AI companies are pivoting from creating gods to building products. Good.
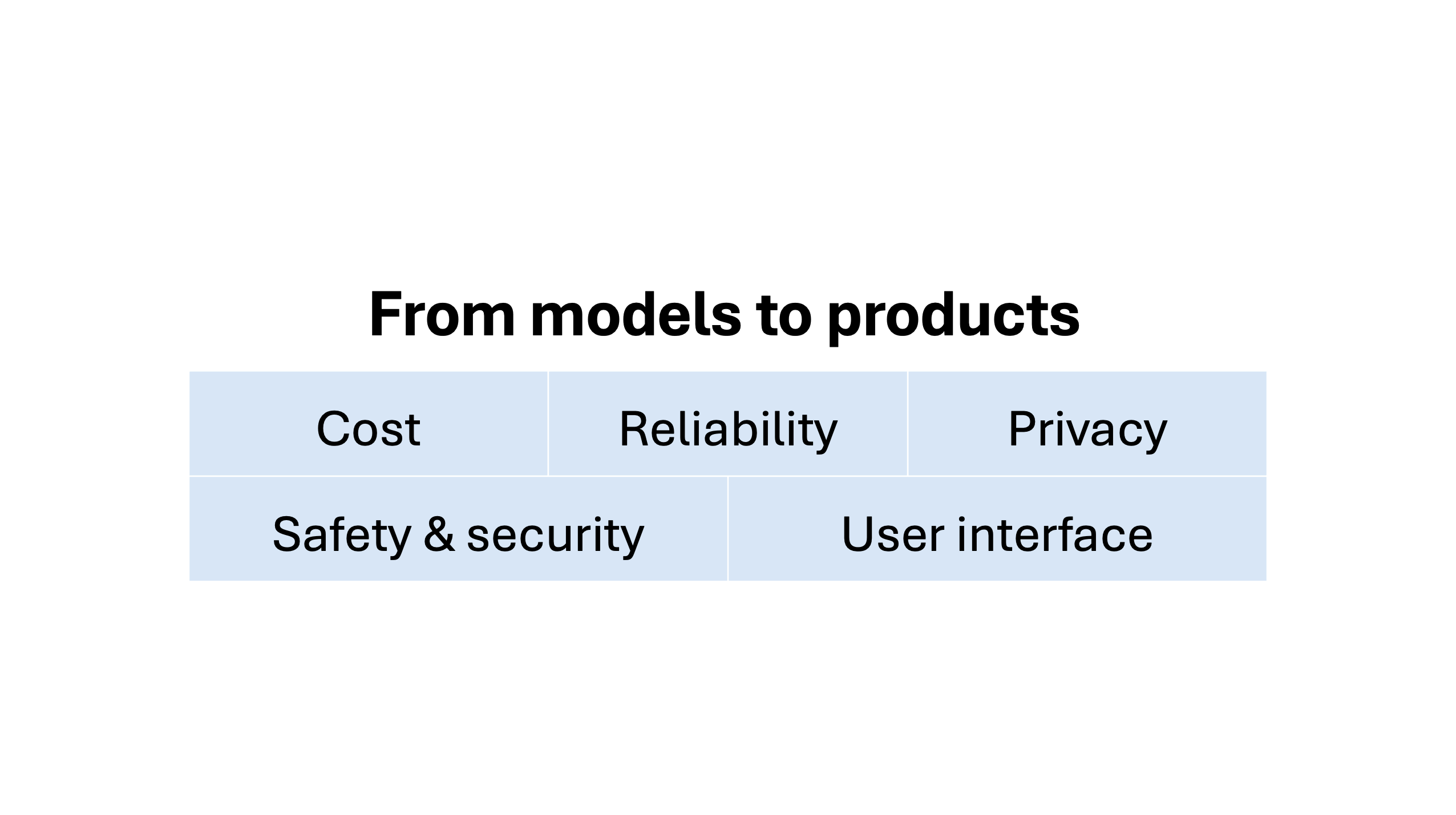
Turning models into products runs into five challenges
AI companies are collectively planning to spend a trillion dollars on hardware and data centers, but there’s been relatively little to show for it so far. This has led to a chorus of concerns that generative AI is a bubble. We won’t offer any predictions on what’s about to happen. But we think we have a solid diagnosis of how things got to this point in the first place.
In this post, we explain the mistakes that AI companies have made and how they have been trying to correct them. Then we will talk about five barriers they still have to overcome in order to make generative AI commercially successful enough to justify the investment.
When ChatGPT launched, people found a thousand unexpected uses for it. This got AI developers overexcited. They completely misunderstood the market, underestimating the huge gap between proofs of concept and reliable products. This misunderstanding led to two opposing but equally flawed approaches to commercializing LLMs.
OpenAI and Anthropic focused on building models and not worrying about products. For example, it took 6 months for OpenAI to bother to release a ChatGPT iOS app and 8 months for an Android app!
Google and Microsoft shoved AI into everything in a panicked race, without thinking about which products would actually benefit from AI and how they should be integrated.
Both groups of companies forgot the “make something people want” mantra. The generality of LLMs allowed developers to fool themselves into thinking that they were exempt from the need to find a product-market fit, as if prompting a model to perform a task is a replacement for carefully designed products or features.
OpenAI and Anthropic’s DIY approach meant that early adopters of LLMs disproportionately tended to be bad actors, since they are more invested in figuring out how to adapt new technologies for their purposes, whereas everyday users want easy-to-use products. This has contributed to a poor public perception of the technology.1
Meanwhile the AI-in-your-face approach by Microsoft and Google has led to features that are occasionally useful and more often annoying. It also led to many unforced errors due to inadequate testing like Microsoft's early Sydney chatbot and Google's Gemini image generator. This has also caused a backlash.
But companies are changing their ways. OpenAI seems to be transitioning from a research lab focused on a speculative future to something resembling a regular product company. If you take all the human-interest elements out of the OpenAI boardroom drama, it was fundamentally about the company's shift from creating gods to building products. Anthropic has been picking up many of the researchers and developers at OpenAI who cared more about artificial general intelligence and felt out of place at OpenAI, although Anthropic, too, has recognized the need to build products.
Google and Microsoft are slower to learn, but our guess is that Apple will force them to change. Last year Apple was seen as a laggard on AI, but it seems clear in retrospect that the slow and thoughtful approach that Apple showcased at WWDC, its developer conference, is more likely to resonate with users.2 Google seems to have put more thought into integrating AI in its upcoming Pixel phones and Android than it did into integrating it in search, but the phones aren’t out yet, so let’s see.
And then there’s Meta, whose vision is to use AI to create content and engagement on its ad-driven social media platforms. The societal implications of a world awash in AI-generated content are double-edged, but from a business perspective it makes sense.
There are five limitations of LLMs that developers need to tackle in order to make compelling AI-based consumer products.3 (We will discuss many of these in our upcoming online workshop on building useful and reliable AI agents on August 29.)
There are many applications where capability is not the barrier, cost is. Even in a simple chat application, cost concerns dictate how much history a bot can keep track of — processing the entire history for every response quickly gets prohibitively expensive as the conversation grows longer.
There has been rapid progress on cost — in the last 18 months, cost-for-equivalent-capability has dropped by a factor of over 100.4 As a result, companies are claiming that LLMs are, or will soon be, “too cheap to meter”. Well, we’ll believe it when they make the API free.
More seriously, the reason we think cost will continue to be a concern is that in many applications, cost improvements directly translate to accuracy improvements. That’s because repeatedly retrying a task tens, thousands, or even millions of times turns out to be a good way to improve the chances of success, given the randomness of LLMs. So the cheaper the model, the more retries we can make with a given budget. We quantified this in our recent paper on agents; since then, many other papers have made similar points.
That said, it is plausible that we’ll soon get to a point where in most applications, cost optimization isn’t a serious concern.
We see capability and reliability as somewhat orthogonal. If an AI system performs a task correctly 90% of the time, we can say that it is capable of performing the task but it cannot do so reliably. The techniques that get us to 90% are unlikely to get us to 100%.
With statistical learning based systems, perfect accuracy is intrinsically hard to achieve. If you think about the success stories of machine learning, like ad targeting or fraud detection or, more recently, weather forecasting, perfect accuracy isn’t the goal — as long as the system is better than the state of the art, it is useful. Even in medical diagnosis and other healthcare applications, we tolerate a lot of error.
But when developers put AI in consumer products, people expect it to behave like software, which means that it needs to work deterministically. If your AI travel agent books vacations to the correct destination only 90% of the time, it won’t be successful. As we’ve written before, reliability limitations partly explain the failures of recent AI-based gadgets.
AI developers have been slow to recognize this because as experts, we are used to conceptualizing AI as fundamentally different from traditional software. For example, the two of us are heavy users of chatbots and agents in our everyday work, and it has become almost automatic for us to work around the hallucinations and unreliability of these tools. A year ago, AI developers hoped or assumed that non-expert users would learn to adapt to AI, but it has gradually become clear that companies will have to adapt AI to user expectations instead, and make AI behave like traditional software.
Improving reliability is a research interest of our team at Princeton. For now, it’s fundamentally an open question whether it’s possible to build deterministic systems out of stochastic components (LLMs). Some companies have claimed to have solved reliability — for example, legal tech vendors have touted “hallucination-free” systems. But these claims were shown to be premature.
Historically, machine learning has often relied on sensitive data sources such browsing histories for ad targeting or medical records for health tech. In this sense, LLMs are a bit of an anomaly, since they are primarily trained on public sources such as web pages and books.5
But with AI assistants, privacy concerns have come roaring back. To build useful assistants, companies have to train systems on user interactions. For example, to be good at composing emails, it would be very helpful if models were trained on emails. Companies’ privacy policies are vague about this and it is not clear to what extent this is happening.6 Emails, documents, screenshots, etc. are potentially much more sensitive than chat interactions.
There is a distinct type of privacy concern relating to inference rather than training. For assistants to do useful things for us, they must have access to our personal data. For example, Microsoft announced a controversial feature that would involve taking screenshots of users’ PCs every few seconds, in order to give its CoPilot AI a memory of your activities. But there was an outcry and the company backtracked.
We caution against purely technical interpretations of privacy such as “the data never leaves the device.” Meredith Whittaker argues that on-device fraud detection normalizes always-on surveillance and that the infrastructure can be repurposed for more oppressive purposes. That said, technical innovations can definitely help.
There is a cluster of related concerns when it comes to safety and security: unintentional failures such as the biases in Gemini’s image generation; misuses of AI such as voice cloning or deepfakes; and hacks such as prompt injection that can leak users’ data or harm the user in other ways.
We think accidental failures are fixable. As for most types of misuses, our view is that there is no way to create a model that can’t be misused and so the defenses must primarily be located downstream. Of course, not everyone agrees, so companies will keep getting bad press for inevitable misuses, but they seem to have absorbed this as a cost of doing business.
Let’s talk about the third category — hacking. From what we can tell, it is the one that companies seem to be paying the least attention to. At least theoretically, catastrophic hacks are possible, such as AI worms that spread from user to user, tricking those users’ AI assistants into doing harmful things including creating more copies of the worm.
Although there have been plenty of proof-of-concept demonstrations and bug bounties that uncovered these vulnerabilities in deployed products, we haven't seen this type of attack in the wild. We aren’t sure if this is because of the low adoption of AI assistants, or because the clumsy defenses that companies have pulled together have proven sufficient, or something else. Time will tell.
In many applications, the unreliability of LLMs means that there will have to be some way for the user to intervene if the bot goes off track. In a chatbot, it can be as simple as regenerating an answer or showing multiple versions and letting the user pick. But in applications where errors can be costly, such as flight booking, ensuring adequate supervision is more tricky, and the system must avoid annoying the user with too many interruptions.
The problem is even harder with natural language interfaces where the user speaks to the assistant and the assistant speaks back. This is where a lot of the potential of generative AI lies. As just one example, AI that disappeared into your glasses and spoke to you when you needed it, without even being asked — such as by detecting that you were staring at a sign in a foreign language — would be a whole different experience than what we have today. But the constrained user interface leaves very little room for incorrect or unexpected behavior.
AI boosters often claim that due to the rapid pace of improvement in AI capabilities, we should see massive societal and economic effects soon. We are skeptical of the trend extrapolation and sloppy thinking that goes into those capability forecasts. More importantly, even if AI capability does improve rapidly, developers have to solve the challenges discussed above. These are sociotechnical and not purely technical, so progress will be slow. And even if those challenges are solved, organizations need to integrate AI into existing products and workflows and train people to use it productively while avoiding its pitfalls. We should expect this to happen on a timescale of a decade or more rather than a year or two.
Benedict Evans has written about the importance of building single-purpose software using general-purpose language models.
1
To be clear, we don't think that reducing access to state-of-the-art models will reduce misuse. But when it comes to LLMs, misuse is easier than legitimate uses (which require thought), so it isn't a surprise that misuses have been widespread.
2
The pace of AI adoption is relative. Even Apple's approach to integrating AI into its products has been criticized as too fast-paced.
3
These are about factors that matter to the user experience; we are setting aside environmental costs, training on copyrighted data, etc.
4
For example, GPT-3.5 (text-davinci-003) in the API cost $20 per million tokens, whereas gpt-4o-mini, which is more powerful, costs only 15 cents.
5
To be clear, just because the data sources are public doesn’t mean there are no privacy concerns.
6
For example, Google says “we use publicly available information to help train Google’s AI models”. Elsewhere it says that it may use private data such as emails to provide services, maintain and improve services, personalize services, and develop new services. One approach that is consistent with these disclosures is that only public data is used for pre-training of models like Gemini, but private data is used to fine-tune those models to create, say, an email auto-response bot. Anthropic is the one exception we know of. It says: “We do not train our generative models on user-submitted data unless a user gives us explicit permission to do so. To date we have not used any customer or user-submitted data to train our generative models.” This commitment to privacy is admirable, though we predict that it will put the company at a disadvantage if it more fully embraces building products.
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modelproduct
From Direct Classification to Agentic Routing: When to Use Local Models vs Azure AI
<p>In many enterprise workflows, classification sounds simple.</p> <p>An email arrives.<br><br> A ticket is created.<br><br> A request needs to be routed.</p> <p>At first glance, it feels like a straightforward model problem:</p> <ul> <li>classify the input</li> <li>assign a category</li> <li>trigger the next step</li> </ul> <p>But in practice, enterprise classification is rarely just about model accuracy.</p> <p>It is also about:</p> <ul> <li>latency</li> <li>cost</li> <li>governance</li> <li>data sensitivity</li> <li>operational fit</li> <li>fallback behavior</li> </ul> <p>That is where the architecture becomes more important than the model itself.</p> <p>In this post, I want to share a practical way to think about classification systems in enterprise environments:</p> <ul> <li>when <str
Single-Cluster Duality View 🃏
<p>In DynamoDB, a <em><a href="https://aws.amazon.com/blogs/database/single-table-vs-multi-table-design-in-amazon-dynamodb/" rel="noopener noreferrer">single-table design</a></em> stores one-to-many relationships in a single physical block while still following relational-like normal form decomposition. In MongoDB, the <em><a href="https://www.mongodb.com/docs/manual/data-modeling/design-patterns/single-collection/" rel="noopener noreferrer">Single Collection Pattern</a></em> unnests relationships from a single document, but goes against the general recommendation as it sacrifices one of MongoDB’s key advantages—keeping a document in a single block. In Oracle Database and MySQL, JSON-relational <a href="https://oracle-base.com/articles/23/json-relational-duality-views-23" rel="noopener nor

Accessible web testing with Cypress and wick-a11y
<p>I spent a couple of hours building a custom logging callback for cypress-axe. It formatted violations into a console table and registered Cypress tasks in the config file. It worked. Then I installed wick-a11y and got better output with zero custom code.</p> <p>This is the second article in my accessibility testing series. The first one covered Cypress with cypress-axe, and you can find it here:<br> </p> <div class="ltag__link--embedded"> <div class="crayons-story "> <a href="https://dev.to/cypress/accessible-web-testing-with-cypress-and-axe-core-1af9" class="crayons-story__hidden-navigation-link">Accessible web testing with Cypress and Axe Core</a> <div class="crayons-story__body crayons-story__body-full_post"> <div class="crayons-story__top"> <div class="crayons-story__meta"> <div cla
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

AI 週報:2026/3/27–4/1 Anthropic 一週三震、Arm 首顆自研晶片、Oracle 裁三萬人押注 AI
<blockquote> <p><strong>本週一句話摘要:</strong> Anthropic 成為全場焦點——但聚光燈有一半來自意外。</p> </blockquote> <h2> 一、最重要事件:Anthropic 的三重震盪 </h2> <p>本週沒有一家公司比 Anthropic 更頻繁登上頭條——但三次曝光中有兩次並非計畫內。</p> <h3> 1. IPO 計畫曝光(3/27) </h3> <p>Bloomberg 報導,Anthropic 正考慮<strong>最快十月掛牌上市</strong>,募資規模可能超過 <strong>600 億美元</strong>。消息指出公司已與 Goldman Sachs、JPMorgan、Morgan Stanley 進行初步接洽。</p> <p>背景脈絡:</p> <div class="table-wrapper-paragraph"><table> <thead> <tr> <th>指標</th> <th>數字</th> </tr> </thead> <tbody> <tr> <td>二月融資輪估值</td> <td>3,800 億美元</td> </tr> <tr> <td>付費訂閱成長</td> <td>2026 年以來翻倍以上</td> </tr> <tr> <td>企業客戶首次採購勝率</td> <td>約 70%(vs. OpenAI)</td> </tr> <tr> <td>每日新增免費用戶</td> <td>超過 100 萬人</td> </tr> </tbody> </table></div> <p>這不只是一場 IPO——這是 AI 產業從「誰的模型更強」轉向「誰先成為上市公司」的訊號。Anthropic 與 OpenAI 同時在準備 2026 年上市,資本市場正在為 AI 雙雄的對決定價。

New build
<table> <tr><td> <a href="https://www.reddit.com/r/LocalLLaMA/comments/1s95cpa/new_build/"> <img src="https://preview.redd.it/6gcwubqi5hsg1.jpeg?width=640&crop=smart&auto=webp&s=dcc11e379b3473a61e23b0d2d398400393fef9b4" alt="New build" title="New build" /> </a> </td><td> <!-- SC_OFF --><div class="md"><p>Seasonic 1600w titanium power supply</p> <p>Supermicro X13SAE-F</p> <p>Intel i9-13900k</p> <p>4x 32GB micron ECC udimms</p> <p>3x intel 660p 2TB m2 ssd</p> <p>2x micron 9300 15.36TB u2 ssd (not pictured)</p> <p>2x RTX 6000 Blackwell max-q</p> <p>Due to lack of pci lanes gpus are running at x8 pci 5.0</p> <p>I may upgrade to a better cpu to handle both cards at x16 once ddr5 ram prices go down.</p> <p>Would upgrading cpu and increasing ram channels matter really that much?</p> <
1-bit llms on device?!
<!-- SC_OFF --><div class="md"><p>everyone's talking about the claude code stuff (rightfully so) but <a href="https://github.com/PrismML-Eng/Bonsai-demo/blob/main/1-bit-bonsai-8b-whitepaper.pdf">this paper</a> came out today, and the claims are pretty wild:</p> <ul> <li>1-bit 8b param model that fits in 1.15 gb of memory ...</li> <li>competitive with llama3 8B and other full-precision 8B models on benchmarks</li> <li>runs at 440 tok/s on a 4090, 136 tok/s on an M4 Pro</li> <li>they got it running on an iphone at ~40 tok/s</li> <li>4-5x more energy efficient</li> </ul> <p>also it's up on <a href="https://huggingface.co/prism-ml/Bonsai-8B-gguf">hugging face</a>! i haven't played around with it yet, but curious to know what people think about this one. caltech spinout from a famous professor

Me: avoiding r/LocalLLaMA on April Fools’ Day so I don’t fall for fake model releases.
<table> <tr><td> <a href="https://www.reddit.com/r/LocalLLaMA/comments/1s973u2/me_avoiding_rlocalllama_on_april_fools_day_so_i/"> <img src="https://preview.redd.it/km4rhb1djhsg1.gif?width=320&crop=smart&s=5f34e0e2ec7deee2ee9daa7eb56bc4b0d0ccbaf6" alt="Me: avoiding r/LocalLLaMA on April Fools’ Day so I don’t fall for fake model releases." title="Me: avoiding r/LocalLLaMA on April Fools’ Day so I don’t fall for fake model releases." /> </a> </td><td> <!-- SC_OFF --><div class="md"><p>See y’all April 2nd. </p> </div><!-- SC_ON -->   submitted by   <a href="https://www.reddit.com/user/Porespellar"> /u/Porespellar </a> <br/> <span><a href="https://i.redd.it/km4rhb1djhsg1.gif">[link]</a></span>   <span><a href="https://www.reddit.com/r/LocalLLaMA/comments/1s973u2/me_avoiding_
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!