrized divergences over a set of mean functionals defined axiomatically to satisfy certain properties. For the forward symmetrization, we prove that the arithmetic mean over the primal space is canonical for any mirror map over the positive definite cone. For the reverse symmetrization, we show that the canonical mean is the — Tushar Sial, Abhishek Halder
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models


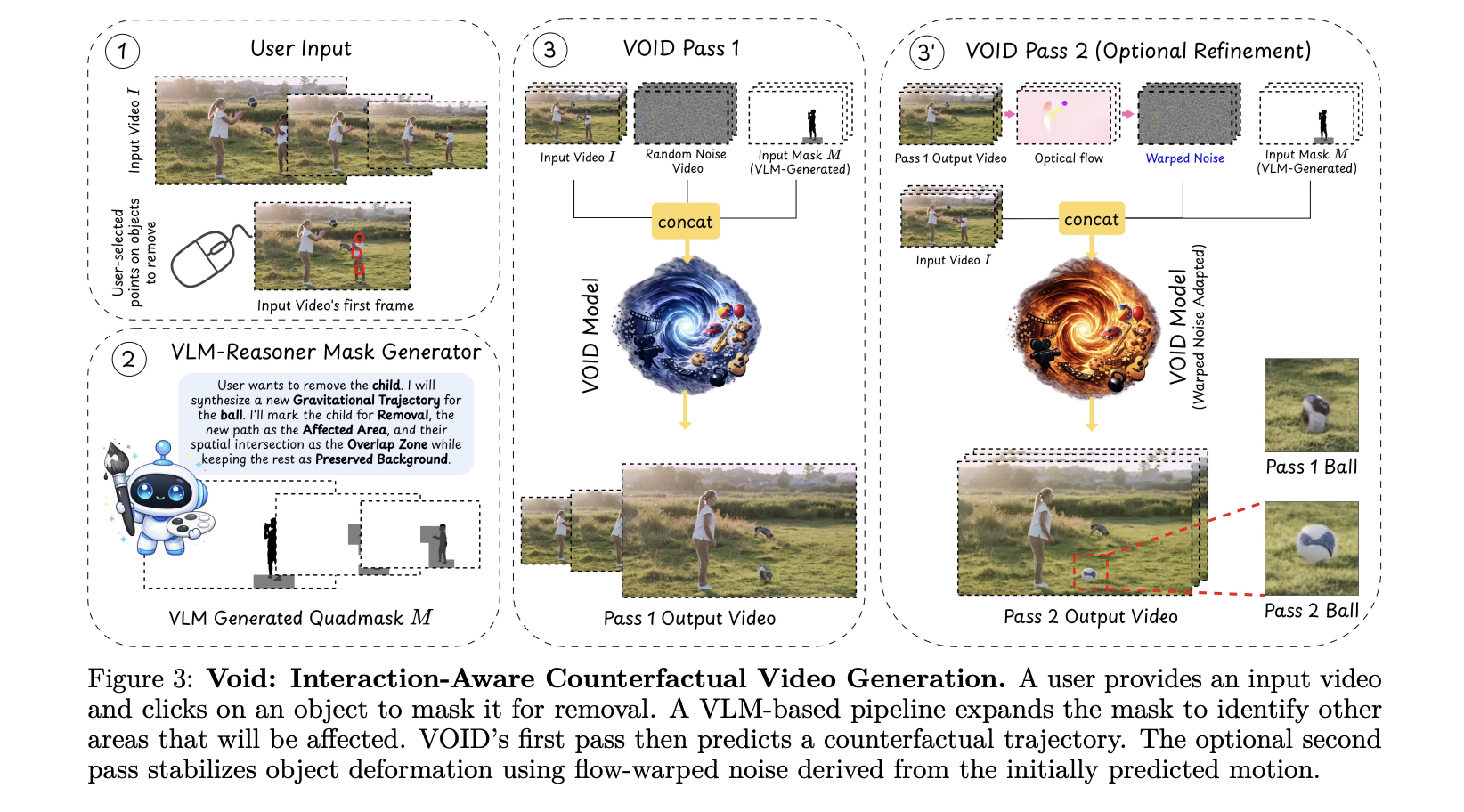
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .

Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!