
Build a smart financial assistant with LlamaParse and Gemini 3.1
This blog post introduces a workflow for extracting high-quality data from complex, unstructured documents by combining LlamaParse with Gemini 3.1 models. It demonstrates an event-driven architecture that uses Gemini 3.1 Pro for agentic parsing of dense financial tables and Gemini 3.1 Flash for cost-effective summarization. By following the provided tutorial, developers can build a personal finance assistant capable of transforming messy brokerage statements into structured, human-readable insights.
MARCH 23, 2026
Extracting text from unstructured documents is a classic developer headache. For decades, traditional Optical Character Recognition (OCR) systems have struggled with complex layouts, often turning multi-column PDFs, embedded images, and nested tables into an unreadable mess of plain text.
Today, the multimodal capabilities of large language models (LLMs) finally make reliable document understanding possible.
LlamaParse bridges the gap between traditional OCR and vision-language agentic parsing. It delivers state-of-the-art text extraction across PDFs, presentations, and images.
In this post, you will learn how to use Gemini to power LlamaParse, extract high-quality text and tables from unstructured documents, and build an intelligent personal finance assistant. As a reminder, Gemini models may make mistakes and should not be relied upon for professional advice.
Why LlamaParse?
In many cases, LLMs can already perform this task effectively, however, when working with large document collections or highly variable formats, consistency and reliability can become more challenging.
Dedicated tools like LlamaParse complement LLM capabilities by introducing preprocessing steps and customizable parsing instructions, which help structure complex elements such as large tables or dense text. In general parsing benchmarks, this approach has shown around a 13–15% improvement compared to processing raw documents directly.
The use case: parsing brokerage statements
Brokerage statements represent the ultimate document parsing challenge. They contain dense financial jargon, complex nested tables, and dynamic layouts.
To help users understand their financial situation, you need a workflow that not only parses the file, but explicitly extracts the tables and explains the data through an LLM.
Because of these advanced reasoning and multimodal requirements, Gemini 3.1 Pro is the perfect fit as the underlying model. It balances a massive context window with native spatial layout comprehension.
The workflow operates in four stages:
- Ingest: You submit a PDF to the LlamaParse engine.
- Route: The engine parses the document and emits a ParsingDoneEvent.
- Extract: This event triggers two parallel tasks — text extraction and table extraction — that run concurrently to minimize latency.
- Synthesize: Once both extractions complete, Gemini generates a human-readable summary.
This two-model architecture is a deliberate design choice: Gemini 3.1 Pro handles the hard layout-comprehension during parsing, while Gemini 3 Flash handles the final summarization — optimizing for both accuracy and cost.
You can find the complete code for this tutorial in the LlamaParse x Gemini demo GitHub repository.
Setting up the environment
First, install the necessary Python packages for LlamaCloud, LlamaIndex workflows, and the Google GenAI SDK.
# with pip pip install llama-cloud-services llama-index-workflows pandas google-genai# with pip pip install llama-cloud-services llama-index-workflows pandas google-genaiwith uv
uv add llama-cloud-services llama-index-workflows pandas google-genai`
Shell
Copied
Next, export your API keys as environment variables. Get a Gemini API key from AI Studio, and a LlamaCloud API key from the console. Security Note: Never hardcode your API keys in your application source code.
export LLAMA_CLOUD_API_KEY="your_llama_cloud_key" export GEMINI_API_KEY="your_google_api_key"export LLAMA_CLOUD_API_KEY="your_llama_cloud_key" export GEMINI_API_KEY="your_google_api_key"Shell
Copied
Step 1: Create and use the parser
The first step in your workflow is parsing. You create a LlamaParse client backed by Gemini 3.1 Pro and define it in resources.py so you can inject it into your workflow as a resource:
def get_llama_parse() -> LlamaParse: return LlamaParse( api_key=os.getenv("LLAMA_CLOUD_API_KEY"), parse_mode="parse_page_with_agent", model="gemini-3.1-pro", result_type=ResultType.MD, )def get_llama_parse() -> LlamaParse: return LlamaParse( api_key=os.getenv("LLAMA_CLOUD_API_KEY"), parse_mode="parse_page_with_agent", model="gemini-3.1-pro", result_type=ResultType.MD, )Python
Copied
The parse_page_with_agent mode applies a layer of agentic iteration guided by Gemini to correct and format OCR results based on visual context.
In workflow.py, define the events, state, and the parsing step:
class BrokerageStatementWorkflow(Workflow): @step async def parse_file( self, ev: FileEvent, ctx: Context[WorkflowState], parser: Annotated[LlamaParse, Resource(get_llama_parse)] ) -> ParsingDoneEvent | OutputEvent: result = cast(ParsingJobResult, (await parser.aparse(file_path=ev.input_file))) async with ctx.store.edit_state() as state: state.parsing_job_result = result return ParsingDoneEvent()class BrokerageStatementWorkflow(Workflow): @step async def parse_file( self, ev: FileEvent, ctx: Context[WorkflowState], parser: Annotated[LlamaParse, Resource(get_llama_parse)] ) -> ParsingDoneEvent | OutputEvent: result = cast(ParsingJobResult, (await parser.aparse(file_path=ev.input_file))) async with ctx.store.edit_state() as state: state.parsing_job_result = result return ParsingDoneEvent()Python
Copied
Notice that you do not process parsing results immediately. Instead, you store them in the global WorkflowState so they are available for the extraction steps that follow.
Step 2: Extract the text and tables
To provide the LLM with the context required to explain the financial statement, you need to extract the full markdown text and the tabular data. Add the extraction steps to your BrokerageStatementWorkflow class (see the full implementation in workflow.py):
@step async def extract_text(self, ev: ParsingDoneEvent, ctx: Context[WorkflowState]) -> TextExtractionDoneEvent:@step async def extract_text(self, ev: ParsingDoneEvent, ctx: Context[WorkflowState]) -> TextExtractionDoneEvent:Extraction logic omitted for brevity. See repo.
@step async def extract_tables(self, ev: ParsingDoneEvent, ctx: Context[WorkflowState], ...) -> TablesExtractionDoneEvent:
Extraction logic omitted for brevity. See repo.`
Python
Copied
Because both steps listen for the same ParsingDoneEvent, LlamaIndex Workflows automatically executes them in parallel. This means your text and table extractions run concurrently — cutting overall pipeline latency and making the architecture naturally scalable as you add more extraction tasks.
Step 3: Generate the summary
With the data extracted, you can prompt Gemini 3.1 Pro to generate a summary in accessible, non-technical language.
Configure the LLM client and prompt template in resources.py. Here, you use Gemini 3 Flash for the final summarization, as it offers low latency and cost efficiency for text aggregation tasks.
The final synthesis step uses ctx.collect_events to wait for both extractions to complete before calling the Gemini API.
@step async def ask_llm( self, ev: TablesExtractionDoneEvent | TextExtractionDoneEvent, ctx: Context[WorkflowState], llm: Annotated[GenAIClient, Resource(get_llm)], template: Annotated[Template, Resource(get_prompt_template)] ) -> OutputEvent: if ctx.collect_events(ev, [TablesExtractionDoneEvent, TextExtractionDoneEvent]) is None: return None@step async def ask_llm( self, ev: TablesExtractionDoneEvent | TextExtractionDoneEvent, ctx: Context[WorkflowState], llm: Annotated[GenAIClient, Resource(get_llm)], template: Annotated[Template, Resource(get_prompt_template)] ) -> OutputEvent: if ctx.collect_events(ev, [TablesExtractionDoneEvent, TextExtractionDoneEvent]) is None: return NoneFull prompt and LLM call available in repo.`
Python
Copied
Running the workflow
To tie it all together, the main.py entry point creates and runs the workflow:
wf = BrokerageStatementWorkflow(timeout=600) result = await wf.run(start_event=FileEvent(input_file=input_file))wf = BrokerageStatementWorkflow(timeout=600) result = await wf.run(start_event=FileEvent(input_file=input_file))Python
Copied
To test the workflow, download a sample statement from the LlamaIndex datasets:
curl -L https://raw.githubusercontent.com/run-llama/llama-datasets/main/llama_agents/bank_statements/brokerage_statement.pdf > brokerage_statement.pdf
Shell
Copied
Run the workflow:
# Using pip python3 main.py brokerage_statement.pdf# Using pip python3 main.py brokerage_statement.pdfUsing uv
uv run run-workflow brokerage_statement.pdf`
Shell
Copied
You now have a fully functional personal finance assistant running in your terminal, capable of analyzing complex financial PDFs.
Next steps
AI pipelines are only as good as the data you feed them. By combining Gemini 3.1 Pro's multimodal reasoning with LlamaParse's agentic ingestion, you ensure your applications have the full, structured context they need — not just flattened text.
When you base your architecture on event-driven statefulness, like the parallel extractions demonstrated here, you build systems that are fast, scalable, and resilient. Double-check outputs before relying on them.
Ready to implement this in production? Explore LlamaParse and the Gemini API documentation to experiment with multimodal generation, and dive into the full code in the GitHub repository.
Previous
Next
Google Developers Blog
https://developers.googleblog.com/build-a-smart-financial-assistant-with-llamaparse-and-gemini-31/Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
geminillamamodel

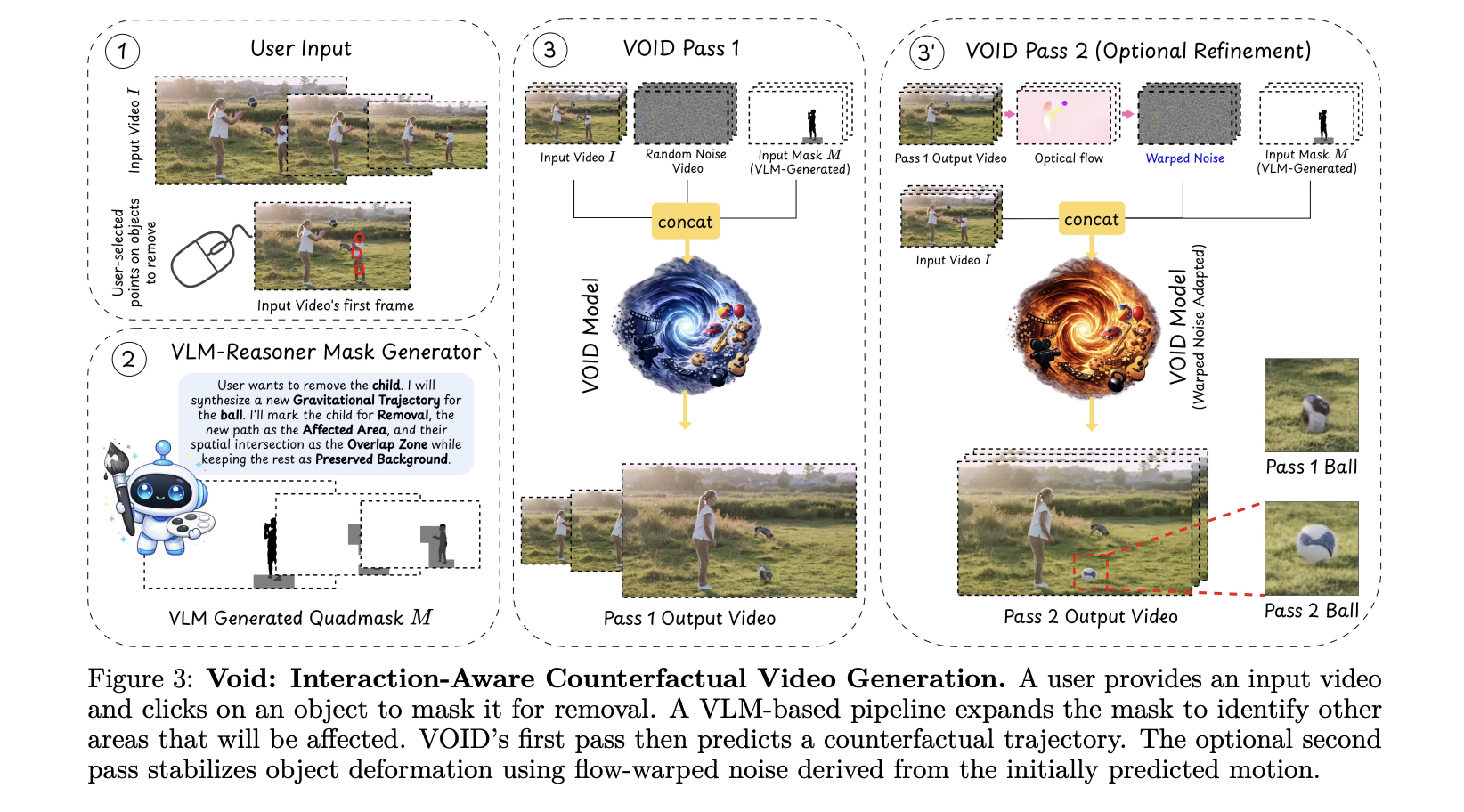
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like it was never there is brutally hard. Take out a person holding a guitar, and you re left with a floating instrument that defies gravity. Hollywood VFX teams spend weeks fixing exactly this kind of problem. [ ] The post Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All appeared first on MarkTechPost .

Sharing Two Open-Source Projects for Local AI & Secure LLM Access 🚀
Hey everyone! I’m finally jumping into the dev.to community. To kick things off, I wanted to share two tools I’ve been developing at the University of Jaén that tackle two common headaches in the AI space: running out of VRAM, and keeping your API chats truly private. 🦥 Quansloth: TurboQuant Local AI Server The Problem: Standard LLM inference hits a "Memory Wall" with long documents. As context grows, your GPU runs out of memory (OOM) and crashes. The Solution: Quansloth is a fully private, air-gapped AI server that brings elite KV cache compression to consumer hardware. By bridging a Gradio Python frontend with a highly optimized llama.cpp CUDA backend, it prevents GPU crashes and lets you run massive contexts on a budget. Key Features: 75% VRAM Savings: Based on Google's TurboQuant (ICL
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!