
Code Review Agent Benchmark
arXiv:2603.23448v2 Announce Type: replace-cross Abstract: Software engineering agents have shown significant promise in writing code. As AI agents permeate code writing, and generate huge volumes of code automatically -- the matter of code quality comes front and centre. As the automatically generated code gets integrated into huge code-bases -- the issue of code review and broadly quality assurance becomes important. In this paper, we take a fresh look at the problem and curate a code review dataset for AI agents to work with. Our dataset called c-CRAB (pronounced see-crab) can evaluate agent — Yuntong Zhang, Zhiyuan Pan, Imam Nur Bani Yusuf, Haifeng Ruan, Ridwan Shariffdeen, Abhik Roychoudhury
View PDF HTML (experimental)
Abstract:Software engineering agents have shown significant promise in writing code. As AI agents permeate code writing, and generate huge volumes of code automatically -- the matter of code quality comes front and centre. As the automatically generated code gets integrated into huge code-bases -- the issue of code review and broadly quality assurance becomes important. In this paper, we take a fresh look at the problem and curate a code review dataset for AI agents to work with. Our dataset called c-CRAB (pronounced see-crab) can evaluate agents for code review tasks. Specifically given a pull-request (which could be coming from code generation agents or humans), if a code review agent produces a review, our evaluation framework can asses the reviewing capability of the code review agents. Our evaluation framework is used to evaluate the state of the art today -- the open-source PR-agent, as well as commercial code review agents from Devin, Claude Code, and Codex. Our c-CRAB dataset is systematically constructed from human reviews -- given a human review of a pull request instance we generate corresponding tests to evaluate the code review agent generated reviews. Such a benchmark construction gives us several insights. Firstly, the existing review agents taken together can solve only around 40% of the c-CRAB tasks, indicating the potential to close this gap by future research. Secondly, we observe that the agent reviews often consider different aspects from the human reviews -- indicating the potential for human-agent collaboration for code review that could be deployed in future software teams. Last but not the least, the agent generated tests from our data-set act as a held out test-suite and hence quality gate for agent generated reviews. What this will mean for future collaboration of code generation agents, test generation agents and code review agents -- remains to be investigated.
Subjects:
Software Engineering (cs.SE); Artificial Intelligence (cs.AI)
Cite as: arXiv:2603.23448 [cs.SE]
(or arXiv:2603.23448v2 [cs.SE] for this version)
https://doi.org/10.48550/arXiv.2603.23448
arXiv-issued DOI via DataCite
Submission history
From: Yuntong Zhang [view email] [v1] Tue, 24 Mar 2026 17:19:32 UTC (420 KB) [v2] Mon, 30 Mar 2026 14:02:50 UTC (419 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
researchpaperarxiv

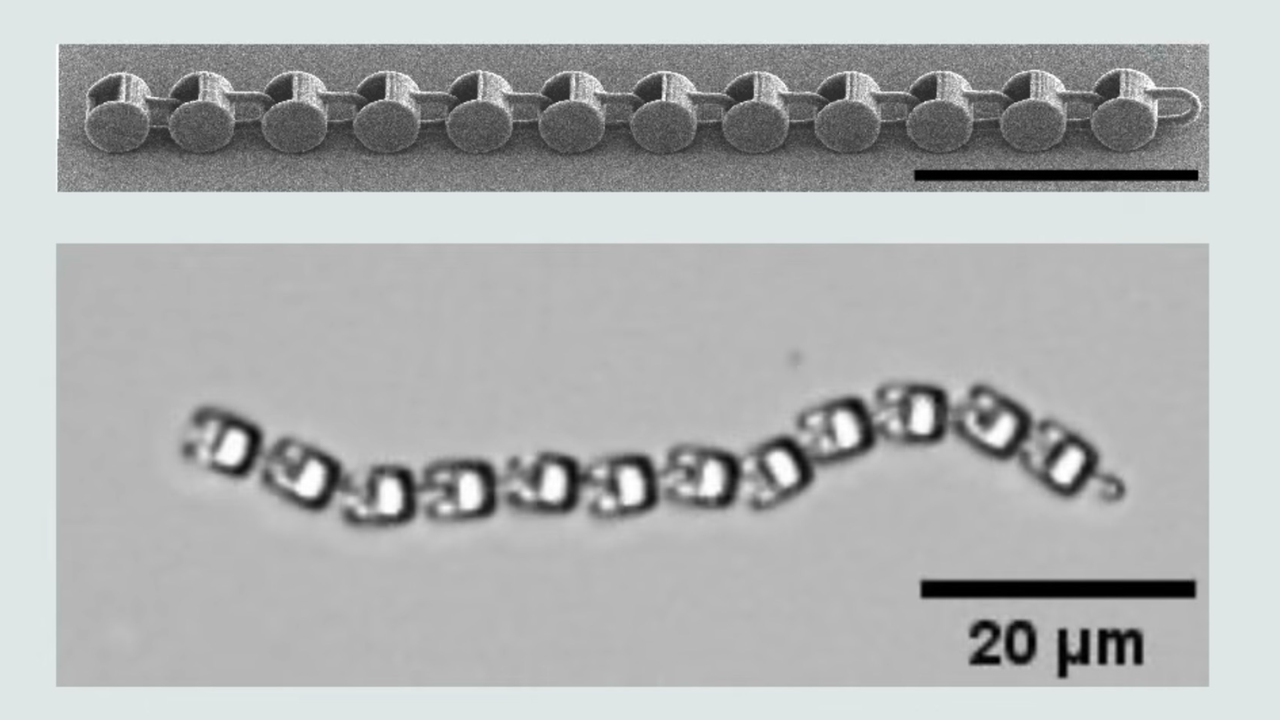
Researchers 3D print robot the size of a single-cell organism — devices move and navigate even without a ‘brain,’ uses their shape and the environment to get going
Researchers 3D print robot the size of a single-cell organism — devices move and navigate even without a ‘brain,’ uses their shape and the environment to get going
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Research Papers
Researchers 3D print robot the size of a single-cell organism — devices move and navigate even without a ‘brain,’ uses their shape and the environment to get going
Researchers 3D print robot the size of a single-cell organism — devices move and navigate even without a ‘brain,’ uses their shape and the environment to get going

Developing psychosocial phenotypes to understand engagement with digital health technologies for heart failure
npj Digital Medicine, Published online: 04 April 2026; doi:10.1038/s41746-026-02571-z Developing psychosocial phenotypes to understand engagement with digital health technologies for heart failure

Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!