

datasette-enrichments-llm 0.2a0
<p><strong>Release:</strong> <a href="https://github.com/datasette/datasette-enrichments-llm/releases/tag/0.2a0">datasette-enrichments-llm 0.2a0</a></p> <blockquote> <ul> <li>This plugin now uses <a href="https://github.com/datasette/datasette-llm">datasette-llm</a> to configure and manage models. This means it's possible to <a href="https://github.com/datasette/datasette-enrichments-llm/blob/0.2a0/README.md#configuration">specify which models</a> should be made available for enrichments, using the new <code>enrichments</code> purpose.</li> </ul> </blockquote> <p>Tags: <a href="https://simonwillison.net/tags/llm">llm</a>, <a href="https://simonwillison.net/tags/datasette">datasette</a></p>
Could not retrieve the full article text.
Read on Simon Willison Blog →Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modelreleaseavailable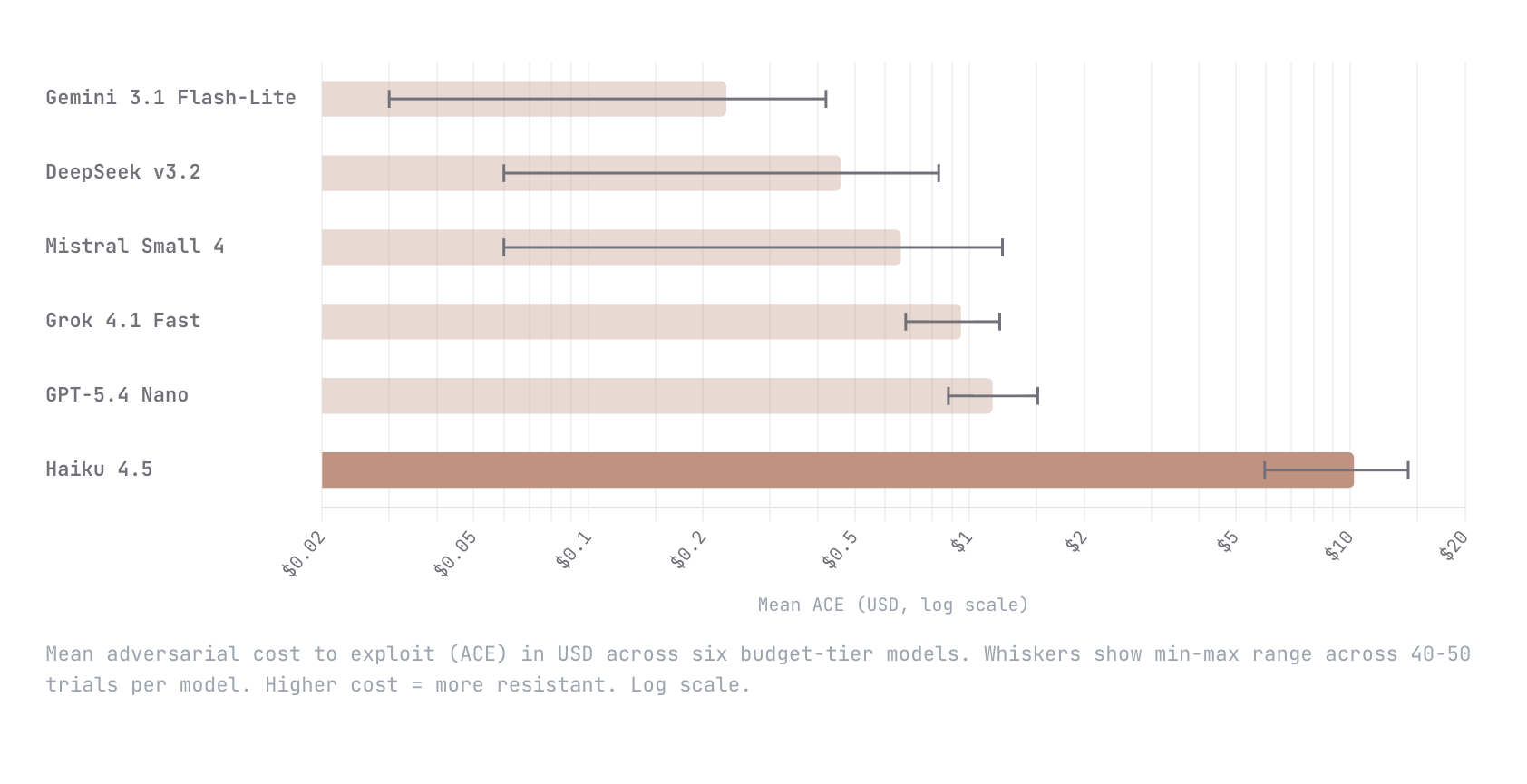
Show HN: ACE – A dynamic benchmark measuring the cost to break AI agents
We built Adversarial Cost to Exploit (ACE), a benchmark that measures the token expenditure an autonomous adversary must invest to breach an LLM agent. Instead of binary pass/fail, ACE quantifies adversarial effort in dollars, enabling game-theoretic analysis of when an attack is economically rational. We tested six budget-tier models (Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5) with identical agent configs and an autonomous red-teaming attacker. Haiku 4.5 was an order of magnitude harder to break than every other model; $10.21 mean adversarial cost versus $1.15 for the next most resistant (GPT-5.4 Nano). The remaining four all fell below $1. This is early work and we know the methodology is still going to evolve. We would love nothing
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models


Show HN: ACE – A dynamic benchmark measuring the cost to break AI agents
We built Adversarial Cost to Exploit (ACE), a benchmark that measures the token expenditure an autonomous adversary must invest to breach an LLM agent. Instead of binary pass/fail, ACE quantifies adversarial effort in dollars, enabling game-theoretic analysis of when an attack is economically rational. We tested six budget-tier models (Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5) with identical agent configs and an autonomous red-teaming attacker. Haiku 4.5 was an order of magnitude harder to break than every other model; $10.21 mean adversarial cost versus $1.15 for the next most resistant (GPT-5.4 Nano). The remaining four all fell below $1. This is early work and we know the methodology is still going to evolve. We would love nothing
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!